Google must face $17 billion UK ad tech lawsuit
Written on June 5, 2024 at 6:44 pm, by admin

A UK court has ruled that Google must face a £13.6 billion ($17 billion) lawsuit alleging it wields too much power over the online advertising market.
Why we care. The case could have far-reaching implications for the digital ad industry. Will this lead to advertisers spending less on Google?
Driving the news. The Competition Appeal Tribunal in London rejected Google’s attempt to dismiss the case, allowing it to proceed to trial.
The lawsuit, brought by Ad Tech Collective Action LLP, claims Google’s anticompetitive practices have cost UK online publishers money.
It alleges Google engages in “self-preferencing,” promoting its own products over rivals.
Google’s response. The tech giant calls the lawsuit “speculative and opportunistic,” vowing to “oppose it vigorously and on the facts.”
Context. This is just one of many regulatory challenges Google faces:
- Multiple probes, including the U.S. vs. Google antitrust trial
- Billions in fines from the EU for anticompetitive behaviour
What’s next? No trial date is set yet. The case has already taken 18 months to reach this stage.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
OpenAI’s growing list of partnerships
Written on June 5, 2024 at 6:44 pm, by admin

OpenAI has announced 30 significant deals with tech and media brands to date, including three in the past week with Vox Media, the Atlantic and the World Association of Newspapers and News Publishers.
Now there’s an easy way to keep track of them all: the OpenAI Partnerships List from Originality.AI.
Why we care. These partnerships will undoubtedly lead to greater discoverability in OpenAI products – think: featured content and citations (links) in ChatGPT. As we’ve seen from the Google-Reddit deal, brands with partnerships tend to get favorable placement, which is good news for those with such deals but bad news if you’re competing against them.
The content deals. Brands that sign on with OpenAI will be discoverable in OpenAI’s products, including ChatGPT. OpenAI will also use the content from these brands to train its systems.
The 30 deals. So far, OpenAI has partnered with:
- American Journalism Project
- AP (Associated Press)
- Arizona State University
- The Atlantic
- Atlassian
- Axel Springer
- Bain & Company
- BuzzFeed
- Consensus
- Dotdash Meredith
- Figure
- Financial Times
- G42
- GitHub
- Icelandic Government
- Le Monde
- Microsoft
- Neo Accelerator
- News Corp
- Opera Press
- Prisa Media
- Salesforce
- Sanofi & Formation Bio
- Shutterstock
- Stack Overflow
- Stripe
- Upwork
- Vox Media
- World Association of Newspapers and News Publishers (WAN-IFRA)
ChatGPT Search. While rumors of a ChatGPT Search product have quieted for now, we have already seen ChatGPT more prominently feature links in its answers. And we know OpenAI CEO is interested in creating Search that is much different than Google.
- These deals could have even greater implications later because these brands will have an unfair advantage should ChatGPT Search become a viable Google alternative.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Perplexity Pages showing in Google AI Overviews, featured snippets
Written on June 4, 2024 at 3:43 pm, by admin

AI-powered search engine Perplexity introduced a new product – Perplexity Pages – to select free and paid users on May 30. Content from these Pages has started appearing in Google’s AI Overviews and featured snippets.
What are Perplexity Pages. Perplexity called it a way to share your knowledge with the world, via in-depth articles, detailed reports or informative guides. You can even select the audience type (beginner, advanced, anyone) when you have AI generate your content. You can also add sections, videos, images and more.
As TechCrunch explained it further:
- “All these pages are publishable and also searchable through Google. You can share the link to these pages with other users. They can ask follow-up questions on the topic as well. What’s more, users can also turn their existing conversation threads into pages with the click of a button.”
Pages in Google. These pages are being indexed by Google and included as citations in AI Overviews and appearing in featured snippets.
Here are examples showing this, shared on X by Kristi Hines:
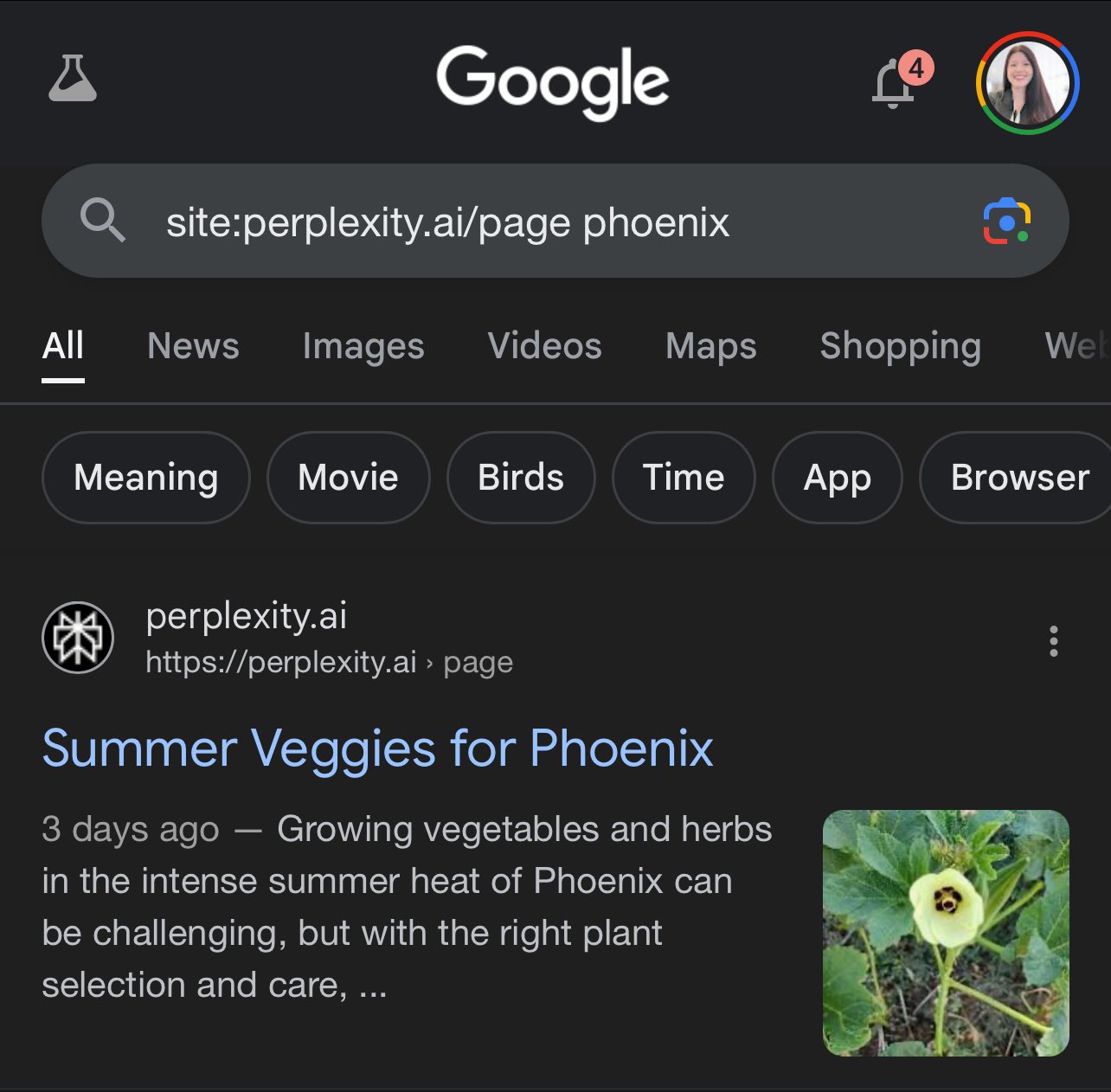
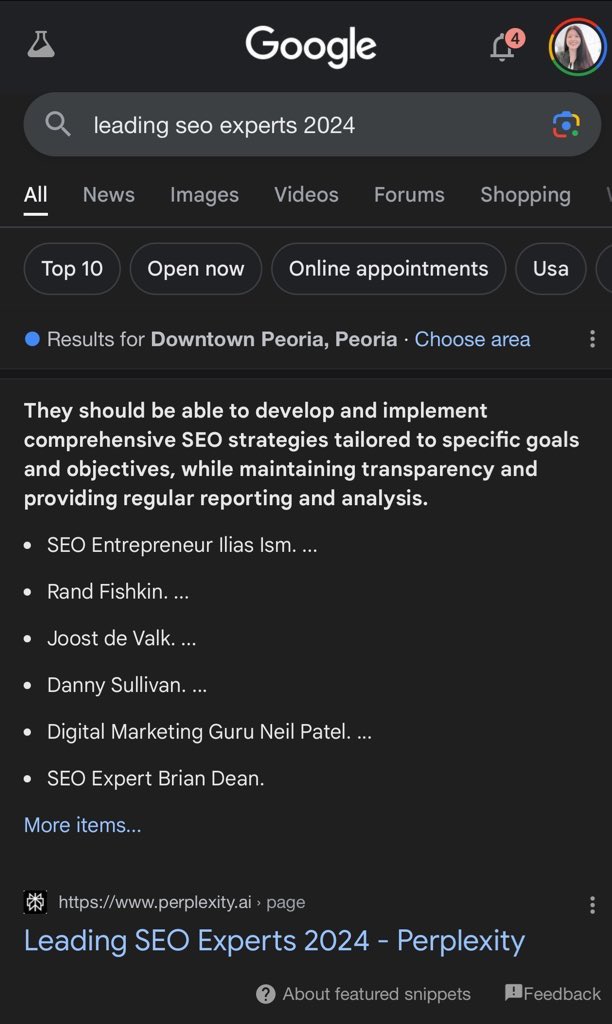
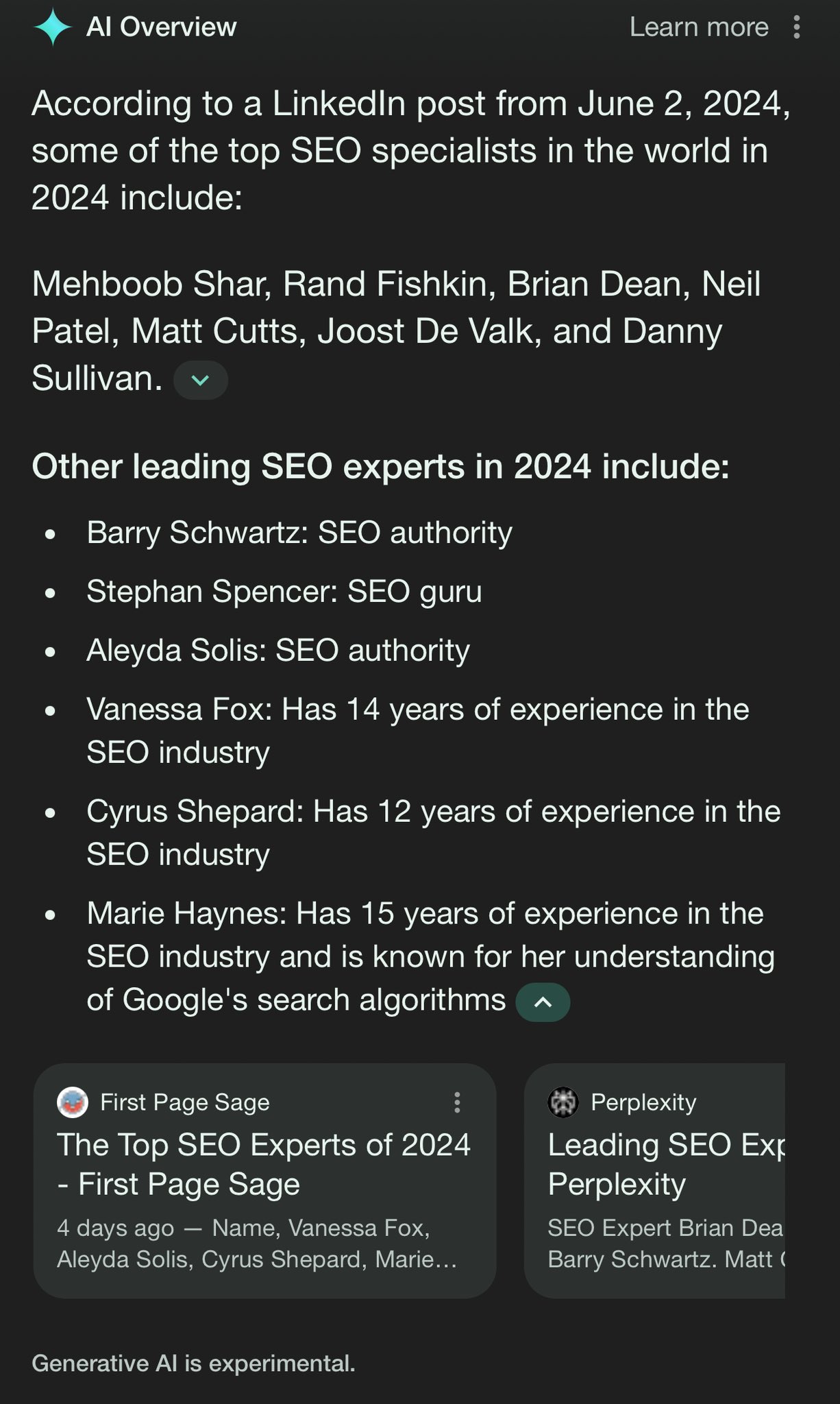
Spam? This definitely seems like a case of one search engine spamming another search engine. Or, as Ryan Jones put it on X, “An AI overview of an AI overview in search results pages in my search results page.”
Aside from that absurdity, Perplexity Pages are ripe for abuse by those who will probably try to use it to hack their way into AI Overviews.
A big question is how Google will handle this new AI-generated content in its Search results long-term. This tactic could be short-lived, as pointed out in an X thread, started by Glenn Gabe. From the thread:
- Shared searches used to be indexed in Google, but the March 2024 core update hammered these pages.
- This could be comparable to LinkedIn Collaborative Articles, which surged briefly before a huge drop.
Perplexity’s announcement. Introducing Perplexity Pages
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Google Search fixes issues with Site names not appearing for internal pages
Written on June 4, 2024 at 3:43 pm, by admin

Google has fixed an issue where some internal pages would not show the proper Site name in the Google Search results. This has been an issue since at least December 2023 and is now resolved.
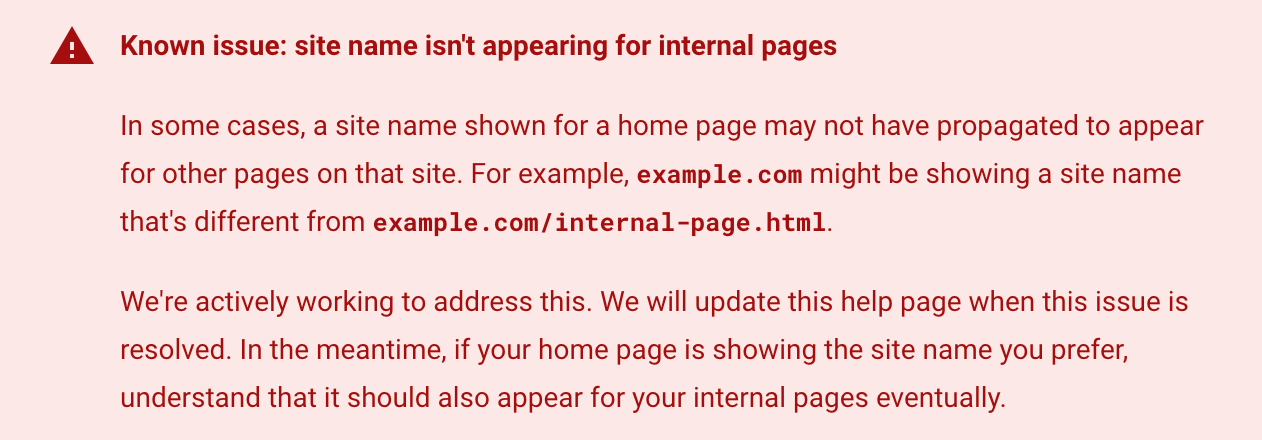
What changed. Google updated its site names documentation today to remove the “known issue” section that read:
In some cases, a site name shown for a home page may not have propagated to appear for other pages on that site. For example, example.com might be showing a site name that’s different from example.com/internal-page.html.
We’re actively working to address this. We will update this help page when this issue is resolved. In the meantime, if your home page is showing the site name you prefer, understand that it should also appear for your internal pages eventually.
Here is a screenshot of that section:
Still see the issue. You may still see this issue on some sites, that is because that it can take time for Google to reprocess all of the pages on a specific site. Google wrote in the updated documentation, “Not seeing your preferred site name for internal pages? If your home page is already showing your preferred site name, remember to also allow time for Google to recrawl and process your internal pages.”
Site names still may have other lingering issues, as we covered here.
Site names timeline. Here is the timeline Google posted of the evolution of site names since it launched in October:
- October 2022: Site names for the domain level were introduced for mobile search results for English, French, German and Japanese.
- April 2023 (I have this as March): Site names were added for desktop for the same set of languages.
- May 2023: Site names are supported on the subdomain level for the same set of languages and on mobile search results only.
Controlling site names. Google back in October 2022 explained that Google Search uses a number of ways to identify the site name for the search result. But if you want, you can use structured data on your home page to communicate to Google what the site name should be for your site. Google has specific documentation on this new Site name structured data available over here.
Why we care. If you still see issues with some of your internal pages not having the correct site name in Google Search, you may want to try to get Google to recrawl and reprocess the page. Using the Google URL Inspection tool may help trigger that process.
Otherwise, Google will update the pages over time, as it naturally reprocesses the pages.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Google’s documentation leak: 12 big takeaways for link builders and digital PRs
Written on June 4, 2024 at 3:43 pm, by admin

Lots of insights and opinions have already been shared about last week’s leak of Google’s Content API Warehouse documentation, including the fantastic write-ups from:
- Rand Fishkin
- Mike King (on the iPullRank site and here on Search Engine Land)
- Andrew Ansley
But what can link builders and digital PRs learn from the documents?
Since news of the leak broke, Liv Day, Digitaloft’s SEO Lead, and I have spent a lot of time investigating what the documentation tells us about links.
We went into our analysis of the documents trying to gain insights around a few key questions:
- Do links still matter?
- Are some links more likely to contribute to SEO success than others?
- How does Google define link spam?
To be clear, the leaked documentation doesn’t contain confirmed ranking factors. It contains information on more than 2,500 modules and over 14,000 attributes.
We don’t know how these are weighted, which are used in production and which could exist for experimental purposes.
But that doesn’t mean the insights we gain from these aren’t useful. So long as we consider any findings to be things that Google could be rewarding or demoting rather than things they are, we can use them to form the basis of our own tests and come to our own conclusions about what is or isn’t a ranking factor.
Below are the things we found in the documents that link builders and digital PRs should pay close attention to. They’re based on my own interpretation of the documentation, alongside my 15 years of experience as an SEO.
1. Google is probably ignoring links that don’t come from a relevant source
Relevancy has been the hottest topic in digital PR for a long time, and something that’s never been easy to measure. After all, what does relevancy really mean?
Does Google ignore links that don’t come from within relevant content?
The leaked documents definitely suggest that this is the case.
We see a clear anchorMismatchDemotion referenced in the CompressedQualitySignals module:

While we have little extra context, what we can infer from this is that there is the ability to demote (ignore) links when there is a mismatch. We can assume this to mean a mismatch between the source and target pages, or the source page and target domain.
What could the mismatch be, other than relevancy?
Especially when we consider that, in the same module, we also see an attribute of topicEmbeddingsVersionedData.

Topic embeddings are commonly used in natural language processing (NLP) as a way of understanding the semantic meaning of topics within a document. This, in the context of the documentation, means webpages.
We also see a webrefEntities attribute referenced in the PerDocData module.

What’s this? It’s the entities associated with a document.
We can’t be sure exactly how Google is measuring relevancy, but we can be pretty certain that the anchorMismatchDemotion involves ignoring links that don’t come from relevant sources.
The takeaway?
Relevancy should be the biggest focus when earning links, prioritized over pretty much any other metric or measure.
2. Locally relevant links (from the same country) are probably more valuable than ones from other countries
The AnchorsAnchorSource module, which gives us an insight into what Google stores about the source page of links, suggests that local relevance could contribute to the link’s value.
Within this document is an attribute called localCountryCodes, which stores the countries to which the page is local and/or the most relevant.

It’s long been debated in digital PR whether links coming from sites in other countries and languages are valuable. This gives us some indication as to the answer.
First and foremost, you should prioritize earning links from sites that are locally relevant. And if we think about why Google might weigh these links stronger, it makes total sense.
Locally relevant links (don’t confuse this with local publications that often secure links and coverage from digital PR; here we’re talking about country-level) are more likely to increase brand awareness, result in sales and be more accurate endorsements.
However, I don’t believe links from other locales are harmful. More than those where the country-level relevancy matches are weighted more strongly.
3. Google has a sitewide authority score, despite claiming they don’t calculate an authority measure like DA or DR
Maybe the biggest surprise to most SEOs reading the documentation is that Google has a “site authority” score, despite stating time and time again that they have no measure that’s like Moz’s Domain Authority (DA) or Ahrefs’ Domain Rating (DR).
In 2020, Google’s John Mueller stated:
- “Just to be clear, Google doesn’t use Domain Authority *at all* when it comes to Search crawling, indexing, or ranking.”
But later that year, did hint at a sitewide measure, saying about Domain Authority:
- “I don’t know if I’d call it authority like that, but we do have some metrics that are more on a site level, some metrics that are more on a page level, and some of those site-wide level metrics might kind of map into similar things.”
Clear as day, in the leaked documents, we see a SiteAuthority score.

To caveat this, though, we don’t know that this is even remotely in line with DA or DR. It’s also likely why Google has typically answered questions in the way they have about this topic.
Moz’s DA and Ahrefs’ DR are link-based scores based on the quality and quantity of links.
I’m doubtful that Google’s siteAuthority is solely link-based though, given that feels closer to PageRank. I’d be more inclined to suggest that this is some form of calculated score based on page-level quality scores, including click data and other NavBoost signals.
The likelihood is that, despite having a similar naming convention, this doesn’t align with DA and DR, especially given that we see this referenced in the CompressedQualitySignals module, not a link-specific one.
4. Links from within newer pages are probably more valuable than those on older ones
One interesting finding is that links from newer pages look to be weighted more strongly than those coming from older content, in some cases.
We see reference to sourceType in the context of anchors (links), where the quality of a link’s source page is recorded in correlation to the page’s index tier.

What stands out here, though, is the reference to newly published content (freshdocs) being a special case and considered to be the same as “high quality” links.
We can clearly see that the source type of a link can be used as an importance indicator, which suggests that this relates to how links are weighted.
What we must consider, though, is that a link can be defined as being “high quality” without being a fresh page, it’s just that these are considered the same quality.
To me, this backs up the importance of consistently earning links and explains why SEOs continue to recommend that link building (in whatever form, that’s not what we’re discussing here) needs consistent resources allocated. It needs to be an “always-on” activity.
5. The more Google trusts a site’s homepage, the more valuable links from that site probably are
We see a reference within the documentation (again, in the AnchorsAnchorSource module) to an attribute called homePageInfo, which suggests that Google could be tagging link sources as not trusted, partially trusted or fully trusted.

What this does define is that this attribute relates to instances when the source page is a website’s homepage, with a not_homepage value being assigned to other pages.
So, what could this mean?
It suggests that Google could be using some definition of “trust” of a website’s homepage within the algorithms. How? We’re not sure.
My interpretation: internal pages are likely to inherit the homepage’s trustworthiness.
To be clear: we don’t know how Google defines whether a page is fully trusted, not trusted or partially trusted.
But it would make sense that internal pages inherit a homepage’s trustworthiness and that this is used, to some degree, in the weighting of links and that links from fully trusted sites are more valuable than those from not trusted ones.
6. Google specifically tags links that come from high-quality news sites
Interestingly, we’ve discovered that Google is storing additional information about a link when it is identified as coming from a “newsy, high quality” site.

Does this mean that links from news sites (for example, The New York Times, The Guardian or the BBC) are more valuable than those from other types of site?
We don’t know for sure.
But when looking at this – alongside the fact that these types of sites are typically the most authoritative and trusted publications online, as well as those that would historically had a toolbar PageRank of 9 or 10 – it does make you think.
What’s for sure, though, is that leveraging digital PR as a tactic to earn links from news publications is undoubtedly incredibly valuable. This finding just confirms that.
7. Links coming from seed sites, or those links to from these, are probably the most valuable links you could earn
Seed sites and link distance ranking is a topic that doesn’t get talked about anywhere near as often as it should, in my opinion.
It’s nothing new, though. In fact, it’s something that the late Bill Slawski wrote about in 2010, 2015 and 2018.
The leaked Google documentation suggests that PageRank in its original form has long been deprecated and replaced by PageRank-NearestSeeds, referenced by the fact it defines this as the production PageRank value to be used. This is perhaps one of the things that the documentation is the clearest on.

If you’re unfamiliar with seed sites, the good news is that it isn’t a massively complex concept to understand.
Slawski’s articles on this topic are probably the best reference point for this:
“The patent provides 2 examples [of seed sites]: The Google Directory (It was still around when the patent was first filed) and the New York Times. We are also told: ‘Seed sets need to be reliable, diverse enough to cover a wide range of fields of public interests & well connected to other sites. In addition, they should have large numbers of useful outgoing links to facilitate identifying other useful & high-quality pages, acting as ‘hubs’ on the web.’
“Under the PageRank patent, ranking scores are given to pages based upon how far away they might be from those seed sets and based upon other features of those pages.”– Bill Slawski, PageRank Update (2018)
8. Google is probably using ‘trusted sources’ to calculate whether a link is spammy
When looking at the IndexingDocjoinerAnchorSpamInfo module, one that we can assume relates to how spammy links are processed, we see references to “trusted sources.”

It looks like Google can calculate the probability of link spam based on the number of trusted sources linking to a page.
We don’t know what constitutes a “trusted source,” but when looked at holistically alongside our other findings, we can assume that this could be based on the “homepage” trust.
Can links from trusted sources effectively dilute spammy links?
It’s definitely possible.
9. Google is probably identifying negative SEO attacks and ignoring these links by measuring link velocity
The SEO community has been divided over whether negative SEO attacks are a problem for some time. Google is adamant they’re able to identify such attacks, while plenty of SEOs have claimed their site was negatively impacted by this issue.
The documentation gives us some insight into how Google attempts to identify such attacks, including attributes that consider:
- The timeframe over which spammy links have been picked up.
- The average daily rate of spam discovered.
- When a spike started.

It’s possible that this also considers links intended to manipulate Google’s ranking systems, but the reference to “the anchor spam spike” suggests that this is the mechanism for identifying significant volumes, something we know is a common issue faced with negative SEO attacks.
There are likely other factors at play in determining how links picked up during a spike are ignored, but we can at least start to piece together the puzzle of how Google is trying to prevent such attacks from having a negative impact on sites.
10. Link-based penalties or adjustments can likely apply either to some or all of the links pointing to a page
It seems that Google has the ability to apply link spam penalties or ignore links on a link-by-link or all-links basis.

This could mean that, given one or more unconfirmed signals, Google can define whether to ignore all links pointing to a page or just some of them.
Does this mean that, in cases of excessive link spam pointing to a page, Google can opt to ignore all links, including those that would generally be considered high quality?
We can’t be sure. But if this is the case, it could mean that spammy links are not the only ones ignored when they are detected.
Could this negate the impact of all links to a page? It’s definitely a possibility.
11. Toxic links are a thing, despite Google saying they aren’t
Just last month, Mueller stated (again) that toxic links are a made-up concept:
- “The concept of toxic links is made up by SEO tools so that you pay them regularly.”
In the documentation, though, we see reference given to “BadBackLinks.”

The information given here suggests that a page can be penalized for having “bad” backlinks.
While we don’t know what form this takes or how close this is to the toxic link scores given by SEO tools, we’ve got plenty of evidence to suggest that there is at least a boolean (typically true or false values) measure of whether a page has bad links pointing to it.
My guess is that this works in conjunction with the link spam demotions I talked about above, but we don’t know for sure.
12. The content surrounding a link gives context alongside the anchor text
SEOs have long leveraged the anchor text of links as a way to give contextual signals of the target page, and Google’s Search Central documentation on link best practices confirms that “this text tells people and Google something about the page you’re linking to.”
But last week’s leaked documents indicate that it’s not just anchor text that’s used to understand the context of a link. The content surrounding the link is likely also used.



The documentation references context2, fullLeftContext, and fullRightContext, which are the terms near the link.
This suggests that there’s more than the anchor text of a link being used to determine the relevancy of a link. On one hand, it could simply be used as a way to remove ambiguity, but on the other, it could be contributing to the weighting.
This feeds into the general consensus that links from within relevant content are weighted far more strongly than those within content that’s not.
Key learnings & takeaways for link builders and digital PRs
Do links still matter?
I’d certainly say so.
There’s an awful lot of evidence here to suggest that links are still significant ranking signals (despite us not knowing what is and isn’t a ranking signal from this leak), but that it’s not just about links in general.
Links that Google rewards or does not ignore are more likely to positively influence organic visibility and rankings.
Maybe the biggest takeaway from the documentation is that relevancy matters a lot. It is likely that Google ignores links that don’t come from relevant pages, making this a priority measure of success for link builders and digital PRs alike.
But beyond this, we’ve gained a deeper understanding of how Google potentially values links and the things that could be weighted more strongly than others.
Should these findings change the way you approach link building or digital PR?
That depends on the tactics you’re using.
If you’re still using outdated tactics to earn lower-quality links, then I’d say yes.
But if your link acquisition tactics are based on earning links with PR tactics from high-quality press publications, the main thing is to make sure you’re pitching relevant stories, rather than assuming that any link from a high authority publication will be rewarded.
For many of us, not much will change. But it’s a concrete confirmation that the tactics we’re relying on are the best fit, and the reason behind why we see PR-earned links having such a positive impact on organic search success.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Cut through inbox clutter with personalized, high-impact email by Edna Chavira
Written on June 4, 2024 at 3:43 pm, by admin

It’s harder than ever to capture your audience’s attention in an increasingly crowded inbox. With email volumes on the rise and click-through rates declining, creating personalized, engaging content that resonates with your audience is more important than ever.
That’s where the power of CDP-ESP integration comes in. By leveraging the combined strength of your customer data platform (CDP) and email service provider (ESP), you can create targeted, high-impact emails that drive results.
MarTech’s upcoming webinar, “Turn Your Customer Insights into Personalized, High-Impact Email,” will show you how integrating your CDP and ESP can help you overcome these challenges and take your email marketing to the next level. Register now!
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Instagram tests unskippable video ads in main feed
Written on June 3, 2024 at 12:42 pm, by admin

Instagram is experimenting with a new ad format that prevents users from scrolling until they view a video ad in their main feed.
Why it matters. The move could significantly boost ad exposure for brands but risks alienating users who find forced viewing intrusive.
How it works.
- New in-feed ads display with a timer.
- Users can’t scroll past until timer runs down.
- Essentially “un-skippable” like some YouTube ads.
Why we care. On one hand, this feature is a great opportunity for advertisers to get their ads in front of an audience that are used to seeing ads. But could it come at a risk of losing customers who will find their scrolling experience significantly disrupted?
The big picture. With half of users’ feeds now AI-recommended content from unfollowed profiles, Instagram sees an opportunity to blend in more ads without seeming overly disruptive.
Ad blockers. YouTube’s unskippable ads are often cited as a top reason people use ad blockers, suggesting forced viewing is deeply unpopular.
Between the lines. Instagram’s shift to Reels-heavy, algorithm-driven feeds may be paving the way for more aggressive ad strategies.
What they’re saying. A Meta spokesperson told TechCrunch:
- “We’re always testing formats that can drive value for advertisers. As we test and learn, we will provide updates should this test result in any formal product changes.”
The other side. Users are not thrilled. Photographer Dan Levy shared an example, sparking backlash in comments.

Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Google won’t index sites that do not work on mobile devices after July 5
Written on June 3, 2024 at 12:42 pm, by admin

We thought Google’s mobile-first indexing initiative, which started in 2016, was completed last October. But it won’t really be fully done until after July 5.
- “The small set of sites we’ve still been crawling with desktop Googlebot will be crawled with mobile Googlebot after July 5, 2024,” John Mueller from Google wrote on the Google blog.
Mueller explained:
- “The largest part of the web is already being crawled like this, and there is no change in crawling for these sites.” However, “after July 5, 2024, we’ll crawl and index these sites with only Googlebot Smartphone.”
So if your site is not accessible using a mobile device, then Google “will no longer” index it and thus rank it.
Mobile accessibility is required for Google indexing. Yes, Mueller wrote, “If your site’s content is not accessible at all with a mobile device, it will no longer be indexable.”
This is a long time coming. Google has finally drawn a line in the sand for sites that simply do not render on mobile.
This doesn’t mean Google won’t index your site if it isn’t mobile-friendly. What Google is saying is that if your site simply does not render or load on mobile devices, then Google won’t index it.
If you have a desktop template only, it is fine, assuming the desktop version loads on a mobile device.
Some desktop crawling to continue. Google said that Google still sometimes uses the Googlebot Desktop crawler for product listings and for Google for Jobs. This means you may still see Googlebot Desktop in your server logs and reporting tools.
Why we care. For most of you, this probably won’t be an issue. But if someone hires you to do some SEO on their site and their site does not load on your Android phone or iPhone, then it may also not be crawled and indexed by Google after July 5. Your goal will be to ensure the site is accessible on mobile devices, and to test it using the Google Search Console URL Inspection tool, to ensure it is rendered.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
An SEO’s guide to redirects
Written on June 3, 2024 at 12:42 pm, by admin

Redirects are a way of moving a webpage visitor from an old address to a new one without further action from them. Each webpage has a unique reference, a URL, to enable browsers to request the correct information be returned.
If a browser requests a page that has a redirect on it, it will be instructed to go to a different address. This means that the content on the original page is no longer available to request, and the browser must visit the new page to request the content there instead.
Essentially, redirects are instructions given to browsers or bots that the page they are looking for can no longer be reached and they must go to a different one instead.
Types of redirects
A website can indicate that a resource is no longer available at the previous address in several ways.
Permanent and temporary
When identifying that a redirect has been placed on a URL, search engines must decide whether to begin serving the new URL instead of the original in the search results.
Google claims it determines whether the redirect will be a permanent addition to the URL or just a temporary change in the location of the content.
If Google determines that the redirect is only temporary, it will likely continue to show the original URL in the search results. If it determines that the redirect is permanent, the new URL will begin to appear in the search results.
Meta refresh
A meta refresh redirect is a client-side redirect. This means that when a visitor to a site encounters a meta redirect, it will be their browser that identifies the need to go to a different page (unlike server-side redirects, where the server instructs the browser to go to a different page).
Meta refreshes can happen instantly or with a delay. A delayed meta refresh often accompanies a pop-up message like “you will be redirected in 5 seconds”.
Google claims it treats instant meta refreshes as “permanent” redirects, and delayed meta refreshes as “temporary” redirects.
JavaScript redirect
A redirect that uses JavaScript to take users from one page to another is also an example of a client-side redirect. Google warns website managers to only use JavaScript redirects if they can’t use server-side redirects or meta-refresh redirects.
Essentially, search engines will need to render the page before picking up the JavaScript redirect. This can mean there may be instances where the redirect is missed.
Server-side redirects
By far, the safest method for redirecting URLs is server-side redirects.
This requires access to the website’s server configuration, which is why meta refreshes are sometimes preferred. If you can access your server’s config files, then you will have several options available.
The key differences in these status codes are whether they indicate the redirect is permanent or temporary and whether the request method of POST (used to send data to a server) or GET (used to request data from a server) can be changed.
For a more comprehensive overview of POST and GET and why they matter for different applications, see the W3schools explanation.
Permanent redirects
- 301 (moved permanently): A redirect that returns a HTTP status code of “301” indicates that the resource found at the original URL has permanently moved to the new one. It will not revert to the old URL and it allows the original request method to change from POST to GET.
- 308 (permanent redirect): A 308 server response code is similar to 301 in that it indicates that the resource found at the original URL has permanently moved to the new one. However, the key difference between the 308 and the 301 is that it recommends maintaining the original request method of POST or GET.
Temporary redirects
- 302 – found (temporarily displaced): A 302 server code indicates that the move from one URL to another is only temporary. It is likely the redirect will be removed at some point in the near future. As with the 301 redirect, browsers can use a different request method from the original (POST or GET).
- 307 (temporary redirect): A 307 server code also indicates that a redirect is temporary, but as with a 308 redirect it recommends retaining the request method of the original URL.
Why use redirects
There are several good reasons to use redirects. Just like you might send out change-of-address cards when moving house (well, back in the early 2000s anyway, I’m not sure how you kids do it now), URL redirects help ensure that important visitors don’t get lost.
Human website users
A redirect means that when accessing content on your site a human visitor is taken automatically to the more relevant page.
For example, a visitor may have bookmarked your URL in the past. They then click on the bookmark without realizing the URL has changed. Without the redirect, they may end up on a page with a 404 error code and no way of knowing how to get to the content they are after.
A redirect means you do not have to rely on visitors working out how to navigate to the new URL. Instead, they are automatically taken to the correct page. This is much better for user experience.
Search engines
Similar to human users, when a search engine bot hits a redirect, it is taken to the new URL.
Instead of leaving them on a 404 error page, it can identify the equivalent URL straightaway, negating the need for the search bot to try to identify where, if anywhere, that original URL’s content might now be housed.
Demonstrating equivalence
Search engines will use redirects to determine if they should continue displaying the original URL in the search results.
If there is no redirect from an old, defunct URL to the new one, then the search engines will likely just de-index the old URL as it has no value as a 404 page. With a redirect in place, however, the search engine can directly link the new URL to the old one.
- If it is redirected permanently, the search engine will likely begin to display the new URL in the search results.
- If it is a temporary redirect, they may continue to display the old one. Google and other search engines may pass some of the ranking signals from the old URL to the new one due to the redirect.
This only happens if they believe the new page to be the equivalent of the old one in terms of value to searchers.
There are instances where this will not be the case, however, usually because the redirects have been implemented incorrectly. More on that later.
Typical SEO use cases for redirects
There are some very common reasons why a website owner might want to implement redirects to help both users and search engines find content. Importantly for SEO, redirects can allow the new page to retain some of the ranking power of the old one.
Vanity URLs
Vanity URLs are often used to help people remember URLs. For example, a TV advert might tell viewers to visit www.example-competition.com to enter their competition.
This URL might redirect to www.example.com/competitions/tv-ad-2024, which is far harder for viewers to remember and enter correctly. Using a vanity URL like this means website owners can use short URLs that are easy to remember and spell without having to set up the content outside of their current website structure.
URL rewrites
There may be instances when a URL needs to be edited once it’s already live.
For example, perhaps a product name has changed, a spelling mistake has been noticed, or a date in the URL needs to be updated. In these cases, a redirect from the old URL to the new one will ensure visitors and search bots can easily find the new address.
Moving content
Restructuring your website might necessitate redirects.
For example, you may be merging subfolders or moving content from one subdomain to another. This would be a great time to use redirects to ensure that content is easily accessible.
Moving domains
Website migrations, like moving from one domain address to another, are classic uses of redirects. These tend to be done en masse, often with every URL in the site requiring a redirect.
This can happen in internationalization, like moving a website from a .co.uk ccTLD to a .com address. It can also be necessitated through a company rebrand or the acquisition of another website and a desire to merge it with the existing one.
There may even be a need to split a website into separate domains. All of these cases would be good candidates for redirects.
HTTP to HTTPS
Not as common now the internet has largely woken up to the need for security is the migration from HTTP to HTTPS.
You still might need to switch a site from an insecure protocol (HTTP) to a secure one (HTTPS) in some situations. This will likely require redirects across the entire website.
Dig deeper: What is technical SEO?
Redirect problems to avoid
The main consideration when implementing redirects is which type to use.
In general, server-side redirects are generally safest to use. However, the choice between permanent and temporary redirects depends on your specific situation.
There are more potential pitfalls to be aware of.
Loops
Redirect loops happen when two redirects directly contradict each other. For example, URL A is redirected to URL B; however, URL B has a redirect pointing to URL A. This makes it unclear which page is supposed to be visited.
Search engines won’t be able to determine which page is meant to be canonical and human visitors will not be able to access either page.
If a redirect loop is present on a site, you will encounter a message like the one below when you try to access one of the pages in the loop:
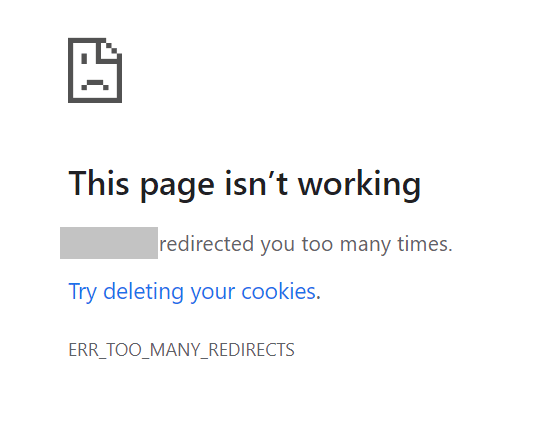
To fix this error, remove the redirects causing the loop and point them to the correct pages.
Chains
A redirect chain is a series of pages that redirect from one to another. For example, URL A redirects to URL B, which redirects to URL C, which redirects to URL D. This isn’t too much of an issue unless the chain gets too big.
URL chains can start to affect load speed. John Mueller, Search Advocate at Google, has also stated in the past that:
- “The only thing I’d watch out for is that you have less than 5 hops for URLs that are frequently crawled. With multiple hops, the main effect is that it’s a bit slower for users. Search engines just follow the redirect chain (for Google: up to 5 hops in the chain per crawl attempt).”
Soft 404s
Another problem that can arise from using redirects incorrectly is that search engines may not consider the redirect to be valid for the purposes of rankings.
For example, if Page A redirects to Page B but the two are not similar in content, the search engines may not pass any of the value of Page A to Page B. This can be reported as a “soft 404” in Google Search Console.
This typically happens when a webpage (e.g., a product page) is deleted and the URL is redirected to the homepage.
Anyone clicking on the product page from search results wouldn’t find the product information they were expecting if they landed on the homepage.
The signals and value of the original page won’t necessarily be passed to the homepage if it doesn’t match the user intent of searchers.
Ignoring previous redirects
It can be a mistake not to consider previously implemented redirects. Without checking to see what redirects are already active on the site, you may run the risk of creating loops or chains.
Frequent changes
Another reason for planning redirects in advance is to limit the need to frequently change them. It is important from an internal productivity perspective, especially if you involve other teams in their implementation.
Most crucially, though, is that you may find the search engines struggle to keep up with frequent changes, especially if you incorrectly suggest the redirect is permanent by using a 301 or 308 status code.
Good practice for redirects
It is helpful when considering any activity involving redirects to do the following to prevent problems down the road.
Create a redirect map
A redirect map is a simple plan showing which URLs should redirect and their destinations. It can be as simple as a spreadsheet with a column of “from” URLs and “to” URLs.
This way, you have a clear visual of what redirects will be implemented and you can identify any issues or conflicts beforehand.
Dig deeper: How to speed up site migrations with AI-powered redirect mapping
Assess existing redirects
If you keep a running redirect map, look back at previous redirects to see if your new ones will impact them at all.
For example, would you create a redirect chain or loop by adding new redirects to a page that already is redirected from another? This will also help you see if you have moved a page to a new URL several times over a short period of time.
If you do not have a map of previous redirects, you may be able to pull redirects from your server configuration files (or at least ask someone with access to it if they can!)
If you do not have access to the server configuration files either, or your redirects are implemented client-side, you can try the following techniques:
- Run your site through a crawling tool: Crawling tools mimic search bots in that they follow links and other signals on a website to discover all its pages. Many will also report back on the status code or if a meta refresh is detected on the URLs they find. Screaming Frog has a guide for detecting redirects using its tool.
- Use a plug-in: There are many browser plugins that will show if a page you are visiting has a redirect. They don’t tend to let you identify site-wide redirects, but they can be handy for spot-checking a page.
- Use Chrome Developer Tools: Another way, which just requires a Chrome browser, is to visit the page you are checking and use Chrome Developer Tools to identify if there is a redirect on it. You simply go to the Network panel to see what the response codes are for each element of the page. For more details, have a look at this guide by Aleyda Solis.
Google Search Console
The Coverage tab in Google Search Console lists errors found by Google that may prevent indexing.
Here, you may see examples of pages that have redirect errors. These are explained in further detail in Google’s Search Console Help section on Indexing reasons.
Alternatives to redirects
There are some occasions when redirects might not be possible at all. This tends to be when there is a limit to what can be accomplished through a CMS or with internal resources.
In these instances, alternatives could be considered. However, they may not achieve exactly what you would want from a redirect.
Canonical tags
To help rank a new page over the old one, you might need to use a canonical tag if redirects are not possible.
For example, you may have two identical URLs: Page A and Page B. Page B is new, but you want that to be what users find when they search with relevant search terms in Google. You do not want Page A to be served as a search result anymore.
Typically, you would just add a redirect from Page A to Page B so users could not access Page A from the SERPs. If you cannot add redirects, you can use a canonical tag to indicate to search engines that Page B should be served instead of Page A.
If URL A has been replaced by URL B and they both have identical content, Google may trust your canonical tag if all other signals also point to Page B being the new canonical version of the two.
Crypto redirects
A crypto redirect isn’t really a redirect at all. It’s actually a link on the page you would want to have redirected, directing users to the new page. Essentially it acts as a signpost.
For example, a call to action like, “This page has moved. Find it at its new location.” with the text linking to the content’s new URL.
Crypto redirects require users to carry out an action and will not work as a redirect for search engines, but if you are really struggling to implement a redirect and a change of address for content has occurred, this may be your only option to link one page to the other.
Conclusion
Redirects are useful tools for informing users and search engines that content has moved location. They help search engines understand the relevance of a new page to the old one while removing the requirement for users to locate the new content.
- Used properly, redirects can aid usability and search rankings.
- Used incorrectly, they can lead to problems with parsing, indexing and serving your website’s content.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
How to extract GBP review insights to boost local SEO visibility
Written on June 3, 2024 at 12:42 pm, by admin

Since the inception of local business listings, companies have explored various methods to acquire more customer reviews. These reviews provide valuable insights into consumer sentiment, common pain points, and areas for improvement.
While many businesses use paid tools to analyze review data, there are cost-effective methods to extract similar insights, particularly for smaller businesses with limited budgets.
This article:
- Explores how to extract entities from your Google Business Profile (GBP) listings and competitor listings using Pleper’s API service.
- Examines the impact of entities mentioned in reviews on local search visibility, specifically in the Google local 3-pack results.
- Covers ethical techniques to promote revenue-driving entities through review solicitation efforts while adhering to Google’s guidelines.
Analyzing GBP reviews for business insights
Companies like Yext, Reputation, and Birdeye can analyze top entities mentioned in reviews and offer insight into the sentiment around each of these. However, they can also command quite a large price tag.
Investing in these tools is essential for businesses managing numerous listings across multiple platforms. However, extracting insights from competitor listings remains costly. Monitoring competitor listings for review insights is often seen as an unjustifiable expense.
Smaller businesses can manage listings cost-effectively by assigning an internal marketing employee, but extracting valuable insights from reviews without using tools is more challenging.
Dig deeper: How to turn your Google Business Profile into a revenue-generating channel
How to extract business insights from GBP listings
Luckily, there is a much more cost-effective method to collect entities from GBP reviews using Pleper’s API service.
Collect place IDs for listing
For small batches, using Google’s Place ID demo works well for collecting Place IDs for your business’ listings and local competitor listings.
I’ve found that the following formula works well for searching for these listings: {business name}, {business address}.
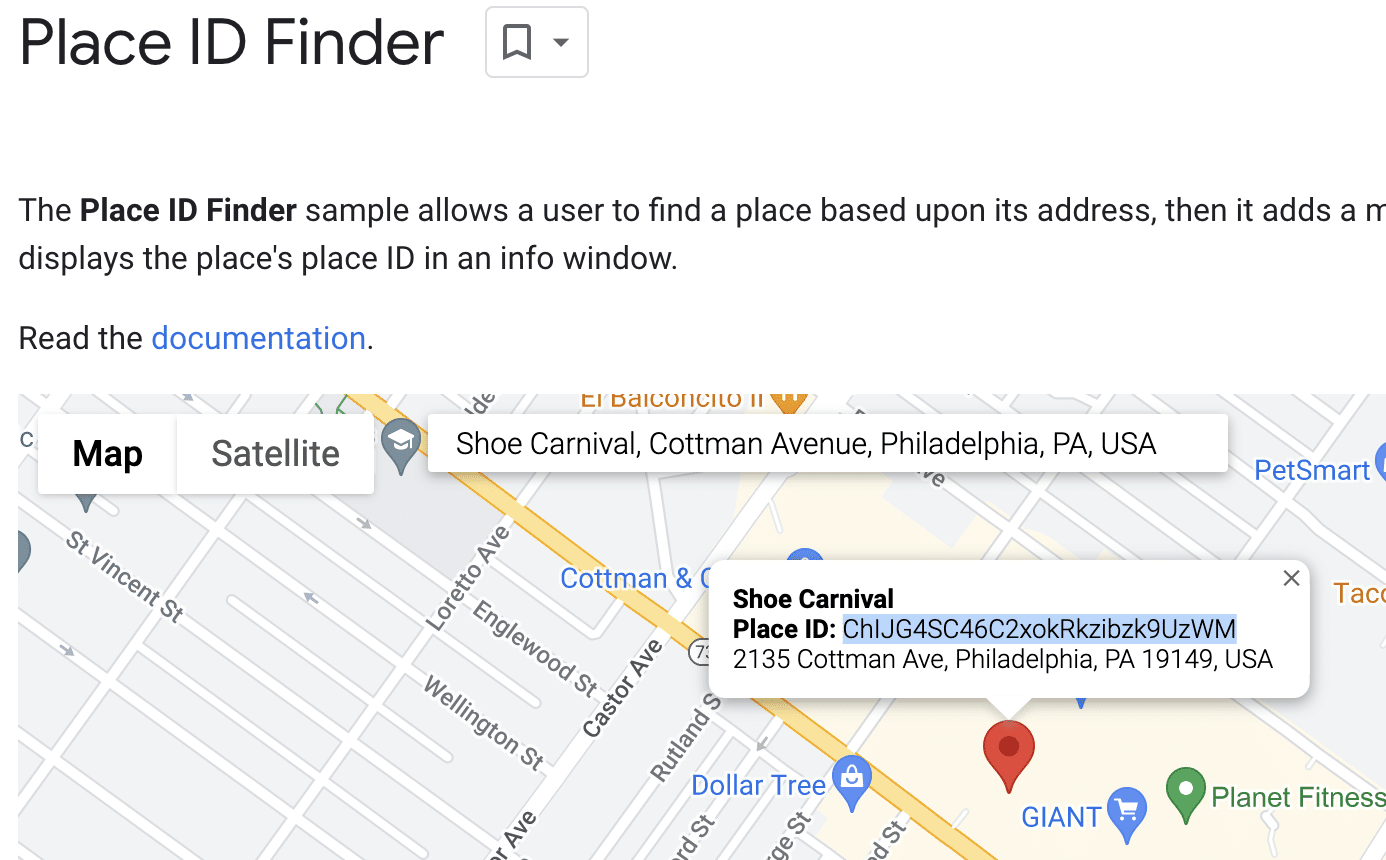
For larger batches, I recommend using Google’s Place ID API. Using the above formula as the search query, Place IDs can be quickly and efficiently collected.
Use Pleper’s API to collect information on each listing
After each listing’s Place ID has been collected, use Pleper’s Scrape API to retrieve the listing information. Once the data has been retrieved, use a parsing script to extract review topics and assign a value to each topic based on sentiment.
Here is an example script that will do just that:
import pandas as pd
def extract_review_topics(data):
topics_list = []
sentiment_map = {
'positive': 1,
'neutral': 0,
'negative': -1
}
for entry in data['results']['google/by-profile/information']:
if 'results' in entry and 'review_topics' in entry['results']:
for topic in entry['results']['review_topics']:
topic_details = {
'Business Name': entry['results'].get('name', 'N/A'),
'Address': entry['results'].get('address', 'N/A'),
'Place ID': entry['payload']['profile_url'],
'Topic': topic.get('topic', 'N/A'),
'Count': topic.get('count', 0),
'Sentiment': sentiment_map.get(topic.get('sentiment', 'neutral'), 0)
}
topics_list.append(topic_details)
return topics_list
topics_data = extract_review_topics(batch_result)
df = pd.DataFrame(topics_data)
print(df)Now that the data has been properly retrieved from Pleper and parsed into a pandas dataframe, matplotlib can be used to create a word cloud like the one below:
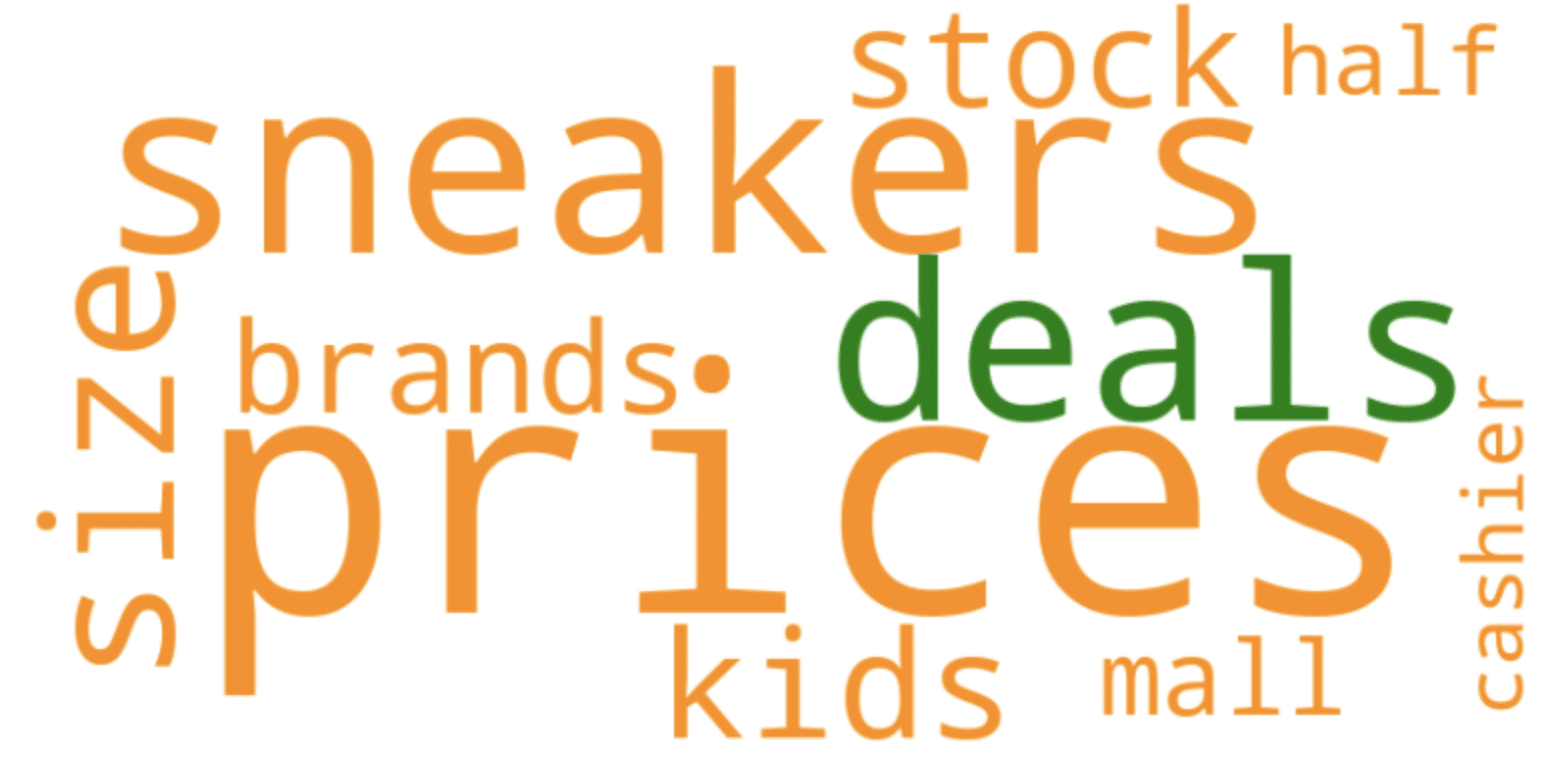
Word clouds can be created for individual listings or aggregated data on all of a brand’s listings. Comparing word clouds from your own business listings to those of competitors can lead to truly valuable insights.
The impact of entities on local 3-pack results
Entities have been highlighted in reviews for some time now; however, I haven’t seen many SEOs attempt to promote revenue-generating entities in review solicitation.
When possible, entities mentioned in a query are highlighted within the local 3-pack via the listings reviews. Typically, this occurs on long-tail queries, where more context is provided to Google on what the searcher is looking for.
To better understand the impact of entities within reviews, let’s analyze the results of two queries:
Sporting stores near me

Sporting store with baseball near me
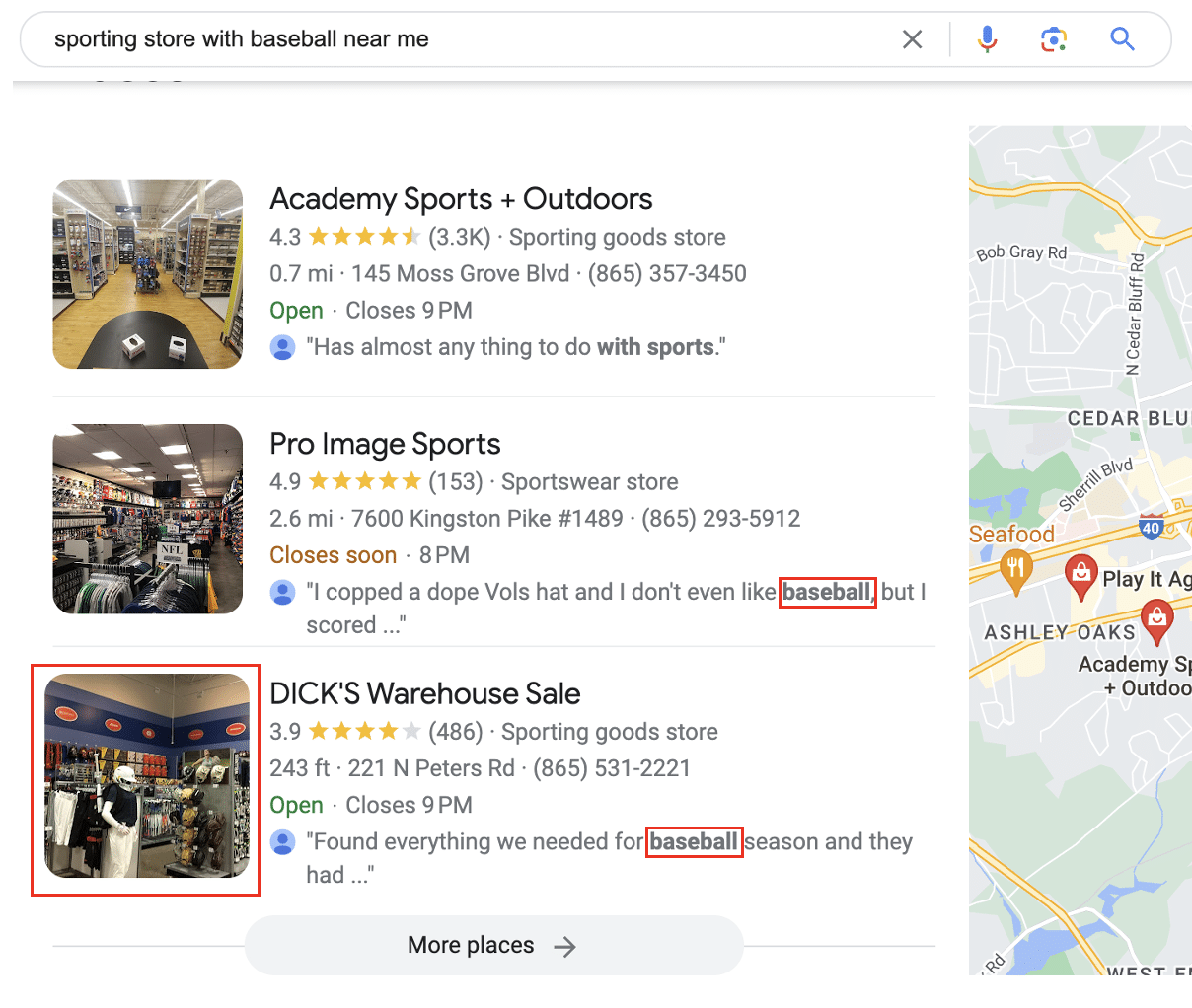
Here are a few takeaways from comparing these two queries:
- Google dynamically changed the shown image of the DICK’S Warehouse Sale listing to showcase the baseball section.
- Google calls out review mentions about baseball by bolding the mention. As a searcher, I find that this inherently made those listings more attractive, just as their “In stock” feature would.
- The SERP dropped Going, Going, Gone! from the local 3-pack even though I was standing next to it. In my opinion, this has merit as Going, Going, Gone! has a lower stock of equipment than the typical DICK’S store and primarily leans towards apparel.
- Pro Image Sports is a clothing store that carries sports appeal. It is also 2.5 miles further than the next closest sport equipment store, Play It Again Sports, which carries baseball equipment.
When comparing these results, I couldn’t help but believe that the mention of baseball in Pro Image Sports review increased their visibility within the 3-pack, so I investigated further.
Looking at the review topics provided by Google for Play it Again Sports, I noticed a high number of reviews for “golfing clubs,” so I changed the query to “Sporting Store with Golf Clubs Near Me.”
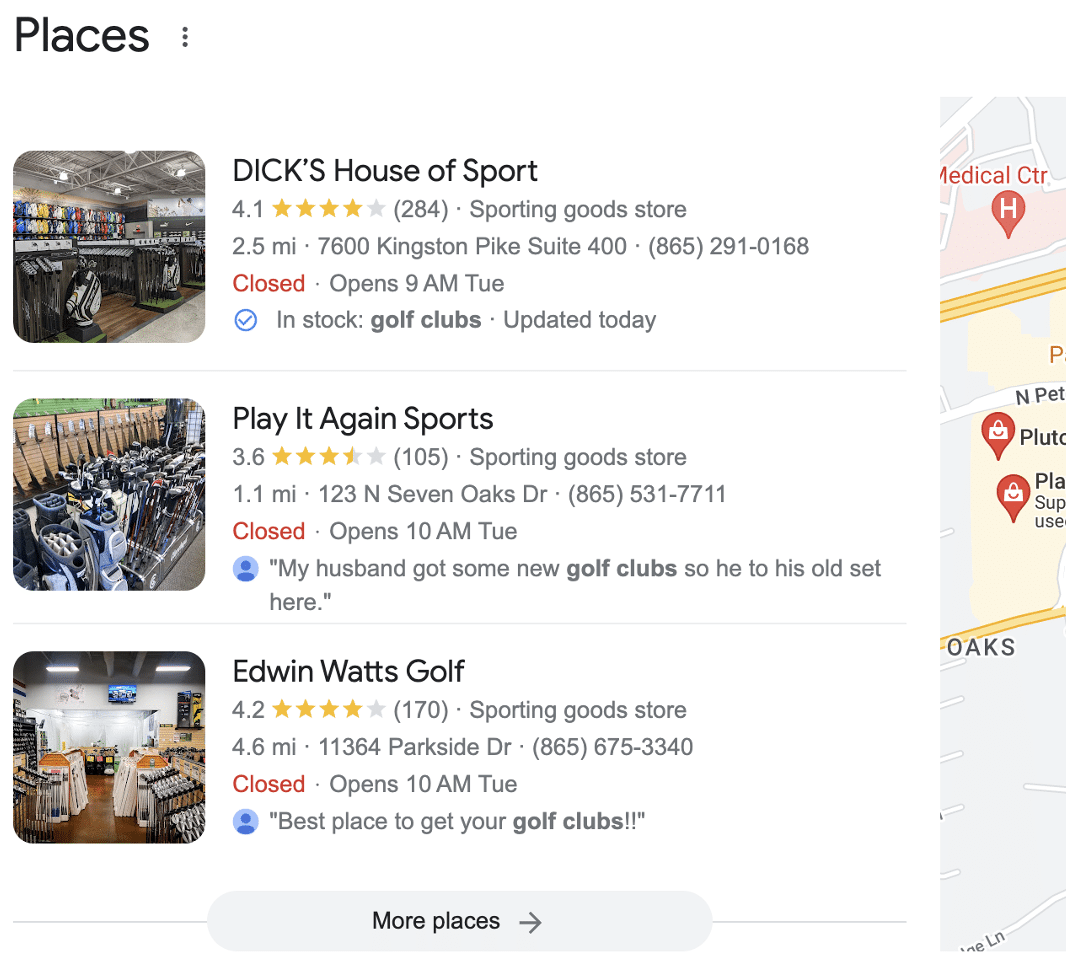
By targeting a topic that is mentioned more frequently within Play It Again Sports’ reviews, they appeared within the local 3-pack.
From this small experiment, it’s clear that review topics (entities) play a role in local 3-pack visibility and a larger one than I once believed.
Dig deeper: How to establish your brand entity for SEO: A 5-step guide
Promoting entities in review solicitation
Google’s guidelines state that review solicitation should be honest, unbiased and without incentives. Businesses should also avoid review gating.
You can ask for reviews on specific topics and remind customers of the products or services they used. Implementation will vary based on each business’s approach to soliciting reviews.
Add a statement like “Tell us about your experience purchasing baseball equipment from us” above the review link in your solicitation email.
It’s important not to exaggerate in this message to avoid biased customer reviews. For example, avoid saying, “Tell us about your positive experience when purchasing high-quality baseball equipment from us.”
While this statement does not inherently create bias as it does not offer an incentive to leave a positive review, it can be considered manipulative, which does not fully align with Google’s guidelines for reviews to be honest and unbiased.
Dig deeper: Unleashing the potential of Google reviews for local SEO
Applying review insights for business results
After learning how to analyze listings (your own and competitors), how review topics (entities) influence local 3-pack visibility and how to increase the number of entities within reviews, it’s time to put it all together to drive business results.
Sharing insights from your business listing’s reviews with the appropriate internal stakeholders is key to helping inform strategic and operational changes. Competitor insights can be a driving force for these changes.
For example, if a competitor barber shop uses hot towels in each haircut and your business does not, this data may help make the case that your business should be doing the same.
Next, work internally to leverage business intelligence (i.e., customer purchase data) within review solicitation efforts to promote entities within reviews. Implementing these efforts will vary depending on a business’s technology stack and ability to integrate data.
A more simplistic approach may be necessary for businesses that lack the ability to integrate data. In these situations, I recommend appending a generic statement within the solicitation communication to identify a specific entity.
An example may be a mechanic shop that appends the following statement to increase the mentions of “mechanics.”
- “Tell us about your experience at our shop and the quality of our mechanics.”
Regardless of the internal approach, reviews are crucial for local SEO and shaping consumer perceptions. As an SEO, you can help your business understand its strengths and weaknesses while working to improve local search visibility.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.