Google Search now supports return policy markup at the organization-level
Written on June 11, 2024 at 9:45 am, by admin
A year ago, Google added support for return policy structured data support for merchant listing and now Google is expanding that support to the organization level. “Today we’re adding support for return policies at the organization level as well, which means you’ll be able to specify a general return policy for your business instead of having to define one for each individual product you sell,” Google wrote.
You no longer need to have to specify a separate return policy for each individual product you sell. You can now have one return policy that goes across your whole organization.
More details. Google explained that by adding an organization-level return policy, it can help reduce the size of your Product structured data markup and make it easier to manage your return policy markup in one place. Plus, it will help you show your return policy in the snippets across many search appearances.
Google said it is “especially important” to add a return policy to your organization structured data “if you don’t have a Merchant Center account and want the ability to provide a return policy for your business.” “Merchant Center already lets you provide a return policy for your business, so if you have a Merchant Center account we recommend defining your return policy there instead,” Google added.
Google said if your site is an online or local business, it is recommended to use one of the OnlineStore, or LocalBusiness subtypes of Organization.
What it looks like. Here is a mockup from Google on how the return policy looks in the Google Search results:
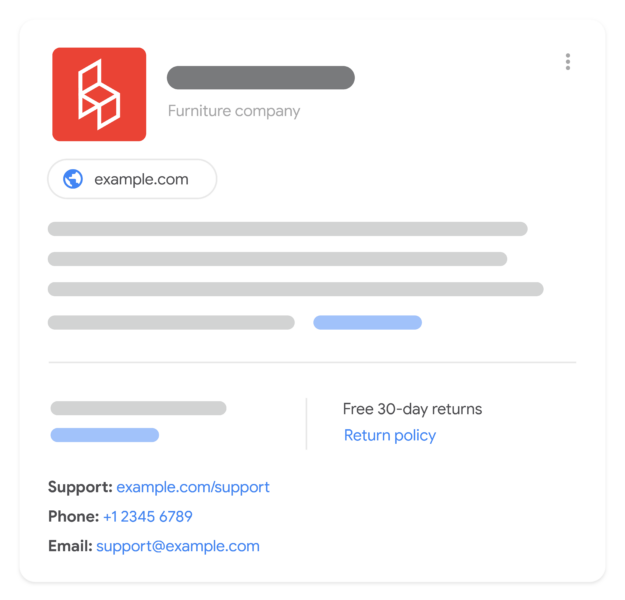
Testing this. Google said you can test return policies defined under your organization structured data using the Rich Results Test by submitting the URL of a page or a code snippet. Using the rich results test tool will allow you to confirm whether or not your markup is valid.
Here is what the tool looks like:

Why we care. If you want an easier way to implement this return policy markup across all your products on your site, now you can do it at the organization level.
This may save you time and effort, while also giving more data for Google to show in the search results about your search listings.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Google Search Console Performance report adds merchant listings to images report
Written on June 10, 2024 at 6:45 am, by admin

Google updated its search performance report within Google Search Console to include a breakdown of your merchant listings within the Google Search Image tab. This means you can now see how well your merchant listings are performing when a searcher clicks on the image tab within the Google Search results.
What it looks like. Google posted this screenshot of this report on X:
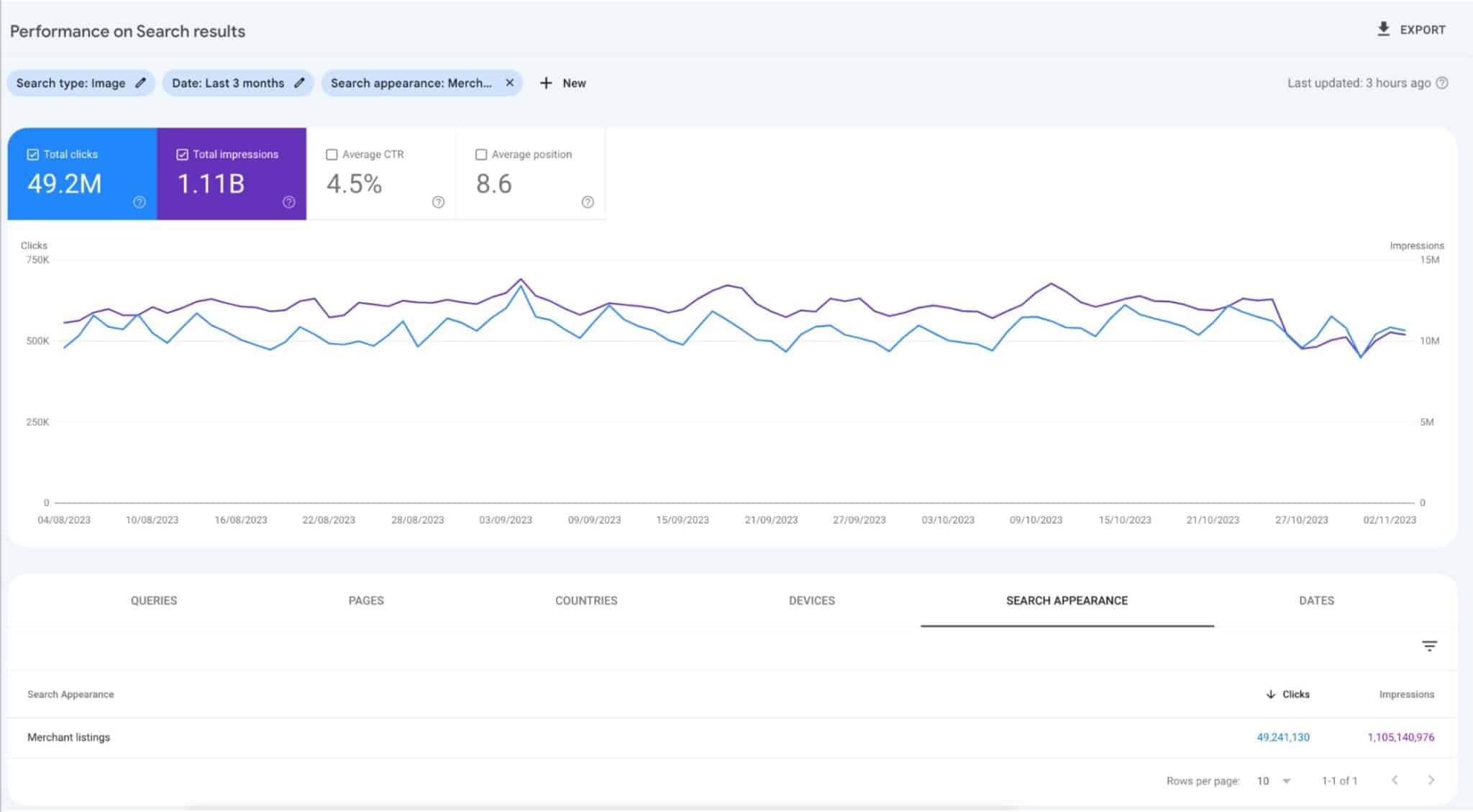
What are merchant listings. Google explained that Merchant listings are an extension of the Product snippet item that enable more full-featured search results and always include a price. “For example, they might appear in a carousel of similar products from different sellers, or in a knowledge panel in search results,” Google wrote.
What Google said. Here is the post from Google:
“New to Search Console Performance report you can now see merchant listings performance in the Google Search Image tab.”
Why we care. If you use merchant listings, now you have one more data point to analyze when doing your SEO and performance reports. This report will show you how much exposure your merchant listings are gaining from the image tab in Google Search. You can make tweaks to better optimize your performance in the image results (which can take time) and then see if those tweaks are paying off, or not.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
5 reasons why your content isn’t working and how to create helpful content Google wants to rank
Written on June 10, 2024 at 6:45 am, by admin
Since the August 2022 helpful content update, Google has been emphasizing “helpfulness” for ranking content on SERPs. Now, Google has incorporated helpfulness signals into the March 2024 core update. It’s now a huge part of search.
So, what exactly is helpful content?
Are you meeting Google’s “helpful” content requirements?
This article is a one-stop solution guide to help you clarify this question and create content that meets Google’s standards for usefulness, value and, most of all, helpfulness.
If your content hasn’t been ranking, you’ll want to read every word.
Helpful vs. unhelpful content
We can analyze helpfulness on two levels: page-level and website-level. I will focus on page-level since we mostly care about the content here but with some website-level hints.
Let’s search for the keyword “how to fix a zipper”:
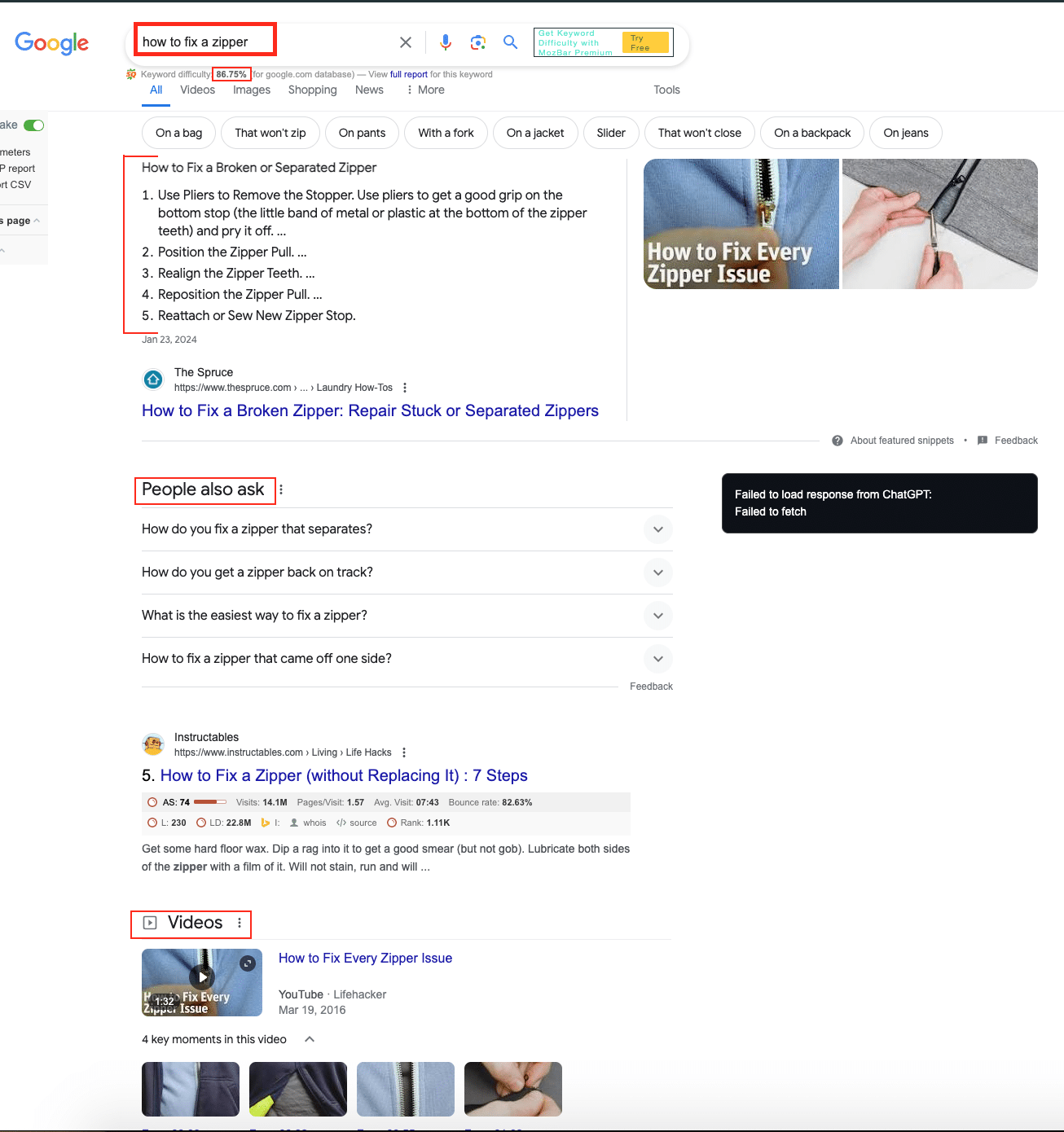
Looking at the keyword difficulty under the search box, we already know that this keyword is hard to rank for. (I’m using SEOquake Chrome extension here to get more data, which makes things easier while searching, but you can use any other tool).
High keyword difficulty (KD) means many people are searching for this query, and authoritative websites are competing to rank for it. Just look at the domains ranking at the top! (This is mostly a website-level factor; the better your website performs in general, the more chance you have for ranking.)
Note: Personally, I’m not a fan of third-party metrics. They cannot determine whether a domain is good or bad because they have their own algorithms that are different from Google’s, which could be easily manipulated. However, they can be useful when you’re dealing with a lot of data.
Back to the SERPs, the second step is to determine the intent of our keyword.
This one is easy; you can already tell it is an informational keyword. But for more complex keywords, you can look at the top title ranking, their context and other clues that Google is giving you.
In this case, the keyword has a featured snippet. There are several types of featured snippets, and this one is a step-by-step snippet.
Since the user is searching for “how to fix a zipper,” the snippet shows a series of steps on how to do it.
The next SERP feature is “People also ask,” which is a great place to get an idea about the topic you want to write about.
Another SERP feature for this query is videos. Remember how I said we should talk about steps “showing” readers how to fix their zipper? That’s exactly what this video does.
From simply analyzing the SERP features for a given keyword, Google is already giving you clues on how to create helpful content.
Put yourself in your reader’s shoes. If you have a broken zipper, following a step-by-step guide as well as watching an actual video of how to do it solves your problem instantly.
Now, let’s look at the first result in the SERP. If Google has decided to rank it number one, this is what the search engine considers helpful content:
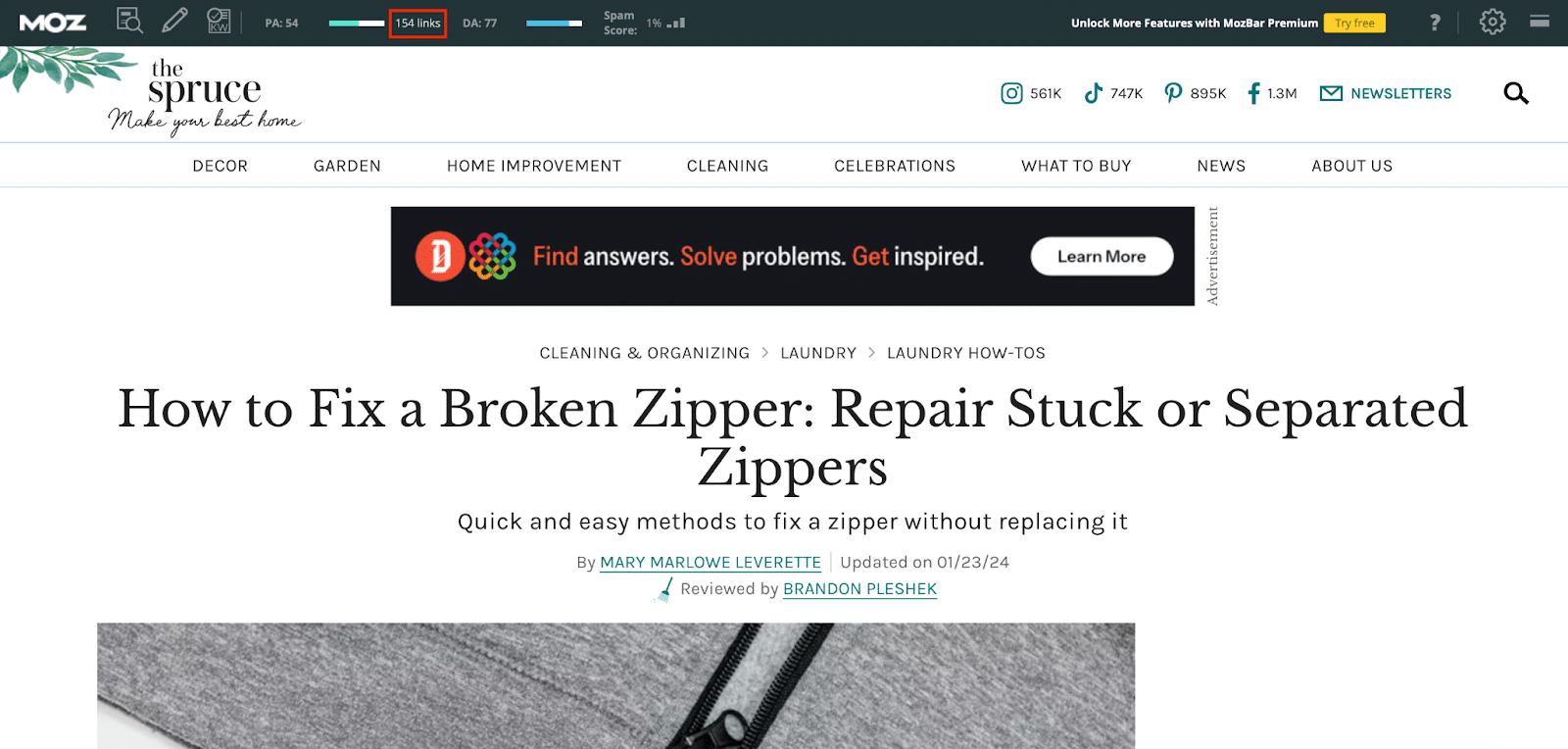
As SEOs, we all know that links matter. Looking at the Moz extension, I know this page has 154 backlinks pointing at it. This may not be 100% about how you wrote the content, but it is definitely a signal Google cares about.
I can hear Google saying, “A piece of content that has 154 other articles citing it as their source? This one probably has something interesting in it!”
What other factors make this article stand out?
- The title is straight to the point. I already know what broken zippers I’ll be able to fix by reading this article. It is targeting two of the most common issues when it comes to broken zippers – stuck and separated zippers – which I know based on the “People also ask” result.
- The article has an author byline. The name also has a link that points to the author’s detailed bio.
- The intro answers the search query right away. It also mentions what tools and materials you need and how long it will take, plus some highlighted tips.

- The article breaks down each of the steps in detail. And it comes with screenshots to demonstrate how to do it.

- There are also colored tip boxes. These visuals help break up the text and provide additional information, recommendations or shortcuts.

Now let me show you what the opposite looks like – an article currently ranked 76th for the same keyword.

How did it end up in Google hell?
First of all, it has a terrible meta description. As you can see above, it doesn’t tell you anything about the page. The meta description is the second element I pay attention to before deciding whether I want to click on it. (The first one is obviously the title).
This particular meta description is already decreasing CTR!
Let’s get into it:

The article has 27 links. Not bad, right? But why isn’t it ranking?
The intro is not very appealing and the first image you see is blurry. Just compare it with the image from the top ranking article.

Scrolling through the body of the article, I see that the step-by-step guide uses the same image, and that’s it.

Let’s put ourselves in our reader’s shoes. We want to fix a broken zipper. Despite the very poor meta description, we decided to click on this link, and this is all we got.
Neither the introduction nor the image is helpful, so you simply go back to the SERP and find a new resource, which will increase the bounce rate and churn of this domain.
Let’s look at what’s inside.
This article has more ads than actual content. There’s a whole sidebar of ads on the right column, a huge ad banner at the bottom, ads popping up every time you scroll and more ads in between the text!
The third step in the guide mentions a dense zigzag stitch. What does that even mean?
This is where an internal link would have been helpful. The author could have created a separate article on how to sew a zigzag stitch and linked it to this article to help users who may not be familiar with this sewing method.
What other factors made this article unhelpful?
If you check the first image, it is in the “sewing category,” but it doesn’t help me with any sewing.
Secondly, it contains affiliate links, which is not a bad thing by itself, but it seems like this content was written solely for commercial purposes.
Check out both links and see for yourself – it’s not that hard to distinguish helpful content from unhelpful content.
What is helpful content?
According to Google, helpful content:
- Demonstrates experience, expertise, authoritativeness and trustworthiness (E-E-A-T).
- Is created for a specific audience.
- Feels authentic and human-centered.
- Meets the needs or wants of the searcher.
Helpful content is information that satisfies a user’s curiosity and provides them with something valuable. Here are some key aspects of helpful content:
- User-focused: It’s written with a specific audience in mind, considering their needs and interests.
- Expertise: It comes from a credible source with knowledge and experience on the topic.
- Value: It fulfills the user’s intent, whether it’s informing them, answering a question, solving a problem or even entertaining them.
- Unique perspective: It offers fresh insights or a new take on existing information
Take a closer look at your content. Is it genuinely helpful for your audience, answering their questions or solving their problems?
If your content doesn’t provide unique insights or information, it’s time to either improve it or remove it altogether.
Is your content not ranking? Focus on creating people-first content that demonstrates real expertise and provides an exceptional user experience.
Dig deeper: Mastering content quality: The ultimate guide
5 reasons why your content isn’t working
Here are five reasons why your content might not be ranking as well as you’d like, along with some hard-won wisdom on how to fix it.
1. Your content doesn’t offer anything new
Your page may be of good quality but if it doesn’t offer anything new, it may have a tough time cracking the top spots.
When Google already has numerous pages on the same topic with similar (and better) content, there’s little reason for it to rank yours.
If your content is mostly scraped from other sources or simply rehashes information that can be found elsewhere, don’t expect it to perform well in search.
This is especially true in the age of AI-generated content. While AI can be a helpful tool, relying too heavily on machine-generated content without adding E-E-A-T is a recipe for ranking disaster.
Rather than rehashing the same old information, focus on crafting unique content that provides a new angle or perspective. Infuse your writing with your own expertise and real-life experiences to make it truly one-of-a-kind.
Adding something unique and substantive to your blog post can give Google a reason to include it among the top results for the topic.
2. Your intro is too long and fluffy
With the launch of AI Overviews, Google seems to favor results from Reddit and Quora, which often provide straight-to-the-point answers.
If you’re trying to rank for “embroidery tips,” don’t start with a two-paragraph history and definition of embroidery. This is a common issue with content that’s generated by chatbots like Gemini, ChatGPT and Claude.
People want answers fast, so keep your introduction brief and to the point. If your AI writer takes too long to answer the query, cut the fluff during the editing stage.
3. Your content doesn’t match user intent
Search intent is another significant ranking factor as Google prioritizes delivering results that best match the user’s query.
You could write the most epic, in-depth piece of content ever, but if it doesn’t align with what searchers are actually looking for, it might still fail to rank.
That’s because Google is getting pretty good at understanding search intent and delivering results that match.
If someone searches for “how to tie a tie,” they want a quick step-by-step guide, not a 5,000-word essay on the history of neckwear.
Let’s say you’re trying to rank for “how to fix a leaky faucet,” but your page only covers plumbing tools or types of faucets. Google will immediately recognize that this page does not have the answers that users seek.
Similarly, if a searcher is looking for “cheap DIY plumbing tools,” Google will favor pages selling these tools over a page about plumbing techniques. That’s because the term “cheap DIY plumbing tools” indicates commercial intent, with users ready to make a purchase. Google will rank ecommerce pages for this keyword, not informational ones about faucet leaks.
Also, consider your page’s overall structure. Mixing too many search intents on a single page can confuse Google.
For example, an educational page on home renovation techniques followed by a list of your service offerings might make it unclear whose needs the page is trying to serve.
4. Google prefers a different content format for the query
Even if your content is useful, informative and unique, your long-form blog post might struggle to climb the SERPs if Google thinks there’s a better type of content to meet users’ needs.
For some queries, Google strongly prefers videos, product listings, map packs, or direct answers pulled from a trusted source (also called snippets).
For instance, your home renovation site aims to rank a page on how to fix a leaking faucet. You search some relevant keywords you believe your page should rank for:
- “DIY faucet repair”
- “Fix leaky faucet”
- “Repair dripping faucet”
- “Stop faucet leak”
- “Leaking faucet solutions”
You notice that Google is displaying many videos in the SERPs for these terms.
If Google thinks searchers want a specific format, that’s what it will prioritize in the results. No matter how amazing your blog post on “how to fix a leaky faucet” is, your written content may never rank above these videos.
A quick fix would be to include a video in your written content to help you compete with top-ranking pages.
Scope out the top search results for your target keyword. If Google seems to prefer a particular format, it’s time to change your strategy.
5. Your competitor’s content is better
Sometimes, your page isn’t ranking well simply because it doesn’t measure up to your competitors. If their content is more in-depth, engaging or of better quality than yours, that could be the culprit behind your lower rankings.
Fortunately, this is one of the easier issues to fix. Carefully review the top-ranking content for your target keywords. How does it compare to yours in terms of depth, helpfulness, expertise and user experience?
To create content that stands out, find unique angles and insights that your competitors have missed. Put in the extra effort to create content that’s not just good but exceptional.
How to create content that Google wants to rank
Now that you know the top reasons why your content is tanking in the SERPs, it’s time to start creating content that Google will actually want to rank.
When creating content, put yourself in your reader’s shoes and ask yourself these questions:
- Would I click on this headline?
- Does this solve a problem or answer my question?
- Is this relevant to my interests?
- Would I read past the first paragraph?
- Is the information useful?
- Is it enjoyable to read?
- Is it visually appealing?
- Is it easy to skim?
- Would I scroll to the end despite my busy schedule?
- Would I lose interest and bounce to another page?
Keep editing and revising your content until you can answer “yes” to all these questions.
When you write with your audience in mind, you will not only be able to serve their needs and capture their interests, but Google will also take notice.
Dig deeper: 25 tips to optimize your content for people and search engines
5 tips for writing helpful content
Helpful content goes beyond sharing useful tips and covering a topic in-depth. Thousands of blog articles do that. What will make your content stand out?
Here are five tips to help you create helpful content that readers – and Google – will love.
Create topic clusters
The key to establishing topical authority is to create related content and link them together – also called topic clusters. Let’s say you’re trying to rank for “how to fix a leaky faucet.” Maybe your readers might want to know about the different types of faucets or the history of faucets. Create a dedicated article for those subtopics and link them to your pillar content.
Whenever you come up with a topic idea you think your readers will be interested in, link it to the related article. This will give you a strong structure for Google to crawl and discover your content better.
At the same time, you’re providing a better user experience as your readers can choose to read more about that subject by clicking on the link instead of scrolling down a very long article with unnecessary data. Plus, you are improving your other content by giving it an internal link.
Don’t be redundant
Each header should provide value to readers. But you don’t have to keep repeating your main points in every section. You want the reader experience to be enjoyable, not lull them to sleep.
Get to the point
If your topic is how to fix a leaky faucet, don’t take too long to tell (or show) your readers how to do it. Offer value above the fold – not in the middle of your post.
Backup your claims
Let’s say you’re trying to convince your readers that stainless steel faucets are better than chrome or brass. Why would they believe you? Always back up your claim with facts, testimonials and external links from a credible source.
Go beyond the basics
So you have your standard blog post with 2,000 words and a couple of images. It looks exactly the same as thousands of blog posts on that topic. What can make it stand out?
Embed a relevant tweet or a YouTube video, add a quote card from an expert or include a customer testimonial. There are many ways to personalize your content by going beyond the basic text + image formula.
Helpful content checklist
Here’s a cheat sheet to help you create content that ranks well.
Title tag
- Is the title tag between 55-60 characters?
- Does the title tag reflect what the article is about?
- Is the title click-worthy?
- Is the main keyword mentioned in the title tag?
Meta description
- Is the meta description between 150-160 characters?
- Does the meta description summarize what the page is about?
- Is the main keyword mentioned in the meta description?
Headline (H1)
- Does the headline offer value to a target audience?
- Is the main keyword mentioned in the headline?
Content
- Does the article have a clear targeted topic or keyword?
- Is there an author byline with a link to the author’s page?
- Is there a table of contents?
- Does the introduction contain a hook and address the search query right away?
- Does the content have a unique take on the topic that makes it stronger than the competition?
- Does the content include statistics, examples, facts or case studies to support claims?
- Is the content written just for Google or is it written for people?
- Is the content too thin to be helpful?
- Is the content written by AI or humans?
- Is the content plagiarized or detectable?
Multimedia
- Does the article contain visuals?
- Are the images and infographics high quality?
- Do the images have alt tags?
- Are the images and videos properly optimized for mobile?
Readability
- Does the blog post have a clear structure with an intro, body and conclusion?
- Are subtopics divided into sections with relevant headers?
- Are there bullet points or numbered lists for easy scanning?
- Are sentences and paragraphs short and easy to read?
- Is the article free of typos and grammatical errors?
Helpful content = helping people
Creating helpful content that Google wants to rank simply comes down to one thing: putting people first. Focus on crafting content that genuinely helps your audience, showcasing your expertise and building trust along the way.
While SEO tactics like keyword and technical optimization are still important, they should enhance your already valuable content rather than be the sole focus.
Prioritize helpfulness and authenticity, and you’ll be rewarded with a loyal following and improved search rankings.
Dig deeper: Writing people-first content: A process and template
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Driving traffic to gated content and paywalled sites: SEO tips + examples
Written on June 10, 2024 at 6:45 am, by admin

We know that gated content can drive leads and revenue. However, hiding your best stuff can be a double-edged sword.
On the one hand, it creates exclusivity and value for paying subscribers; on the other, it presents a challenge in driving organic traffic.
For video membership sites, where much of the valuable content is locked behind a paywall, striking a balance between content accessibility and exclusivity is key.
This article explores strategies to optimize such sites and boost traffic without compromising the premium nature of gated content.
The challenge of gated content
Gated content, especially video content, is a powerful tool for generating revenue and maintaining an engaged community. However, it limits the content available for search engine indexing, potentially reducing organic traffic.
For video membership sites, for example, or other subscription-based sites, optimizing for search engines while maintaining the gated content’s allure is a nuanced task.
Understanding the balance between providing enough free content to attract visitors and maintaining the value of gated content is crucial for success.
The SEO implications of gated content
Search engines thrive on content accessibility. When significant portions of a site are behind a paywall, search engines can’t index them.
Gated or paywalled content often contains rich, valuable keywords that do not contribute to the site’s overall organic visibility.
What search engines can’t access or read, they cannot rank. It’s a problem that has many subscription site owners scratching their heads.
They want their site to be found to attract new members/subscribers, but they don’t want to give away content (making it freely crawlable and visible to users) that people should be paying for.
How do I stop Google from indexing my gated content?
Your big-money content will likely be hidden behind a number of walls (gates, locks, take your pick), some of them more successful at preventing crawling and indexing than others.
How thorough they are and whether the work is done for you will depend on your platform/CMS. Here are some simple examples.
Noindex, nofollow
You would find noindex and nofollow tags in the HTML <head> section of a webpage. These tags are added to the page’s HTML code to control how search engines interact with that specific page.
The noindex tag tells search engines not to include a specific page in their search results. The nofollow tag instructs search engines not to follow any links on a page, so the linked pages don’t benefit from the link.
These tags help control what gets indexed and how link value is passed (or isn’t passed as the case may be).
Robots.txt
A robots.txt file is a simple text file in your website’s directory that tells search engines which pages they can and cannot crawl. Its main purposes are to manage search engine traffic, reduce server load and prevent indexing of private or non-essential content.
By specifying these rules, you can ensure that search engines focus on the most important parts of your site, improving its visibility and performance in search results. If your robots.txt is set to stop Google’s crawler/bot from the site, it’ll look like this.
User-agent: Googlebot
Disallow: /
If it’s set to exclude only certain pages or content from crawling, it might look more like this.
User-agent: Googlebot
Disallow: /vide-catalog/
Disallow: /course-content/
Go to your website and then type /robots.txt at the end of the URL to see your robots.txt file. Always get professional guidance before changing your robots.txt file.
Note: If a robots.txt file blocks the page or if the crawler is otherwise unable to access it, the crawler won’t be able to detect the noindex directive. Under these circumstances, the page might still appear in search results despite the directive – especially if other pages link to it.
X-robots tag
A simple command that can be included in the settings of your website to tell search engines what they should not show in search results.
This is particularly useful for content like PDF files or images that can’t use regular website commands because they don’t contain standard website code.
To keep search engines from showing certain files in search results, you can set the X-Robots-Tag to noindex.
This tells search engines to skip over these files when they’re putting together search listings, which is perfect for content you only want certain people to see, like subscribers or registered users.
Does SEO apply to gated content?
If you’re hiding content from search engines, it cannot rank or help your other content to rank. It’s an uncomfortable truth that makes questions about SEO and membership sites, for example, difficult.
Instead, a better question to ask yourself and your marketing team is, “How can I use SEO principles to market my premium, paywalled content?”
While the challenges of gated content are real, there are strategic approaches that can help attract traffic to your site and through your conversion funnel.
Top strategies balancing SEO and gated content
It is possible to find a balance between openly publishing content that brings eyeballs and $$$, without giving away your best stuff. Here are some suggestions to get you started.
1. Creating high-quality teaser content
Teaser content serves as a preview of the gated content. It should be valuable enough to rank in search engines and entice visitors to subscribe.
Short snippets or trailers can effectively showcase what’s behind the paywall. These clips should highlight key points or particularly engaging moments to pique viewers’ interest.
For instance, a 30-second clip featuring highlights from a longer tutorial can showcase the value of the full content.
Recently, educational YouTuber Astrum combined a face reveal video with a tease of his new Patreon membership community. Since publishing the video, his Patreon members have grown to four figures.
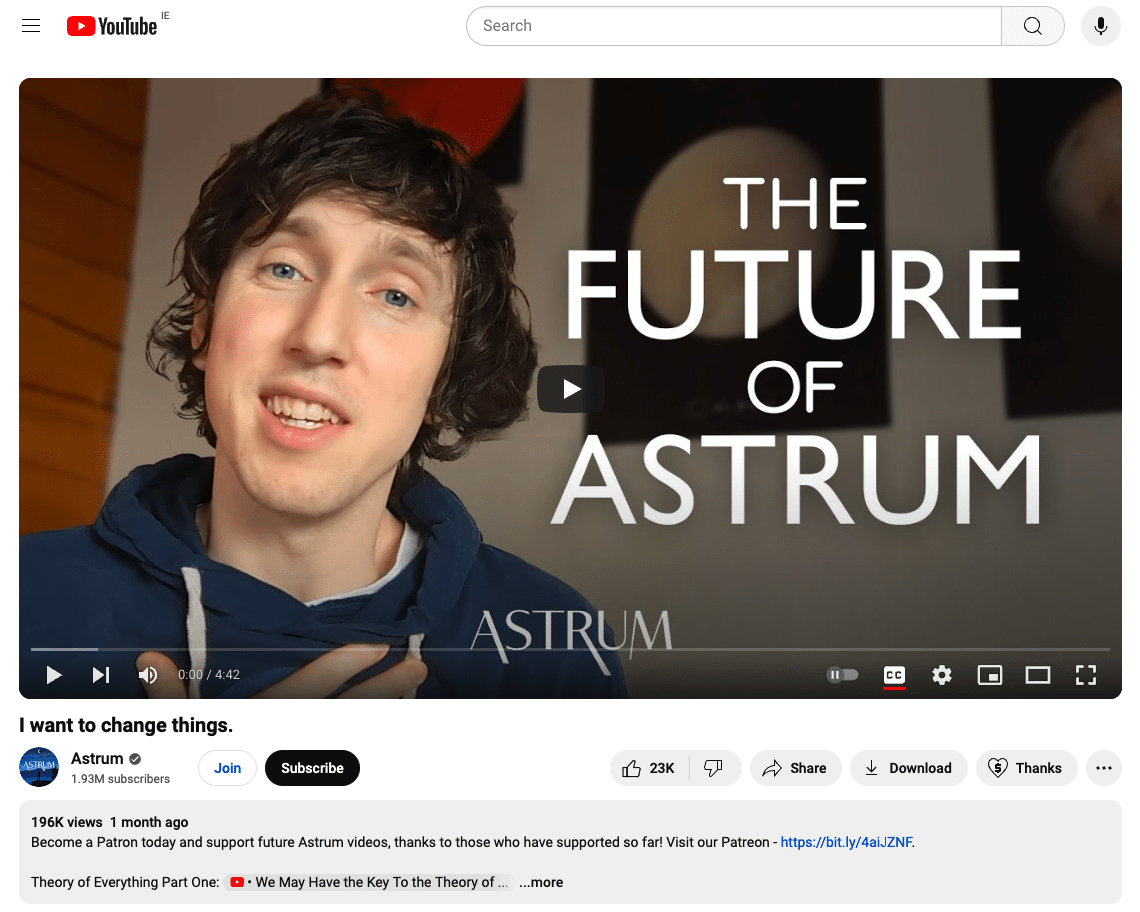
2. Leveraging ungated content
When it comes to boosting your site’s visibility and subscriber count, ungated content is your best friend. It’s all about drawing in a broad audience and gently guiding them towards more exclusive, gated materials.
Landing pages
Strategically crafting blog posts and dedicated landing pages can significantly boost the visibility of your gated content and drive conversions.
By optimizing these assets with targeted keywords, engaging content and clear calls to action, you can attract both search engine traffic and motivated leads eager to access your premium content offerings.
Prolific blogger and social media course creator Anita Dysktra has a brilliant landing page for her Passive Profit with Pinterest course.
It’s a beast of a page, featuring animated elements, strong CTAs, plenty of detail about what the course entails (she uses her expert writing skills to really sell the dream of what completing the course can mean for each student) and social proof in the form of case studies.
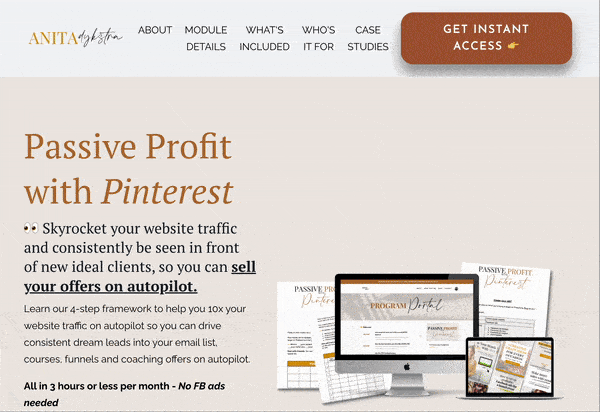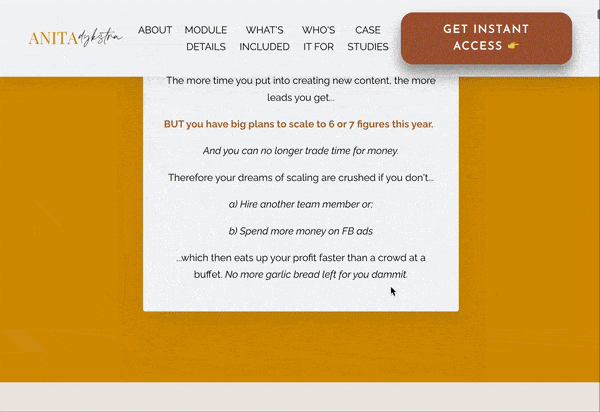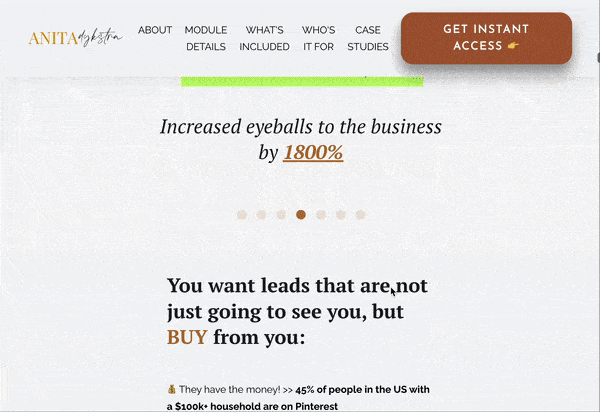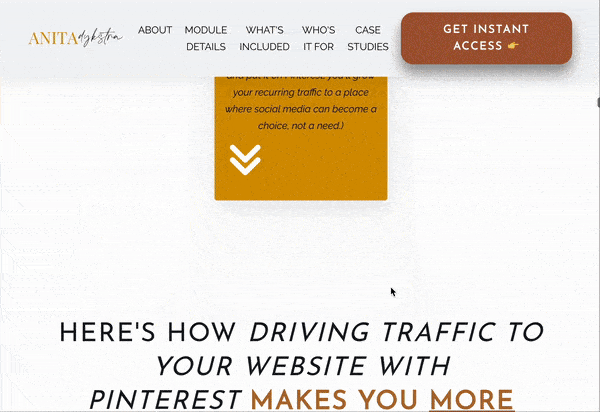
Blog posts and topic clusters
Now, onto blogs and topic clusters: This is where your content really starts to work smarter.
By creating high-quality blog posts that speak directly to your target audience, organizing them around core topics and signposting your gated content/catalog from your free content, you build a solid network that spiders out from a central “pillar” page.
This setup is great for SEO and provides a more intuitive user journey.
- Start by pinpointing key themes that resonate with your audience.
- Create a central pillar page for each theme and branch out to several accessible, free articles.
- These pieces pull in organic traffic with valuable, easy-to-access information.
- Then, weave in links to more exclusive, gated content that delves deeper into the subject. This approach boosts your pages in search rankings and naturally leads curious readers toward becoming subscribers.
By crafting these topic clusters, you enhance search performance while guiding your visitors through a curated content journey that feels both organic and enlightening.
This method ensures they consistently find valuable content at every turn, solidifying your brand as a trusted authority and naturally encouraging them to explore your gated materials.
3. Implementing SEO best practices for videos
For the videos you do share publicly, video SEO is critical. Implementing best practices ensures that your videos contribute to your site’s overall SEO health.
Optimize video titles and descriptions
This one is kind of obvious but still gets forgotten. When it comes to video content, the titles and descriptions play a crucial role in attracting viewers and enhancing the video’s SEO.
Start by naturally integrating relevant keywords into your video titles to boost discoverability. Aim for catchy and descriptive titles that succinctly convey the essence of the video while enticing potential viewers to click.
For the descriptions, go beyond a simple summary. Provide a detailed overview that includes the primary keywords related to the video’s content.
This aids search optimization and helps viewers understand what to expect from the video, improving engagement rates. Additionally, include calls to action and links to related content or your website to drive further interaction and traffic.
Enhance your videos with subtitles
Adding subtitles is not just about making your videos more accessible – it’s also a smart SEO move.
Subtitles open up your content to a wider audience, including those who are deaf or hard of hearing and viewers who might be scrolling through their phones in places where audio isn’t an option. Plus, let’s not forget the viewers who simply prefer reading along!
Subtitles can also boost your SEO. By embedding subtitles, you’re effectively feeding search engines with a rich layer of text full of relevant keywords from your video.
It can then be pulled into the structured data of the video (see the next section for more information). This makes your content more crawlable and indexable, enhancing your visibility in search results.
And there’s more – subtitles can lead to better engagement. Videos with subtitles often keep viewers hooked longer. Why?
Whether your content is packed with jargon or you’re explaining complex concepts, subtitles can help viewers follow along and grasp the details.
To get subtitles up, either update or fix YouTube’s often janky auto-subtitles. You can also create SRT files which are simple text files that sync your video dialogue with the timing of each text segment. Upload these with your videos, and voilà, your content will be more inclusive and primed for better search engine performance.
Use structured data
Implementing schema markup for your videos is another powerful way to enhance their visibility in search results. By adding structured data, you provide search engines with a more explicit understanding of your video content.
Structured data can include the video title, description, duration and more. If your video is hosted on YouTube, any embed will come with structured data built-in, but a lot of the SEO value and traffic will go to the YouTube page, not your website.
An alternative option could be hosting somewhere like Wistia. Your video would have built-in structured data, but the Wistia video page isn’t indexed, so all the SEO value goes to your site.
Structured data helps to create rich snippets, which are enhanced descriptions that appear in search results.
These snippets can significantly increase click-through rates by offering potential viewers detailed information about the video content directly in the search results, such as a thumbnail and a brief description.
This extra context can make your video more appealing and informative at a glance, which encourages more clicks and, ultimately, more views.
It’s important to note that on Google, the game is very much rigged toward YouTube (which makes sense, as Google owns YouTube).
Most video snippets in search are from YouTube, and there are now tighter guidelines on how pages can be eligible.
Dig deeper: A technical guide to video SEO
4. Freebies and giveaways
Offering a mix of free and premium content can be a game-changer for drawing in a diverse audience and nurturing them toward becoming paying subscribers.
Start by identifying what you can give away. This could be a few starter lessons from a course or some introductory articles that showcase the breadth and quality of your content. These freebies are your hook – they grab attention and spark interest.
Think of your free content as a teaser, a sample platter with just enough taste to leave your audience craving more.
For instance, if you’re offering a course’s first few lessons for free, ensure these are engaging and informative. They should deliver value and clearly demonstrate what users gain by opting into the full course.
As users enjoy the free content, they should encounter natural cues nudging them toward the gated, premium offerings. It’s about making the transition feel like a natural next step.
Highlight what’s beyond the paywall: deeper insights, more comprehensive data, exclusive resources – these are your main selling points.
And why not throw in a special giveaway now and then?
Maybe it’s one-time free access to a detailed guide or a private webinar. These limited-time perks can provide a compelling reason for free users to upgrade to the premium side.
Creator Latasha James has built an extensive content catalog for those looking to step into or advance a freelancer career.
Her free Launch Your Freelance Career course is promoted on her socials and “main” site, which acts as a funnel into her membership platform. It’s an excellent example of giving away quality content in return for engagement with future members.

5. Utilizing user-generated content
Users who advocate and create content for/with you are gold! Their authentic engagement and contributions can be incredibly valuable to your business and online presence.
Encouraging users to actively participate in creating and sharing content can boost engagement and positively impact your site’s SEO.
User-generated content (UGC), whether in the form of reviews, testimonials or community forums, adds a personal touch that resonates with your audience.
Here are some ways you can utilize UGC for SEO benefits.
Encourage reviews and testimonials
Positive reviews and testimonials boost your brand’s credibility and can be a secret weapon for enhancing your search visibility, especially if you play your cards right.
First things first: figure out where your audience likes to hang out. This will guide you on how to best leverage testimonials.
If your audience spends much time on YouTube, why not showcase engaging video testimonials there?
A written review is one thing, but to have a member or subscriber take time out of their schedule to sit and record a testimonial with you is something else.
For audiences who inhabit a lot of space on social media, think about creating snappy shorts or reels.
These bite-sized testimonials can capture attention quickly, making them perfect for sharing on TikTok, Instagram or Facebook.
If your blog is where the action is, turn those video testimonials into rich blog posts.
- Start by transcribing the video to capture the spoken words in text form, boosting your SEO by making the content searchable.
- Then, embed the video to engage those who prefer watching over reading.
This dual approach diversifies your blog’s content and deepens each post’s impact.
Don’t forget to also encourage your happy customers to leave reviews on prominent review sites and within online communities.
These independent reviews reinforce the quality and value of your content, further boosting your credibility and, indirectly, organic search rankings.
Nurture your community: Make space for them
Setting up forums or discussion spaces where users can swap stories and insights is just the beginning. The real magic happens when you jump into the mix.
It’s essential for you to get down in the trenches, talking directly to your members and engaging with them wherever they hang out online.
When folks feel heard and valued, they’re more likely to engage deeply and spread the word, boosting both community spirit and your content’s reach.
Let’s look at The Try Guys as a prime example. Their subreddit isn’t just a place to chat – it’s a thriving community hub. Here, fans dissect episodes, share memes and connect over shared interests.
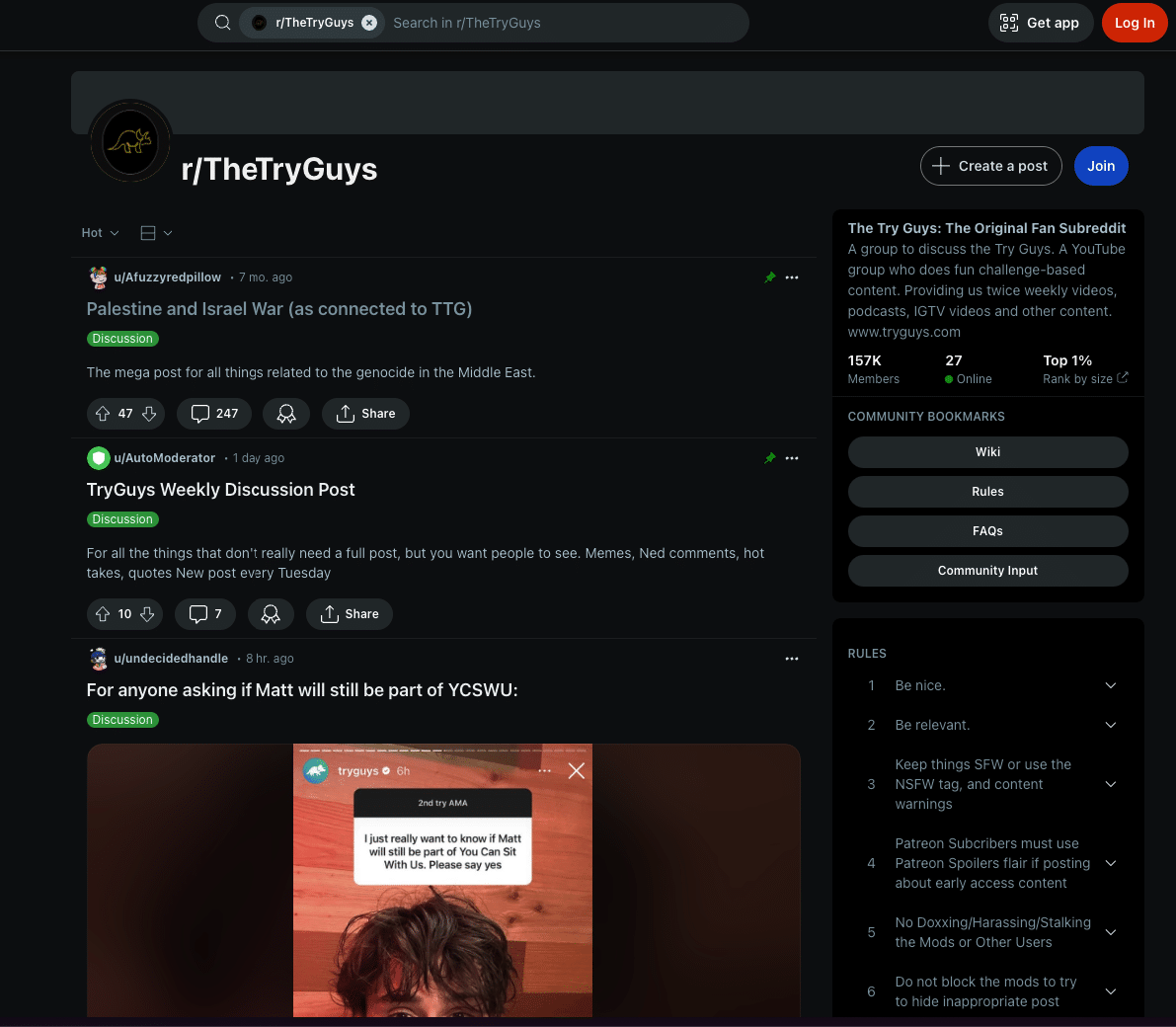
But it’s not just about keeping fans happy. Active communities generate a ton of user-generated content ripe for search engine indexing, which can really ramp up your SEO efforts.
Plus, these forums are gold mines of insights into what your audience loves, which can steer your future content and marketing strategies.
Also, personally diving into community discussions does wonders for humanizing your brand. It transforms you from a distant broadcaster to a relatable figure who genuinely cares about what’s buzzing in the community.
This can build a solid base of trust and loyalty, making members feel connected to your brand on a personal level.
6. Promoting gated content through social media, email and influencers
While SEO plays a fundamental role in driving traffic, it’s essential not to overlook the power of other channels.
Social media, email marketing and influencer partnerships are invaluable tools for reaching wider audiences and directing more traffic to your gated content.
Tease content on social media
Using social media to promote your gated content can dramatically boost both its reach and engagement.
Start the conversation by sharing intriguing snippets, standout quotes and compelling highlights from your content. This approach doesn’t just spark curiosity among your followers; it gives them a sneak peek of the valuable stuff waiting behind the gate.
Why not add some eye-catching visuals to the mix? Think custom graphics, short video clips or even animated GIFs to make your posts pop in a busy social media feed.
It’s also vital to nail your captions – they should highlight what makes your content unique and include a persuasive call to action that encourages clicks.
Take a page from The Try Guys’ playbook: on Instagram, they use snippets and behind-the-scenes glimpses to draw followers to their subscription streaming platform, 2nd Try.
By showcasing the entertaining and engaging nature of their exclusive content, they not only attract views but also boost the perceived value of their offerings.
By consistently teasing content across your social channels, you create multiple opportunities to engage potential paid members, significantly boosting the chances they’ll sign up or subscribe for the full experience.
This approach drives traffic and generates anticipation and interest, key ingredients in converting followers into loyal customers or subscribers.
Email campaigns
Leverage the power of email marketing to spotlight your newest gated content and inspire more subscriptions. Integrating tantalizing previews of upcoming gated materials in your email communications can ignite interest and motivate your audience to subscribe for full access.
Begin by smartly segmenting your email list. This allows you to craft targeted messages that resonate deeply with distinct groups.
For instance, you can engage current subscribers by showcasing advanced content that complements and expands on their existing benefits, ultimately enhancing retention.
On the other hand, potential new leads might receive introductory emails highlighting the advantages of subscribing, perhaps coupled with an exclusive offer or an impactful case study showcasing the value of your content.
Consider employing dynamic content in your emails, which adjusts based on the recipient’s previous interactions with your site. This might include sections of gated content tailored to their demonstrated interests or past behaviors.
Dance fitness and education creators Bfunk cleverly used email to update their community about recent in-person events and encourage them to explore the classes and routines from those events online.

Engage with influencers
Influencers are trusted within their circles, making them perfect for reaching audiences that might not even know you exist.
Start by finding influencers or partners who really get your brand and have a following that matches your target audience. Their thumbs-up can significantly lift your content’s appeal.
Work together to create engaging content, like guest posts or exclusive previews, that showcases the real value of what you’re offering.
Why not kick things up a notch?
Engage your audience with something interactive, like a joint livestream or webinar. These real-time interactions are not just fun; they connect people directly to your brand, making it more likely they’ll hit that subscribe button.
Using influencers strategically can widen your reach, enhance your credibility and drive subscriptions, all while keeping the conversation lively and relevant.
Go get more traffic to your gated content
Navigating the complexities of a website with gated content can be quite an endeavor, but it’s definitely within reach.
By adopting the strategies we’ve delved into, video membership sites – and indeed any content-driven site – can find the perfect balance. This involves offering irresistible exclusive content while still pulling in organic traffic.
Through smart moves like teasing content snippets on social media, sending out finely tuned email blasts and partnering with influencers who resonate with your brand, you can significantly boost your site’s visibility.
But remember, this isn’t just about getting eyeballs on your pages; it’s about converting visitors into loyal community members.
By thoughtfully managing your gated content, you ensure it remains valuable and exclusive, making your subscribers feel part of something special. This sense of exclusivity keeps your current members happy and attracts new subscribers who are eager to dive into what you offer.
The end game? To foster a vibrant, engaged community that values your content and actively contributes to its expansion.
By weaving together SEO savvy with a keen understanding of your audience’s needs, your site is set not just to succeed but to thrive, building a dynamic community that grows and evolves with you.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Study: 96% of sites in Google’s top 10 positions have 1,000+ links from unique domains
Written on June 6, 2024 at 9:44 pm, by admin

Can you rank in the top 10 of Google with very few links? Not according to a new analysis published today by Internet Marketing Ninjas. It found that:
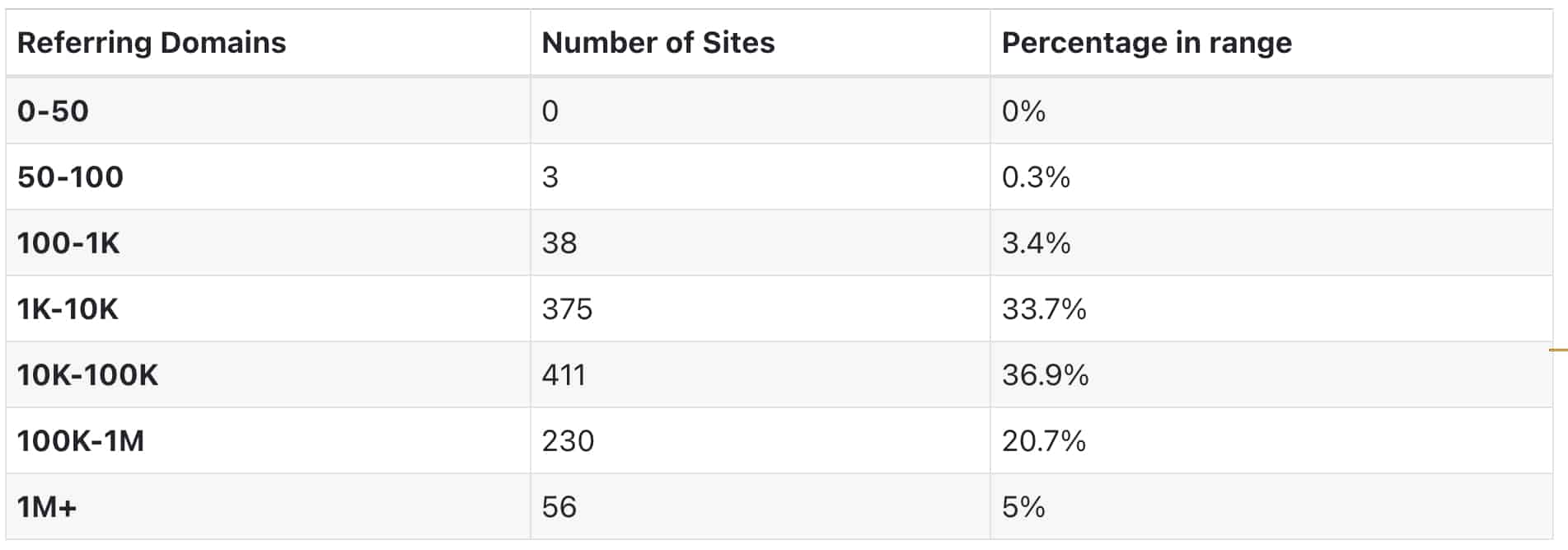
- Over 96% of websites ranking in the top 10 of Google had more than 1,000 backlinks from unique domains.
- Only 0.3% had less than 100 backlinks.
Why we care. Google has been saying that links are no longer one of the top three ranking signals and needs “very few links to rank pages.” However, clearly, websites that rank well tend to have more backlinks. But it’s also true that webpages that rank well tend to attract a lot more backlinks – because they rank so well.
The results. Here’s a table showing the overall findings:
Some other interesting findings from the backlink analysis:
- Amazon ranked in the top 10 for 164 of the 200 keywords; the next closest brand was Walmart (57).
- The “weakest” site had 54 referring domains and ranked in Position 6.
- An average of 164 unique domain backlinks appeared to be the “minimum required to rank in the top 10” for local search terms, for the lowest 10 sites
But. As the study notes, not all links have equal value. Variables that could influence the value of a link include the authoritativeness of the linking site, anchor text and whether people actually click on the links.
About the data. The results are based on an analysis of the top 10 Google Search results, consistenting of 1,113 unique websites, for 200 random commercial intent keyword phrases.
The study. You can read it here: Backlinks Google Study
Dig deeper. Search Engine Land contributor and SMX speaker Eric Enge has done multiple studies in past years showing that links have value:
- Updated study: Links are still incredibly important for ranking in Google
- New Google link study shows links are as important as ever for ranking well in search
- New Google ranking study shows links are incredibly important to the ranking algorithm
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Google Ads launches Brand Recommendations powered by AI
Written on June 6, 2024 at 9:44 pm, by admin

Google is launching a new set of AI-powered “Brand Recommendations” within the Recommendations page of Google Ads, the company announced today.
The big picture. The tailored Brand Recommendations span awareness and consideration campaigns with cost-per-thousand (CPM) and cost-per-view (CPV) bidding. They complement the existing performance recommendations for cost-per-action campaigns, giving advertisers a “full funnel” of optimization choices.
Why we care. For brand marketers looking to stay ahead, these automated, insight-surfacing recommendations could provide an easy way to regularly access Google’s latest best practices.
How it works. Brand Recommendations analyze an advertiser’s Google Ads history, campaign settings and industry trends to automatically surface ways to improve brand campaign performance and effectiveness.

What’s included. The recommendations fall into five main categories:
- Ads and assets (e.g. add bumper ads, include ideal video aspect ratios)
- Bidding and budgets (e.g. adjust CPM/CPV bids and budgets for flighted campaigns)
- Keywords and targeting (e.g. opt into audience expansion, remove contextual targeting)
- Measurement (e.g. link YouTube account for more reporting)
- Full-funnel opportunities (e.g. “funnel up” to a brand campaign)
The recommendations are customized for each advertiser and updated regularly as Google’s systems discover new optimization opportunities.
What they’re saying. “Adopting Brand Recommendations are part of a best practice to maximize the chances of brand campaign success,” Google said in its announcement.
Bottom line. The new Brand Recommendations use Google’s AI smarts to analyze advertisers’ specific situations and suggest relevant ways to improve their brand marketing on Google’s properties.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
5 local SEO insights from Google’s API documentation leak
Written on June 6, 2024 at 9:44 pm, by admin

When news of the leaked Google Search API docs broke last week, our team quickly crawled them to look for anything relevant to local SEO.
My first take was most of the “local” stuff was either fairly basic (“Hey, Google uses business addresses!”) to mostly irrelevant map nerdery (“This content describes a representation of a material used to define the appearance of geometry surfaces in a city data format, with attributes such as color, surface smoothness, reflectivity and transparency.”)
All I wanted to know is how this information will help our clients rank better in local SERPs.
Spoiler alert: I’m still not sure, but I have some thoughts/questions.
First, here are some common observations about the data that “may be a thing” that have been popping up around the web:
- Chrome browser behavior.
- “Toxic” backlinks.
- Google may limit the number of different types of sites that appear in a given search result.
- “Mentions” (a.k.a. “citations”) of your site on other sites.
- Topic authority.
- Clicks on your URL in search results affect rankings.
- Authorship.
- You may have to update a page 20 times before Google considers it a true refresh.
There are potentially thousands of other factors, so let’s get to the point. Is there anything in there that can help us improve our local SEO?
Below are some ill-formed thoughts for you all to chew on.
1. Video, video, video!
This isn’t really a “local SEO” tip, but thus far, it’s the most actionable thing I have found – or at least I think it is. Here’s what the docs said about video:
- isVideoFocusedSite: Bit to determine whether the site has mostly video content but is not hosted on known video-hosting domains. The site is considered to be video-focused if it has > 50% of the URLs with watch pages.
People seem to like video, right? Anecdotally, we have noticed video results increasing in search results across virtually every vertical we work in.
For example, here is the presence of video in SERPs according to Semrush for non-brand keywords for RotoRooter.com:
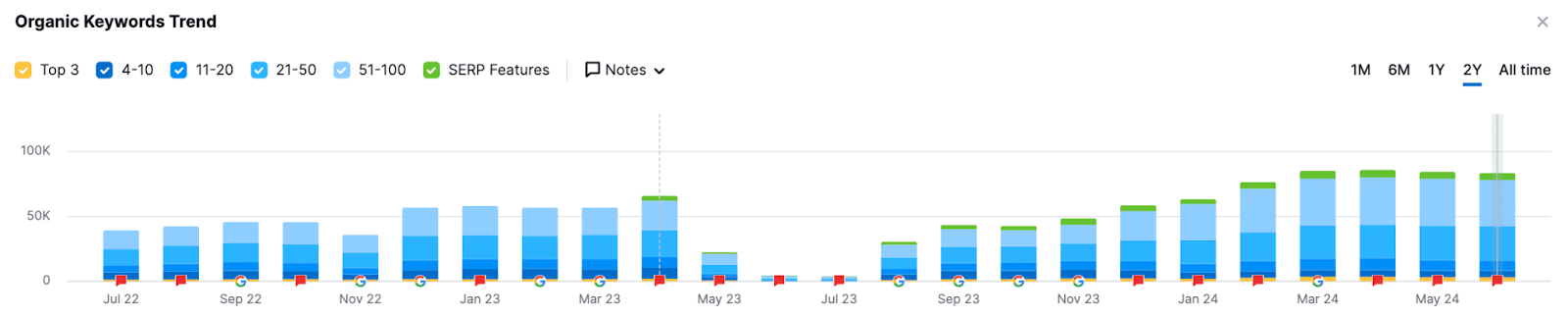
So, if you want to be considered for a video slot on a SERP, I’m guessing you’d want to be classified as an isVideoFocusedSite.
Here’s the “local” part: most local SMB sites are small. It seems to me that you could quickly turn a five-page site into a video-classified site by adding five quick selfie videos on their own pages.
Google seems to be picky about what it classifies as a video page.
For example, if you’re a veterinarian, you could do a selfie vid on how to brush your cat’s teeth, how often to schedule a wellness exam for your dog, etc. You’d have to self-host them or find an off-brand video hosting domain. Hit me up if you know of any.
By the way, “geolocation” is listed as an attribute in this document about meta information extracted from a video file, so it couldn’t hurt to make sure your video has your location in the meta information.
2. Are local bot clicks ‘CRAP’?
If you’ve been involved in local SEO for a while, you’re likely aware of various services that use bots to simulate location-based searches and click on your results, aiming to boost your local pack rankings by enhancing your “prominence” signal.
While much has been made of Rand Fishkin’s years-old proof that clicks matter for non-local SERPs, I don’t think I have seen anyone really talk about it publicly for local packs.
That’s why QualityNavboostCrapsCrapsClickSignals.t, which is defined as “CRAPS signal for the locale,” caught my eye.
CRAPs stands for, I think, “click and results prediction system.” This suggests that a specific location could have a specific score for how clicks on results affect rankings. If so, how could you tell what that score is?
The first thing that comes to mind is to run a bunch of local bot clicks on competitor businesses for a number of different related queries (vet near me, animal hospital, dog vaccines in Pleasanton, etc.) and see how many clicks it takes to move the rankings.
Test it periodically to see how it changes over time or on different days. Once you have hit on a formula that seems to work, apply it to your site.
Note that this is likely 100% against Google’s TOS, so I am not advocating you do this. I’m just reading the tea leaves.
3. Local authority vs. topic authority
We typically can boil down local SEO to a combination of proximity (are you near the searched area?), prominence (are you “good enough” to show up for this query?) and relevance (are you relevant to the query?).
This API doc on NSR (likely “normalized site rank”) references:
- titlematchScore which is “score the site, a signal that tells how well titles are matching user queries.”
- localityScore which is a “component of the LocalAuthority signal.”
In theory, if you have titles throughout your site that are relevant to the user queries (a.k.a. “relevance”) + a strong localityScore (a.k.a. “proximity”), you should have a decent shot at good local rankings, assuming you are prominent enough.
Typically, you can’t do much about proximity other than perhaps create location pages and get reviews that mention the location.
For the purposes of this thought exercise, let’s assume your locationScore is fixed. That means playing around with the title tags across the site could yield results. What do I mean by “playing around”?
Let’s assume you rank third for “SEO Company Pleasanton” in the local pack. If you crawl the sites of the first two businesses, you can see that about 10% of the title tags on each site target some version of this query.
So, what if we updated the titles on our site so that 20% of the titles hit the titlematchScore? Could that improve our local rankings? Maybe it’s just for the organic results and not the local pack? Seems really easy to test. I think I know what I’m doing tomorrow.
4. LSAs vs. Google Ads?
Fishkin recently pondered,
- “If Chrome click stream data is used for rankings, does that mean paid clicks could boost organic rankings?”
Let’s assume for the moment this is, in fact, how it works. If that’s the case, another question would be which ad unit is most effective for moving the rankings needle.
In local search, we have your standard PPC ads, but we also have Google Local Service Ads (LSAs), which show up above local packs and other local “surfaces.”
It seems to me it would be pretty straightforward to test different ad units against rankings and organic clicks.
Actually, that might cost you some money, so better yet, how about tracking some competitors who are spending a lot of money on these and seeing how their rankings change/don’t change?
5. Twiddle with local results
Mike King has this to say about Twiddlers:
- “Twiddlers can offer category constraints, meaning diversity can be promoted by specifically limiting the type of results. For instance the author may decide to only allow 3 blog posts in a given SERP. This can clarify when ranking is a lost cause based on your page format.”
SEOs have long focused on the intent of a query by examining the types of results on the SERPs. So perhaps this whole Twiddlers thing aligns with the chorus of the “nothing new here”-niks.
That said, this turned a lightbulb on for me on our approach. A common result of a local intent check is that an organic SERP has a few local businesses and business directories (e.g., Yelp, Angi, Forbes, etc.).
Instead of worrying about how hard it is to compete with sites like Yelp, I now think, “There are only three directories in this search result. How can my local business become one of them?”
This is no knock against Yelp or any of its ilk, but what is that site at its core besides a list of businesses and content about them?
If I were a local accountant, it wouldn’t be hard to put together a page on my domain or a new one about great local accountants in my city, and I am – for some reason – listed number one. (Not sure how that happened, but I’ll take it.  )
)
This has been a go-to B2B play for years. No reason why a local business couldn’t do the same.
Some attributes I want to know more about
This IndexingDocjoinerDataVersion doc has some fairly intriguing Attribute names listed. I have no idea what they are, but it seems like several of these may play a big part in local SERPs:
- localyp (Perhaps how they classify local business directory sites?)
- localsearchAuthoritySiteAnnotation (As in “this site is an authority for this location”?)
- qualityGeoBrainlocGoldmineBrainlocAnnotation (I am pretty sure GeoBrain is Google’s list of popular locations. Goldmine seems like it would be a list of advertisers?
- indexingDupsLocalizedLocalizedCluster (Dedupes results based on the searched geo?)
- imageRepositoryGeolocation (It has been a long time since we have seen geotagging images have any effect on local rankings, but it still makes sense for Google to store these in order to show them for specific types of queries.)
- knowledgeMiningFactsLocalizedFact (If a fact has a local source/application, show the local version of it instead of the “national” version?)
- tofu (Defined as the “URL-level tofu prediction,” this may be the key to the entire Google algorithm. It probably isn’t. I just couldn’t resist mentioning it.)
I’m trying really hard not to end on a “nothing actionable but happy testing” note. Ultimately, I guess I am no different than any other SEO guru wannabe.
Oh, yeah. I forgot to mention that the whole “mentions” thing could mean local business citations for “third-tier” directories still may be helpful for rankings. But I’ll let a listings management company jump into that can of worms.
Hopefully, I have given you some ideas to mess around with. Have fun!
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
How the Google leak confirms the significance of author and publisher entities in SEO
Written on June 6, 2024 at 9:44 pm, by admin

The May 2024 Google leak has shed light on the growing importance of author and publisher entities in SEO.
This article explains how the Google leak confirms that the search engine can identify content creators and website owners. It also shows why this is a great opportunity for SEOs to optimize author and publisher entities in their strategies.
Expanding SEO: Beyond websites to publishers and authors
For over 30 years, SEO has focused on website and content-level optimization.
We can keep that. It is valuable and it works.
However, SEO needs to add two new layers of optimization:
- The website owner (publisher).
- The content creator (author).
This allows Google to assess each related entity and gives Google confidence in the brand, so it awards each entity a kgmid, and a place in Google’s Knowledge Graph – the cornerstone of search and generative AI.
Since 2015, I have optimized thousands of website entities, website owner entities and author entities to create Knowledge Panels and optimize brand SERPs (the search results for a brand name search).
Google identifies and assesses the credibility of the content, the entity behind the website and the content creators on the website.
How do I know? I have the data.
The Google leak does not list ranking factors or machine learning elements that drive Google Knowledge algorithms. Still, it reinforces what I see daily – that Google’s algorithms successfully detect and evaluate the credibility of website owners and content creators.
And this is an enormous opportunity for SEO.
A new three-tiered approach to SEO
Tier 1: Optimizing website content with traditional SEO
Continue to focus on website-level optimization – technical SEO, links and content. This will drive traffic to the website and convert visitors.
The two tiers below provide a holistic SEO strategy that will thrive and survive in generative AI results and contribute to the wider business digital marketing objective of acquiring clients and making sales.
Tier 2: Optimizing the website owner (publisher)
Google leak: isPublisher
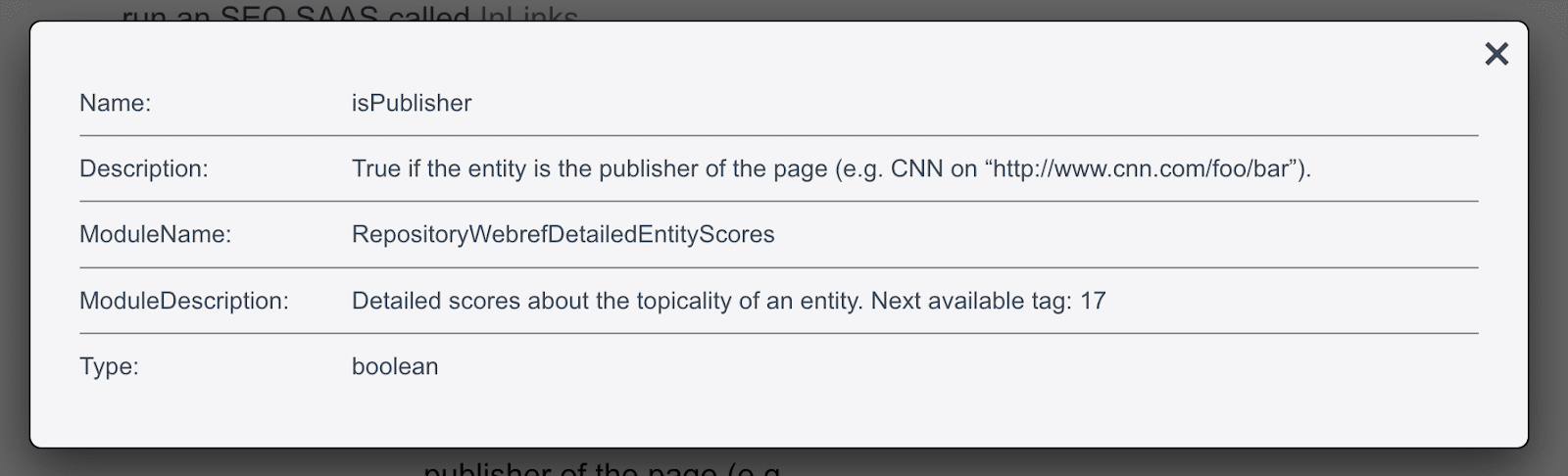 The screenshots of the documents are thanks to Dixon Jones from InLinks, who provides a great resource for searching and displaying the documentation
The screenshots of the documents are thanks to Dixon Jones from InLinks, who provides a great resource for searching and displaying the documentation The isPublisher element in the leak corresponds directly to the Search Quality Rater guidelines changes between December 2022 and September 2023.
Mentions of “website” were replaced by “website owner” (a.k.a. publisher). There are now 20 mentions of “website owner.”
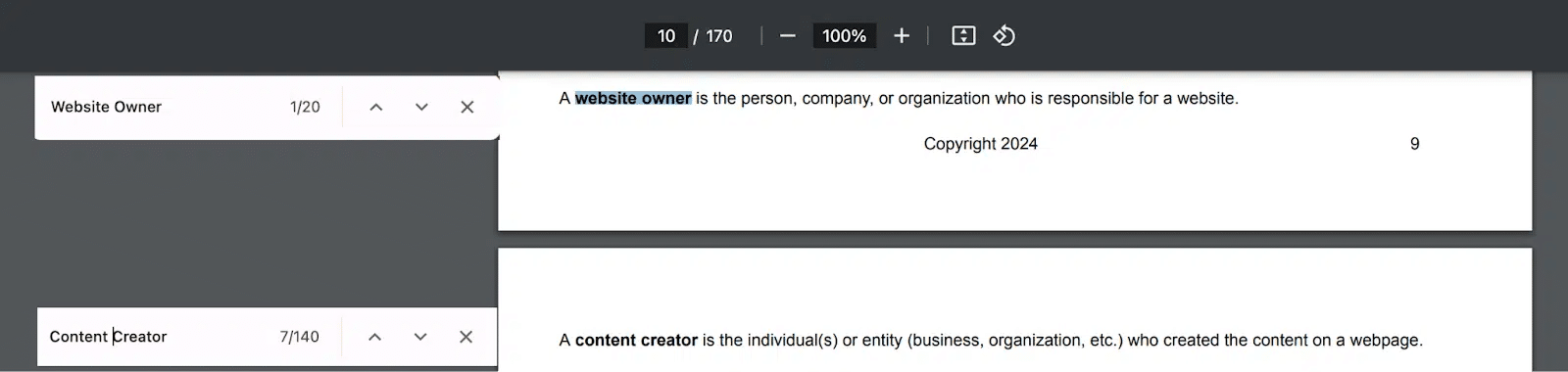
This website owner entity is the “guarantor” of the content, standing firmly behind it. Who is putting their reputation on the line by publishing this? Is that entity trustworthy?
Note: The publisher will often be an organization (including a corporation, local business or educational organization), but it can also be a person. In this article, I am assuming a corporation.
The isPublisher variable is boolean, so the game is zero-sum. The algorithms understand who the publisher is, or they don’t. If they don’t, Google loses confidence in the website and content because it doesn’t understand who has their reputation on the line.
Optimizing for website owner/publisher entities
Step 1 of tier 2: Understandability
Understandability is the foundation of website owner optimization. Without this, the rest won’t work. You absolutely cannot skip this step.
Educate Google’s knowledge algorithms so that they understand the entity that published the content: who they are, what they offer and who they serve.
Focus on the clarity, consistency and accuracy of all information on the entity home and company profiles, creating an infinite loop of self-corroboration. Google identifies isReferencePage for entities, which is similar to sameAs and subjectOf in schema markup.

Your KPI in step 1 is obtaining a kgmid in Google’s Knowledge Graphs for your website owner entity. Once you have a kgmid, you have started your entity optimization.
 A corporate entity in Google’s Knowledge Graph
A corporate entity in Google’s Knowledge GraphBut don’t stop there. Keep building confidence in Google’s understanding. Confidence is key.
Google is more likely to prioritize entities when it is confident it understands who they are, what they offer and which audience they serve.
Expand the footprint with references on relevant second and third-party websites to build confidence in understanding.
Google identifies reference pages from all across the web with the website owner entity through inbound links, explicit mentions and even implicit mentions, as these variables show.

Your KPIs for confidence in understanding will combine the items listed below.
- The confidence score in Google’s Knowledge Graph. (WordLift’s score of 197 in the screenshot above is solid.)
- The stability of a Knowledge Panel (when it 100% reliably triggers on a brand SERP).
- The entity home is displayed in the Knowledge Panel.
- The presence of related entities in the Knowledge Panel, such as a People Also Search For section.
Step 2 of tier 2: Credibility
Google refers to credibility as E-E-A-T. At my company, we use an extended version: N-E-E-A-T-T (adding Notability and Transparency, both vital to entity optimization).
Demonstrating N-E-E-A-T-T credibility requires that you communicate the following things to Google.
- Notability: The company is a recognized market leader cited by multiple leading resources inside the industry (and, where possible, generalist resources such as major media sites, Wikipedia, etc).
- Experience: The company has visible, historical and recognized involvement in the topic.
- Expertise: The company provides topical content that aligns with generally industry-accepted facts across owned sites, social platforms and third-party sites. The content provides relevant solutions to common problems faced by the target audience.
- Authoritativeness: The company has mentions and links back to its Entity Home from multiple relevant authoritative websites. It has recent and historical relationships with market-leading companies and influential people in the industry.
- Trustworthiness: The company is regularly cited positively by leading industry resources and the target audience (clients and users) on forums and across the web.
- Transparency: The company provides clear, up-to-date and accurate information about itself and its products on its website and across the web. It interacts openly and clearly with users and clients web-wide.
Your work as an SEO is to use traditional SEO tactics to ensure that this information is discoverable for Google and provided in a format that Google can digest easily and analyze confidently.
Don’t focus only on the company’s website. You must look wider and work on second-party websites such as social media platforms, profile pages and review sites (see isReferencePage above).
Your KPIs for credibility will be a combination of the following things.
- The quality (information-richness) of a Knowledge Panel.
- The number, relevancy and confidence scores for related entities in the Knowledge Graph. WordLift has 345 entity associations in the example above (but be wary when too many are irrelevant).
- The quality and richness of the brand SERP.
- The quality and richness of SERPs for queries that include the company name.
Step 3 of tier 2: Deliverability
Deliverability is not directly the responsibility of SEO, but a marketing, funnel and acquisition strategy.
It ensures your content is strategically placed across the right online platforms to reach your target audience. Having the right content on the right platforms for the right audience across the entire market digital ecosystem.
Ideally, the company achieves omnipresence for its ideal client and shows up everywhere when looking for solutions to their problems.
SEO is essential in supporting work by “packaging” this content for Google to understand.
Your KPIs for deliverability will be a combination of the following things.
- Brand search volume.
- Brand SERP click-through rate.
- Positive sentiment and accuracy of assistive engine descriptions (ChatGPT, Bing Copilot, Google Gemini, etc.)
- A presence in the top and middle of the funnel results.
- Proto-measurements in search and assistive AI results.
Dig deeper: Modern SEO: Packaging your brand and marketing for Google
Tier 3: Optimizing the content creator (author)
Google leak: isAuthor

Like isPublisher, isAuthor corresponds directly to the Search Quality Rater Guidelines changes between December 2022 and September 2023 when mentions of content creator (author) escalated. The guidelines mention content creator 140 times.

The content creator entity is responsible for the information in the content and stands behind it. Google wants to know who is creating the content and whether they are trustworthy.
The isAuthor variable is boolean, so the game is zero-sum. The algorithms understand who the content creator is. Or they don’t. If they don’t, you aren’t even in the game for tier 3.
Optimizing for content creator/author entities
The three-step process for a website owner/publisher I described above works similarly for a personal entity and personal brand strategy, so I won’t repeat everything here; I’ll just identify different aspects.
Step 1 of tier 3: Understandability
Google’s knowledge algorithms have been focusing almost exclusively on person entities since the first Killer Whale Update in July 2023, so getting a place in the Knowledge Graph and triggering a Knowledge Panel is significantly easier for a person than a company.
The process is the same. Create an infinite loop of self-corroboration.
- Identify an entity home.
- Make all references to the person clear, accurate and consistent across the web.
- Link from the entity home to the corroborative source and back to the entity home.
Your KPIs for confidence in understanding will be the same as for the website owner/publisher/corporation entity.
Step 2 of tier 2: Credibility
You need to be transparent to demonstrate to the algorithms that the content creator is an expert, has experience and is authoritative and trustworthy.
If you want to be at the top of the results, you must make that entity notable in its field. This is niche notability. Trusted and famous in a niche beats trusted every day of the week.
That is how you can get an author or person entity to the top of an entity list like this:
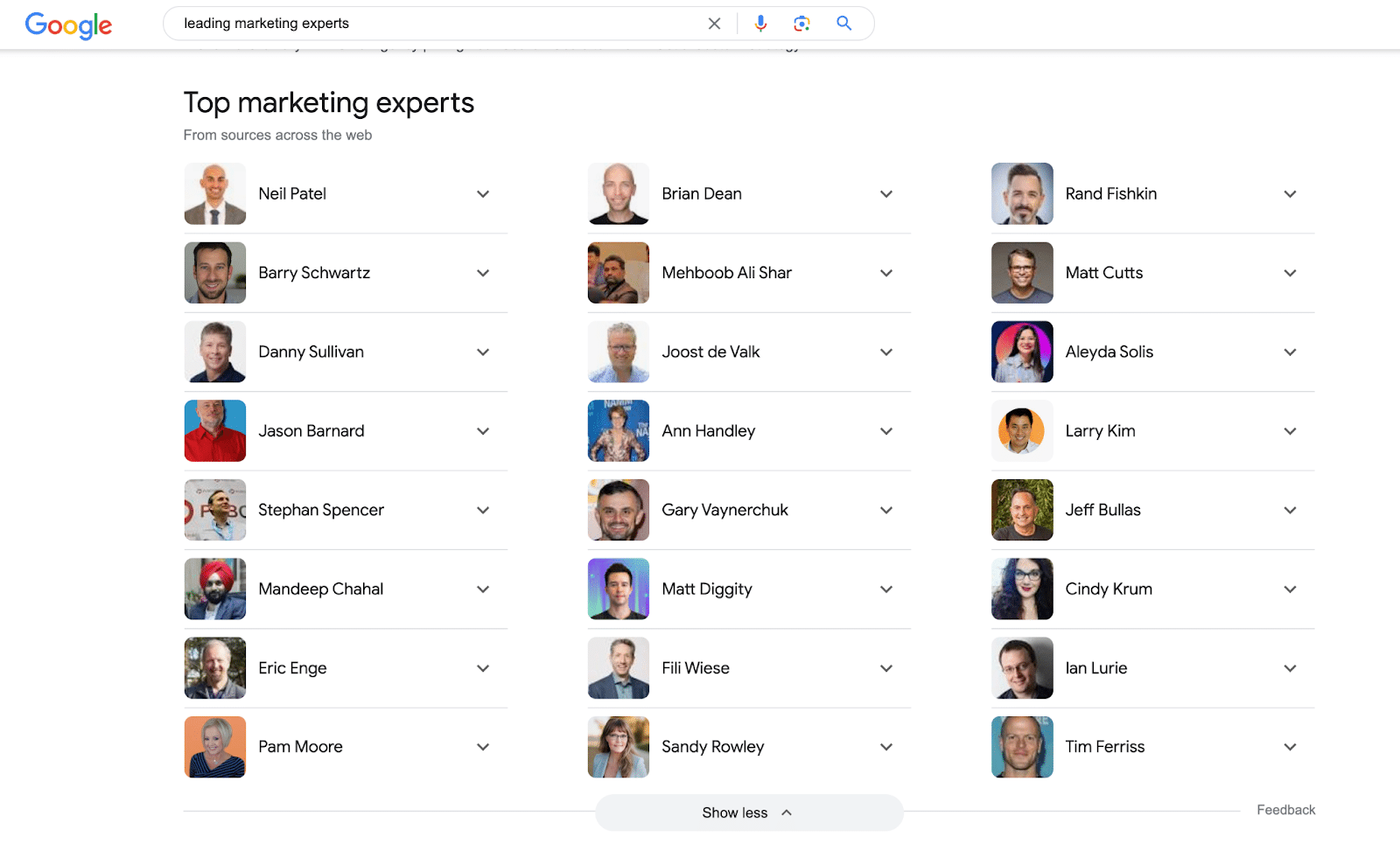
Your KPIs for confidence in credibility will be the same as for the website owner/corporation entity.
Step 3 of tier 2: Deliverability
Optimizing an author entity or a personal brand means maintaining a consistent presence wherever the audience may be online. The message and content are distributed across the digital landscape to engage with the target audience.
By aligning their content with the platforms the author or person’s ideal audience naturally uses, the person shows up at every stage of their online journey, offering insights, solutions, or services related to their interests and needs.
Deliverability is not SEO’s direct remit. SEO leverages maximum value from digital content assets wherever they appear online by ensuring they are discoverable, digestible and attractive to Google.
Your KPIs for deliverability will be the same as for the website owner/corporation entity.
Incorporating author and publisher entity optimization into your SEO strategy
The May 2024 Google leak is a definitive signal for SEOs and business leaders to embrace an expanded approach to optimization.
By recognizing the importance of entities – specifically authors and publishers – you must adapt your strategies to align with Google’s evolving ability to understand the world and evaluate the credibility and authority of the players.
The traditional focus on website and content optimization remains the essential foundation, but adding entity optimization at both the publisher and author levels is vital.
The three-tiered entity optimization strategy – encompassing understanding, credibility and deliverability – ensures that you are not just optimizing for search engines but establishing a clear identity for all related entities within the relevant market’s digital ecosystem.
As you progress with your SEO efforts, remember that it’s no longer just about climbing SERP rankings; it’s about building trust with users and search engines through insightful entity optimization.
This holistic approach will future-proof your SEO and provide greater visibility, user engagement, and, ultimately, sales and revenue for your company or clients.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Google sued by publishers over alleged pirate textbook promotion
Written on June 5, 2024 at 6:44 pm, by admin

Major educational publishers — Cengage, Macmillan Learning, McGraw Hill and Elsevier — have filed a lawsuit against Google, accusing it of promoting pirated copies of their textbooks.
Why it matters. This case could reshape how tech giants handle copyright infringement and impact the $8.3 billion U.S. textbook market.
Why we care. Advertisers will care about this lawsuit because it strikes at the heart of ad integrity and fair competition. If the allegations are true — that Google promotes pirated textbooks while restricting ads for legitimate ones – it suggests the tech giant may not be providing a level playing field or ensuring brand safety.
Details.
- Filed in the U.S. District Court, Southern District of New York
- Google accused of ignoring thousands of infringement notices
- Pirated e-books allegedly featured at the top of search results
- Publishers claim Google restricts ads for licensed e-books
By the numbers. Pirated textbooks are often sold at artificially low prices, undercutting legitimate sellers.
What they’re saying. “Google has become a thieves’ den for textbook pirates,” Matt Oppenheim, the publishers’ attorney, told Reuters.
- Google hasn’t commented on the lawsuit.
What’s next. The case (No. 1:24-cv-04274) seeks unspecified monetary damages.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Google Ads inviting some advertisers to join Advisors Community
Written on June 5, 2024 at 6:44 pm, by admin

Google Ads is inviting select customers to join its Advisors Community, offering a rare chance to directly influence its products and services.
Why it matters. This move signals Google’s push for more customer-centric product development, potentially shaping the future of digital advertising.
Why we care. Advertisers have seen many updates to Google products that have been seriously lacking in effectiveness. Many advertisers request being part of the discussion before an update is launched. This may be the answer to their long-running concerns.
Details.
- Members provide brief monthly feedback (max 4 surveys, ~5 mins each)
- Opportunity to impact unreleased products
- Quarterly updates on how feedback is used
How to join. If you see this communication in your inbox, fill out a quick, confidential questionnaire via third-party provider Alida.
Between the lines. By involving customers early, Google aims to better align its tools with user needs, possibly to maintain its dominance in the competitive ad tech space.
Reaction. I first saw this on Google Ads Consultant, Boris Beceric’s LinkedIn profile. When asked to comment, Beceric said:
- “I welcome the opportunity to have a more direct way of giving feedback to Google. I know they are listening (e.g. they gave us more control & reporting for Performance Max), but sometimes it is just so frustrating to be seeing things in the accounts that are opaque for no good reason. Criticizing on social media is not really going to move the needle in advertiser’s favor, so I think we need to take these opportunities when they are presented to us.”
What to watch. How much Google actually incorporates user feedback and whether this improves Google Ads products.
The email. Here’s a screenshot of the email Beceric shared on LinkedIn:

Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.