Microsoft Advertising Network for retail launches in the US
Written on September 26, 2023 at 9:57 am, by admin
Microsoft Advertising Network for retail has been rolled out in the US.
The network has been designed to simplify the process of creating retail media campaigns, making it easier for brands to launch their retail media programs faster by:
- Connecting retailers with a large, relevant pool of demand.
- Expanding their reach offsite, driving traffic to their websites at no cost through co-branded ads.
- Providing an additional buying path.
Microsoft has not yet confirmed when the network will be expanded to additional markets.
Why we care. Creating a retail media program is typically time-consuming and resource-intensive, involving multiple teams and can take a long time to become profitable. The Microsoft Advertising Network for retail streamlines this process, enabling retailers to launch profitable programs quickly and access relevant advertiser budgets from Microsoft Advertising’s extensive network.
What is Microsoft Advertising Network for retail? Microsoft Advertising Network for Retail is a new program that lets advertisers use Microsoft’s wide-reaching ad resources and access high-intent shoppers to boost their business. By joining the network, you can potentially increase sales and retail media revenue with quality ads, even if you have a private retail media platform.
Get the daily newsletter search marketers rely on.
<input type=”hidden” name=”utmMedium” value=”“>
<input type=”hidden” name=”utmCampaign” value=”“>
<input type=”hidden” name=”utmSource” value=”“>
<input type=”hidden” name=”utmContent” value=”“>
<input type=”hidden” name=”pageLink” value=”“>
<input type=”hidden” name=”ipAddress” value=”“>
Processing…Please wait.
What has Microsoft said? Paul Longo, Global Head of Retail Media Sales at Microsoft, said in a statement:
- “We have deep learning of the retailer experience across Microsoft, so with Microsoft Advertising Network for retail, we minimized the efforts for retailers of all sizes to begin immediately generating retail media revenue and increasing their onsite sales.”
Deep dive. Read the Microsoft Advertising blog for more information.
The post Microsoft Advertising Network for retail launches in the US appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Microsoft Advertising Network for retail launches in the US
Written on September 26, 2023 at 9:57 am, by admin
Microsoft Advertising Network for retail has been rolled out in the US.
The network has been designed to simplify the process of creating retail media campaigns, making it easier for brands to launch their retail media programs faster by:
- Connecting retailers with a large, relevant pool of demand.
- Expanding their reach offsite, driving traffic to their websites at no cost through co-branded ads.
- Providing an additional buying path.
Microsoft has not yet confirmed when the network will be expanded to additional markets.
Why we care. Creating a retail media program is typically time-consuming and resource-intensive, involving multiple teams and can take a long time to become profitable. The Microsoft Advertising Network for retail streamlines this process, enabling retailers to launch profitable programs quickly and access relevant advertiser budgets from Microsoft Advertising’s extensive network.
What is Microsoft Advertising Network for retail? Microsoft Advertising Network for Retail is a new program that lets advertisers use Microsoft’s wide-reaching ad resources and access high-intent shoppers to boost their business. By joining the network, you can potentially increase sales and retail media revenue with quality ads, even if you have a private retail media platform.
Get the daily newsletter search marketers rely on.
<input type=”hidden” name=”utmMedium” value=”“>
<input type=”hidden” name=”utmCampaign” value=”“>
<input type=”hidden” name=”utmSource” value=”“>
<input type=”hidden” name=”utmContent” value=”“>
<input type=”hidden” name=”pageLink” value=”“>
<input type=”hidden” name=”ipAddress” value=”“>
Processing…Please wait.
What has Microsoft said? Paul Longo, Global Head of Retail Media Sales at Microsoft, said in a statement:
- “We have deep learning of the retailer experience across Microsoft, so with Microsoft Advertising Network for retail, we minimized the efforts for retailers of all sizes to begin immediately generating retail media revenue and increasing their onsite sales.”
Deep dive. Read the Microsoft Advertising blog for more information.
The post Microsoft Advertising Network for retail launches in the US appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
What is generative AI and how does it work?
Written on September 26, 2023 at 9:57 am, by admin
Generative AI, a subset of artificial intelligence, has emerged as a revolutionary force in the tech world. But what exactly is it? And why is it gaining so much attention?
This in-depth guide will dive into how generative AI models work, what they can and can’t do, and the implications of all these elements.
What is generative AI?
Generative AI, or genAI, refers to systems that can generate new content, be it text, images, music, or even videos. Traditionally, AI/ML meant three things: supervised, unsupervised, and reinforcement learning. Each gives insights based on clustering output.
Non-generative AI models make calculations based on input (like classifying an image or translating a sentence). In contrast, generative models produce “new” outputs such as writing essays, composing music, designing graphics, and even creating realistic human faces that don’t exist in the real world.
The implications of generative AI
The rise of generative AI has significant implications. With the ability to generate content, industries like entertainment, design, and journalism are witnessing a paradigm shift.
For instance, news agencies can use AI to draft reports, while designers can get AI-assisted suggestions for graphics. AI can generate hundreds of ad slogans in seconds – whether or not those options are good or not is another matter.
Generative AI can produce tailored content for individual users. Think of something like a music app that composes a unique song based on your mood or a news app that drafts articles on topics you’re interested in.
The issue is that as AI plays a more integral role in content creation, questions about authenticity, copyright, and the value of human creativity become more prevalent.
How does generative AI work?
Generative AI, at its core, is about predicting the next piece of data in a sequence, whether that’s the next word in a sentence or the next pixel in an image. Let’s break down how this is achieved.
Statistical models
Statistical models are the backbone of most AI systems. They use mathematical equations to represent the relationship between different variables.
For generative AI, models are trained to recognize patterns in data and then use these patterns to generate new, similar data.
If a model is trained on English sentences, it learns the statistical likelihood of one word following another, allowing it to generate coherent sentences.
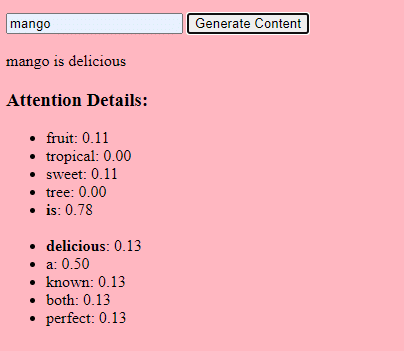
 Basic demo of how text is selected from an LLM
Basic demo of how text is selected from an LLMData gathering
Both the quality and quantity of data are crucial. Generative models are trained on vast datasets to understand patterns.
For a language model, this might mean ingesting billions of words from books, websites, and other texts.
For an image model, it could mean analyzing millions of images. The more diverse and comprehensive the training data, the better the model will generate diverse outputs.
How transformers and attention work
Transformers are a type of neural network architecture introduced in a 2017 paper titled “Attention Is All You Need” by Vaswani et al. They have since become the foundation for most state-of-the-art language models. ChatGPT wouldn’t work without transformers.
The “attention” mechanism allows the model to focus on different parts of the input data, much like how humans pay attention to specific words when understanding a sentence.
This mechanism lets the model decide which parts of the input are relevant for a given task, making it highly flexible and powerful.
The code below is a fundamental breakdown of transformer mechanisms, explaining each piece in plain English.
class Transformer:
# Convert words to vectors
# What this is: turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other.
# Demo: "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9]
self.embedding = Embedding(vocab_size, d_model)
# Add position information to the vectors
# What this is: Since words in a sentence have a specific order, we add information about each word's position in the sentence.
# Demo: "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06]
self.positional_encoding = PositionalEncoding(d_model)
# Stack of transformer layers
# What this is: Multiple layers of the Transformer model stacked on top of each other to process data in depth.
# Why it does it: Each layer captures different patterns and relationships in the data.
# Explained like I'm five: Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done!
self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)]
# Convert the output vectors to word probabilities
# What this is: A way to predict the next word in a sequence.
# Why it does it: After processing the input, we want to guess what word comes next.
# Explained like I'm five: After listening to a story, this tries to guess what happens next.
self.output_layer = Linear(d_model, vocab_size)
def forward(self, x):
# Convert words to vectors, as above
x = self.embedding(x)
# Add position information, as above
x = self.positional_encoding(x)
# Pass through each transformer layer
# What this is: Sending our data through each floor of our multi-story building.
# Why it does it: To deeply process and understand the data.
# Explained like I'm five: It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess.
for layer in self.transformer_layers:
x = layer(x)
# Get the output word probabilities
# What this is: Our best guess for the next word in the sequence.
return self.output_layer(x)
In code, you might have a Transformer class and a single TransformerLayer class. This is like having a blueprint for a floor vs. an entire building.
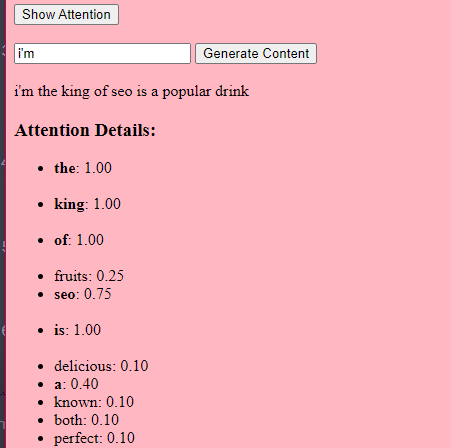
This TransformerLayer piece of code shows you how specific components, like multi-head attention and specific arrangements, work.
 Demonstration of how attention works using different colors
Demonstration of how attention works using different colorsclass TransformerLayer:
# Multi-head attention mechanism
# What this is: A mechanism that lets the model focus on different parts of the input data simultaneously.
# Demo: "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words.
self.attention = MultiHeadAttention(d_model, nhead)
# Simple feed-forward neural network
# What this is: A basic neural network that processes the data after the attention mechanism.
# Demo: "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing)
self.feed_forward = FeedForward(d_model)
def forward(self, x):
# Apply attention mechanism
# What this is: The step where we focus on different parts of the sentence.
# Explained like I'm five: It's like highlighting important parts of a book.
attention_output = self.attention(x, x, x)
# Pass the output through the feed-forward network
# What this is: The step where we process the highlighted information.
return self.feed_forward(attention_output)
A feed-forward neural network is one of the simplest types of artificial neural networks. It consists of an input layer, one or more hidden layers, and an output layer.
The data flows in one direction – from the input layer, through the hidden layers, and to the output layer. There are no loops or cycles in the network.
In the context of the transformer architecture, the feed-forward neural network is used after the attention mechanism in each layer. It’s a simple two-layered linear transformation with a ReLU activation in between.
# Scaled dot-product attention mechanism
class ScaledDotProductAttention:
def __init__(self, d_model):
# Scaling factor helps in stabilizing the gradients
# it reduces the variance of the dot product.
# What this is: A scaling factor based on the size of our model's embeddings.
# What it does: Helps to make sure the dot products don't get too big.
# Why it does it: Big dot products can make a model unstable and harder to train.
# How it does it: By dividing the dot products by the square root of the embedding size.
# It's used when calculating attention scores.
# Explained like I'm five: Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud.
self.scaling_factor = d_model ** 0.5
def forward(self, query, key, value):
# What this is: The function that calculates how much attention each word should get.
# What it does: Determines how relevant each word in a sentence is to every other word.
# Why it does it: So we can focus more on important words when trying to understand a sentence.
# How it does it: By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values.
# How it fits into the rest of the code: This function is called whenever we want to calculate attention in our model.
# Explained like I'm five: Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers.
# Calculate attention scores by taking the dot product of the query and key.
scores = dot_product(query, key) / self.scaling_factor
# Convert the raw scores to probabilities using the softmax function.
attention_weights = softmax(scores)
# Weight the values using the attention probabilities.
return dot_product(attention_weights, value)
# Feed-forward neural network
# This is an extremely basic example of a neural network.
class FeedForward:
def __init__(self, d_model):
# First linear layer increases the dimensionality of the data.
self.layer1 = Linear(d_model, d_model * 4)
# Second linear layer brings the dimensionality back to d_model.
self.layer2 = Linear(d_model * 4, d_model)
def forward(self, x):
# Pass the input through the first layer,
#Pass the input through the first layer:
# Input: This refers to the data you feed into the neural network. I
#First layer: Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output.
# apply ReLU activation to introduce non-linearity,
# and then pass through the second layer.
#ReLU activation: ReLU stands for Rectified Linear Unit.
# It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero.
# Neural networks can model complex relationships in data by introducing non-linearities.
# Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model.
# Non-linearities allow the network to capture complex patterns and make better predictions.
return self.layer2(relu(self.layer1(x)))
# Positional encoding adds information about the position of each word in the sequence.
class PositionalEncoding:
def __init__(self, d_model):
# What this is: A setup to add information about where each word is in a sentence.
# What it does: Prepares to add a unique "position" value to each word.
# Why it does it: Words in a sentence have an order, and this helps the model remember that order.
# How it does it: By creating a special pattern of numbers for each position in a sentence.
# How it fits into the rest of the code: Before processing words, we add their position info.
# Explained like I'm five: Imagine you're in a line with your friends. This gives everyone a number to remember their place in line.
pass
def forward(self, x):
# What this is: The main function that adds position info to our words.
# What it does: Combines the word's original value with its position value.
# Why it does it: So the model knows the order of words in a sentence.
# How it does it: By adding the position values we prepared earlier to the word values.
# How it fits into the rest of the code: This function is called whenever we want to add position info to our words.
# Explained like I'm five: It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on.
return x
# Helper functions
def dot_product(a, b):
# Calculate the dot product of two matrices.
# What this is: A mathematical operation to see how similar two lists of numbers are.
# What it does: Multiplies matching items in the lists and then adds them up.
# Why it does it: To measure similarity or relevance between two sets of data.
# How it does it: By multiplying and summing up.
# How it fits into the rest of the code: Used in attention to see how relevant words are to each other.
# Explained like I'm five: Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have.
return a @ b.transpose(-2, -1)
def softmax(x):
# Convert raw scores to probabilities ensuring they sum up to 1.
# What this is: A way to turn any list of numbers into probabilities.
# What it does: Makes the numbers between 0 and 1 and ensures they all add up to 1.
# Why it does it: So we can understand the numbers as chances or probabilities.
# How it does it: By using exponentiation and division.
# How it fits into the rest of the code: Used to convert attention scores into probabilities.
# Explained like I'm five: Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind.
return exp(x) / sum(exp(x), axis=-1)
def relu(x):
# Activation function that introduces non-linearity. It sets negative values to 0.
# What this is: A simple rule for numbers.
# What it does: If a number is negative, it changes it to zero. Otherwise, it leaves it as it is.
# Why it does it: To introduce some simplicity and non-linearity in our model's calculations.
# How it does it: By checking each number and setting it to zero if it's negative.
# How it fits into the rest of the code: Used in neural networks to make them more powerful and flexible.
# Explained like I'm five: Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones.
return max(0, x)
How generative AI works – in simple terms
Think of generative AI as rolling a weighted dice. The training data determine the weights (or probabilities).
If the dice represents the next word in a sentence, a word often following the current word in the training data will have a higher weight. So, “sky” might follow “blue” more often than “banana”. When the AI “rolls the dice” to generate content, it’s more likely to choose statistically more probable sequences based on its training.
So, how can LLMs generate content that “seems” original?
Let’s take a fake listicle – the “best Eid al-Fitr gifts for content marketers” – and walk through how an LLM can generate this list by combining textual cues from documents about gifts, Eid, and content marketers.
Before processing, the text is broken down into smaller pieces called “tokens.” These tokens can be as short as one character or as long as one word.
Example: “Eid al-Fitr is a celebration” becomes [“Eid”, “al-Fitr”, “is”, “a”, “celebration”].
This allows the model to work with manageable chunks of text and understand the structure of sentences.
Each token is then converted into a vector (a list of numbers) using embeddings. These vectors capture the meaning and context of each word.
Positional encoding adds information to each word vector about its position in the sentence, ensuring the model doesn’t lose this order information.
Then we use an attention mechanism: this allows the model to focus on different parts of the input text when generating an output. If you remember BERT, this is what was so exciting to Googlers about BERT.
If our model has seen texts about “gifts” and knows that people give gifts during celebrations, and it has also seen texts about “Eid al-Fitr” being a significant celebration, it will pay “attention” to these connections.
Similarly, if it has seen texts about “content marketers” needing specific tools or resources, it can connect the idea of “gifts” to “content marketers“.

Now we can combine contexts: As the model processes the input text through multiple Transformer layers, it combines the contexts it has learned.
So, even if the original texts never mentioned “Eid al-Fitr gifts for content marketers,” the model can bring together the concepts of “Eid al-Fitr,” “gifts,” and “content marketers” to generate this content.
This is because it has learned the broader contexts around each of these terms.
After processing the input through the attention mechanism and the feed-forward networks in each Transformer layer, the model produces a probability distribution over its vocabulary for the next word in the sequence.
It might think that after words like “best” and “Eid al-Fitr,” the word “gifts” has a high probability of coming next. Similarly, it might associate “gifts” with potential recipients like “content marketers.”
Get the daily newsletter search marketers rely on.
<input type=”hidden” name=”utmMedium” value=”“>
<input type=”hidden” name=”utmCampaign” value=”“>
<input type=”hidden” name=”utmSource” value=”“>
<input type=”hidden” name=”utmContent” value=”“>
<input type=”hidden” name=”pageLink” value=”“>
<input type=”hidden” name=”ipAddress” value=”“>
Processing…Please wait.
How large language models are built
The journey from a basic transformer model to a sophisticated large language model (LLM) like GPT-3 or BERT involves scaling up and refining various components.
Here’s a step-by-step breakdown:
LLMs are trained on vast amounts of text data. It’s hard to explain how vast this data is.
The C4 dataset, a starting point for many LLMs, is 750 GB of text data. That’s 805,306,368,000 bytes – a lot of information. This data can include books, articles, websites, forums, comment sections, and other sources.
The more varied and comprehensive the data, the better the model’s understanding and generalization capabilities.
While the basic transformer architecture remains the foundation, LLMs have a significantly larger number of parameters. GPT-3, for example, has 175 billion parameters. In this case, parameters refer to the weights and biases in the neural network that are learned during the training process.
In deep learning, a model is trained to make predictions by adjusting these parameters to reduce the difference between its predictions and the actual outcomes.
The process of adjusting these parameters is called optimization, which uses algorithms like gradient descent.
- Weights: These are values in the neural network that transform input data within the network’s layers. They are adjusted during training to optimize the model’s output. Each connection between neurons in adjacent layers has an associated weight.
- Biases: These are also values in the neural network that are added to the output of a layer’s transformation. They provide an additional degree of freedom to the model, allowing it to fit the training data better. Each neuron in a layer has an associated bias.
This scaling allows the model to store and process more intricate patterns and relationships in the data.
The large number of parameters also means that the model requires significant computational power and memory for training and inference. This is why training such models is resource-intensive and typically uses specialized hardware like GPUs or TPUs.
The model is trained to predict the next word in a sequence using powerful computational resources. It adjusts its internal parameters based on the errors it makes, continuously improving its predictions.
Attention mechanisms like the ones we’ve discussed are pivotal for LLMs. They allow the model to focus on different parts of the input when generating output.
By weighing the importance of different words in a context, attention mechanisms enable the model to generate coherent and contextually relevant text. Doing it at this massive scale enables the LLMs to work the way they do.
How does a transformer predict text?
Transformers predict text by processing input tokens through multiple layers, each equipped with attention mechanisms and feed-forward networks.
After processing, the model produces a probability distribution over its vocabulary for the next word in the sequence. The word with the highest probability is typically selected as the prediction.
How is a large language model built and trained?
Building an LLM involves gathering data, cleaning it, training the model, fine-tuning the model, and vigorous, continuous testing.
The model is initially trained on a vast corpus to predict the next word in a sequence. This phase allows the model to learn connections between words that pick up patterns in grammar, relationships that can represent facts about the world and connections that feel like logical reasoning. These connections also make it pick up biases present in the training data.
After pre-training, the model is refined on a narrower dataset, often with human reviewers following guidelines.
Fine-tuning is a crucial step in building LLMs. It involves training the pre-trained model on a more specific dataset or task. Let’s take ChatGPT as an example.
If you’ve played with GPT models, you know that prompting is less “write this thing” and more like
- Prompt: Once upon a time
- Continuation: There was an evil wizard at the top of a tower.
- Prompt: Why did the chicken join a band?
- Continuation: Because it had the drumsticks!
To get to ChatGPT from that point involves a lot of low-paid labor. Those people create immense corpora to put a finger on the weight of GPT responses and expected behaviors. These workers create tons of prompt/continuation texts that are like:
- Prompt: Finish this story: “Once upon a time..”
- Continuation: Sure! Once upon a time, in a land far, far away, there was a small village nestled between two majestic mountains.
- Prompt: Tell me a joke about a chicken.
- Continuation: Why did the chicken join a band? Because it had the drumsticks!
This fine-tuning process is essential for several reasons:
- Specificity: While pre-training gives the model a broad understanding of language, fine-tuning narrows its knowledge and behavior to align more with specific tasks or domains. For instance, a model fine-tuned on medical data will better answer medical questions.
- Control: Fine-tuning gives developers more control over the model’s outputs. Developers can use a curated dataset to guide the model to produce desired responses and avoid unwanted behaviors.
- Safety: It helps in reducing harmful or biased outputs. By using guidelines during the fine-tuning process, human reviewers can ensure the model doesn’t produce inappropriate content.
- Performance: Fine-tuning can significantly improve the model’s performance on specific tasks. For example, a model that’s been fine-tuned for customer support will be much better at it than a generic model.
You can tell ChatGPT has been fine-tuned in particular in some ways.
For example, “logical reasoning” is something LLMs tend to struggle with. ChatGPT’s best logical reasoning model – GPT-4 – has been trained intensely to recognize patterns in numbers explicitly.
Instead of something like this:
- Prompt: What’s 2+2?
- Process: Oftentimes in math textbooks for children 2+2 =4. Occasionally there are references to “2+2=5″ but there is usually more context to do with George Orwell or Star Trek when that is the case. If this was in that context the weight would be more in favor of 2+2=5. But that context doesn’t exist, so in this instance the next token is likely 4.
- Response: 2+2=4
The training does something like this:
- training: 2+2=4
- training: 4/2=2
- training: half of 4 is 2
- training: 2 of 2 is four
…and so on.
This means for those more “logical” models, the training process is more rigorous and focused on ensuring that the model understands and correctly applies logical and mathematical principles.
The model is exposed to various mathematical problems and their solutions, ensuring it can generalize and apply these principles to new, unseen problems.
The importance of this fine-tuning process, especially for logical reasoning, cannot be overstated. Without it, the model might provide incorrect or nonsensical answers to straightforward logical or mathematical questions.
Image models vs. language models
While both image and language models might use similar architectures like transformers, the data they process is fundamentally different:
Image models
These models deal with pixels and often work in a hierarchical manner, analyzing small patterns (like edges) first, then combining them to recognize larger structures (like shapes), and so on until they understand the entire image.
Language models
These models process sequences of words or characters. They need to understand the context, grammar, and semantics to generate coherent and contextually relevant text.
How prominent generative AI interfaces work
Dall-E + Midjourney
Dall-E is a variant of the GPT-3 model adapted for image generation. It’s trained on a vast dataset of text-image pairs. Midjourney is another image generation software that is based on a proprietary model.
- Input: You provide a textual description, like “a two-headed flamingo.”
- Processing: These models encode this text into a series of numbers and then decode these vectors, finding relationships to pixels, to produce an image. The model has learned the relationships between textual descriptions and visual representations from its training data.
- Output: An image that matches or relates to the given description.
Fingers, patterns, problems
Why can’t these tools consistently generate hands that look normal? These tools work by looking at pixels next to each other.
You can see how this works when comparing earlier or more primitive generated images with more recent ones: earlier models look very fuzzy. In contrast, more recent models are a lot crisper.
These models generate images by predicting the next pixel based on the pixels it has already generated. This process is repeated millions of times over to produce a complete image.
Hands, especially fingers, are intricate and have a lot of details that need to be captured accurately.
Each finger’s positioning, length, and orientation can vary greatly in different images.
When generating an image from a textual description, the model has to make many assumptions about the exact pose and structure of the hand, which can lead to anomalies.
ChatGPT
ChatGPT is based on the GPT-3.5 architecture, a transformer-based model designed for natural language processing tasks.
- Input: A prompt or a series of messages to simulate a conversation.
- Processing: ChatGPT uses its vast knowledge from diverse internet texts to generate responses. It considers the context provided in the conversation and tries to produce the most relevant and coherent reply.
- Output: A text response that continues or answers the conversation.
Specialty
ChatGPT’s strength lies in its ability to handle various topics and simulate human-like conversations, making it ideal for chatbots and virtual assistants.
Bard + Search Generative Experience (SGE)
While specific details might be proprietary, Bard is based on transformer AI techniques, similar to other state-of-the-art language models. SGE is based on similar models but weaves in other ML algorithms Google uses.
SGE likely generates content using a transformer-based generative model and then fuzzy extracts answers from ranking pages in search. (This may not be true. Just a guess based on how it seems to work from playing with it. Please don’t sue me!)
- Input: A prompt/command/search
- Processing: Bard processes the input and works the way other LLMs do. SGE uses a similar architecture but adds a layer where it searches its internal knowledge (gained from training data) to generate a suitable response. It considers the prompt’s structure, context, and intent to produce relevant content.
- Output: Generated content that can be a story, answer, or any other type of text.
Applications of generative AI (and their controversies)
Art and design
Generative AI can now create artwork, music, and even product designs. This has opened up new avenues for creativity and innovation.
Controversy
The rise of AI in art has sparked debates about job losses in creative fields.
Additionally, there are concerns about:
- Labor violations, especially when AI-generated content is used without proper attribution or compensation.
- Executives threatening writers with replacing them with AI is one of the issues that spurred the writers’ strike.
Natural language processing (NLP)
AI models are now widely used for chatbots, language translation, and other NLP tasks.
Outside the dream of artificial general intelligence (AGI), this is the best use for LLMs since they are close to a “generalist” NLP model.
Controversy
Many users find chatbots to be impersonal and sometimes annoying.
Moreover, while AI has made significant strides in language translation, it often lacks the nuance and cultural understanding that human translators bring, leading to impressive and flawed translations.
Medicine and drug discovery
AI can quickly analyze vast amounts of medical data and generate potential drug compounds, speeding up the drug discovery process. Many doctors already use LLMs to write notes and patient communications
Controversy
Relying on LLMs for medical purposes can be problematic. Medicine requires precision, and any errors or oversights by AI can have serious consequences.
Medicine also already has biases that only get more baked in using LLMs. There are also similar issues, as discussed below, with privacy, efficacy, and ethics.
Gaming
Many AI enthusiasts are excited about using AI in gaming: they say that AI can generate realistic gaming environments, characters, and even entire game plots, enhancing the gaming experience. NPC dialogue can be enhanced through using these tools.
Controversy
There’s a debate about the intentionality in game design.
While AI can generate vast amounts of content, some argue it lacks the deliberate design and narrative cohesion that human designers bring.
Watchdogs 2 had programmatic NPCs, which did little to add to the narrative cohesion of the game as a whole.
Marketing and advertising
AI can analyze consumer behavior and generate personalized advertisements and promotional content, making marketing campaigns more effective.
LLMs have context from other people’s writing, making them useful for generating user stories or more nuanced programmatic ideas. Instead of recommending TVs to someone who just bought a TV, LLMs can recommend accessories someone might want instead.
Controversy
The use of AI in marketing raises privacy concerns. There’s also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they’ve seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model’s last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a “common sense” understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they’ve seen. While they can combine these patterns in novel ways, they don’t “invent” like humans do. Their “creativity” is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration: Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn’t real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush,” people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there’s no guarantee they’ll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don’t know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they’re essentially regurgitating and recombining what they’ve seen before. They don’t “invent” in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it’s hard for LLMs to deal with it.
 This didn’t happen, but it is published online and is currently the top result for Megan Crosby.
This didn’t happen, but it is published online and is currently the top result for Megan Crosby.For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don’t know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can’t verify facts or discern true and false information.
If they’ve been exposed to misinformation or biased data during training, or they don’t have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it’s a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there’s a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that’s challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
The post What is generative AI and how does it work? appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
What is generative AI and how does it work?
Written on September 26, 2023 at 9:57 am, by admin
Generative AI, a subset of artificial intelligence, has emerged as a revolutionary force in the tech world. But what exactly is it? And why is it gaining so much attention?
This in-depth guide will dive into how generative AI models work, what they can and can’t do, and the implications of all these elements.
What is generative AI?
Generative AI, or genAI, refers to systems that can generate new content, be it text, images, music, or even videos. Traditionally, AI/ML meant three things: supervised, unsupervised, and reinforcement learning. Each gives insights based on clustering output.
Non-generative AI models make calculations based on input (like classifying an image or translating a sentence). In contrast, generative models produce “new” outputs such as writing essays, composing music, designing graphics, and even creating realistic human faces that don’t exist in the real world.
The implications of generative AI
The rise of generative AI has significant implications. With the ability to generate content, industries like entertainment, design, and journalism are witnessing a paradigm shift.
For instance, news agencies can use AI to draft reports, while designers can get AI-assisted suggestions for graphics. AI can generate hundreds of ad slogans in seconds – whether or not those options are good or not is another matter.
Generative AI can produce tailored content for individual users. Think of something like a music app that composes a unique song based on your mood or a news app that drafts articles on topics you’re interested in.
The issue is that as AI plays a more integral role in content creation, questions about authenticity, copyright, and the value of human creativity become more prevalent.
How does generative AI work?
Generative AI, at its core, is about predicting the next piece of data in a sequence, whether that’s the next word in a sentence or the next pixel in an image. Let’s break down how this is achieved.
Statistical models
Statistical models are the backbone of most AI systems. They use mathematical equations to represent the relationship between different variables.
For generative AI, models are trained to recognize patterns in data and then use these patterns to generate new, similar data.
If a model is trained on English sentences, it learns the statistical likelihood of one word following another, allowing it to generate coherent sentences.
Basic demo of how text is selected from an LLMData gathering
Both the quality and quantity of data are crucial. Generative models are trained on vast datasets to understand patterns.
For a language model, this might mean ingesting billions of words from books, websites, and other texts.
For an image model, it could mean analyzing millions of images. The more diverse and comprehensive the training data, the better the model will generate diverse outputs.
How transformers and attention work
Transformers are a type of neural network architecture introduced in a 2017 paper titled “Attention Is All You Need” by Vaswani et al. They have since become the foundation for most state-of-the-art language models. ChatGPT wouldn’t work without transformers.
The “attention” mechanism allows the model to focus on different parts of the input data, much like how humans pay attention to specific words when understanding a sentence.
This mechanism lets the model decide which parts of the input are relevant for a given task, making it highly flexible and powerful.
The code below is a fundamental breakdown of transformer mechanisms, explaining each piece in plain English.
class Transformer:
# Convert words to vectors
# What this is: turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other.
# Demo: "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9]
self.embedding = Embedding(vocab_size, d_model)
# Add position information to the vectors
# What this is: Since words in a sentence have a specific order, we add information about each word's position in the sentence.
# Demo: "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06]
self.positional_encoding = PositionalEncoding(d_model)
# Stack of transformer layers
# What this is: Multiple layers of the Transformer model stacked on top of each other to process data in depth.
# Why it does it: Each layer captures different patterns and relationships in the data.
# Explained like I'm five: Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done!
self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)]
# Convert the output vectors to word probabilities
# What this is: A way to predict the next word in a sequence.
# Why it does it: After processing the input, we want to guess what word comes next.
# Explained like I'm five: After listening to a story, this tries to guess what happens next.
self.output_layer = Linear(d_model, vocab_size)
def forward(self, x):
# Convert words to vectors, as above
x = self.embedding(x)
# Add position information, as above
x = self.positional_encoding(x)
# Pass through each transformer layer
# What this is: Sending our data through each floor of our multi-story building.
# Why it does it: To deeply process and understand the data.
# Explained like I'm five: It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess.
for layer in self.transformer_layers:
x = layer(x)
# Get the output word probabilities
# What this is: Our best guess for the next word in the sequence.
return self.output_layer(x)
In code, you might have a Transformer class and a single TransformerLayer class. This is like having a blueprint for a floor vs. an entire building.
This TransformerLayer piece of code shows you how specific components, like multi-head attention and specific arrangements, work.
Demonstration of how attention works using different colorsclass TransformerLayer:
# Multi-head attention mechanism
# What this is: A mechanism that lets the model focus on different parts of the input data simultaneously.
# Demo: "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words.
self.attention = MultiHeadAttention(d_model, nhead)
# Simple feed-forward neural network
# What this is: A basic neural network that processes the data after the attention mechanism.
# Demo: "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing)
self.feed_forward = FeedForward(d_model)
def forward(self, x):
# Apply attention mechanism
# What this is: The step where we focus on different parts of the sentence.
# Explained like I'm five: It's like highlighting important parts of a book.
attention_output = self.attention(x, x, x)
# Pass the output through the feed-forward network
# What this is: The step where we process the highlighted information.
return self.feed_forward(attention_output)
A feed-forward neural network is one of the simplest types of artificial neural networks. It consists of an input layer, one or more hidden layers, and an output layer.
The data flows in one direction – from the input layer, through the hidden layers, and to the output layer. There are no loops or cycles in the network.
In the context of the transformer architecture, the feed-forward neural network is used after the attention mechanism in each layer. It’s a simple two-layered linear transformation with a ReLU activation in between.
# Scaled dot-product attention mechanism
class ScaledDotProductAttention:
def __init__(self, d_model):
# Scaling factor helps in stabilizing the gradients
# it reduces the variance of the dot product.
# What this is: A scaling factor based on the size of our model's embeddings.
# What it does: Helps to make sure the dot products don't get too big.
# Why it does it: Big dot products can make a model unstable and harder to train.
# How it does it: By dividing the dot products by the square root of the embedding size.
# It's used when calculating attention scores.
# Explained like I'm five: Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud.
self.scaling_factor = d_model ** 0.5
def forward(self, query, key, value):
# What this is: The function that calculates how much attention each word should get.
# What it does: Determines how relevant each word in a sentence is to every other word.
# Why it does it: So we can focus more on important words when trying to understand a sentence.
# How it does it: By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values.
# How it fits into the rest of the code: This function is called whenever we want to calculate attention in our model.
# Explained like I'm five: Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers.
# Calculate attention scores by taking the dot product of the query and key.
scores = dot_product(query, key) / self.scaling_factor
# Convert the raw scores to probabilities using the softmax function.
attention_weights = softmax(scores)
# Weight the values using the attention probabilities.
return dot_product(attention_weights, value)
# Feed-forward neural network
# This is an extremely basic example of a neural network.
class FeedForward:
def __init__(self, d_model):
# First linear layer increases the dimensionality of the data.
self.layer1 = Linear(d_model, d_model * 4)
# Second linear layer brings the dimensionality back to d_model.
self.layer2 = Linear(d_model * 4, d_model)
def forward(self, x):
# Pass the input through the first layer,
#Pass the input through the first layer:
# Input: This refers to the data you feed into the neural network. I
#First layer: Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output.
# apply ReLU activation to introduce non-linearity,
# and then pass through the second layer.
#ReLU activation: ReLU stands for Rectified Linear Unit.
# It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero.
# Neural networks can model complex relationships in data by introducing non-linearities.
# Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model.
# Non-linearities allow the network to capture complex patterns and make better predictions.
return self.layer2(relu(self.layer1(x)))
# Positional encoding adds information about the position of each word in the sequence.
class PositionalEncoding:
def __init__(self, d_model):
# What this is: A setup to add information about where each word is in a sentence.
# What it does: Prepares to add a unique "position" value to each word.
# Why it does it: Words in a sentence have an order, and this helps the model remember that order.
# How it does it: By creating a special pattern of numbers for each position in a sentence.
# How it fits into the rest of the code: Before processing words, we add their position info.
# Explained like I'm five: Imagine you're in a line with your friends. This gives everyone a number to remember their place in line.
pass
def forward(self, x):
# What this is: The main function that adds position info to our words.
# What it does: Combines the word's original value with its position value.
# Why it does it: So the model knows the order of words in a sentence.
# How it does it: By adding the position values we prepared earlier to the word values.
# How it fits into the rest of the code: This function is called whenever we want to add position info to our words.
# Explained like I'm five: It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on.
return x
# Helper functions
def dot_product(a, b):
# Calculate the dot product of two matrices.
# What this is: A mathematical operation to see how similar two lists of numbers are.
# What it does: Multiplies matching items in the lists and then adds them up.
# Why it does it: To measure similarity or relevance between two sets of data.
# How it does it: By multiplying and summing up.
# How it fits into the rest of the code: Used in attention to see how relevant words are to each other.
# Explained like I'm five: Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have.
return a @ b.transpose(-2, -1)
def softmax(x):
# Convert raw scores to probabilities ensuring they sum up to 1.
# What this is: A way to turn any list of numbers into probabilities.
# What it does: Makes the numbers between 0 and 1 and ensures they all add up to 1.
# Why it does it: So we can understand the numbers as chances or probabilities.
# How it does it: By using exponentiation and division.
# How it fits into the rest of the code: Used to convert attention scores into probabilities.
# Explained like I'm five: Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind.
return exp(x) / sum(exp(x), axis=-1)
def relu(x):
# Activation function that introduces non-linearity. It sets negative values to 0.
# What this is: A simple rule for numbers.
# What it does: If a number is negative, it changes it to zero. Otherwise, it leaves it as it is.
# Why it does it: To introduce some simplicity and non-linearity in our model's calculations.
# How it does it: By checking each number and setting it to zero if it's negative.
# How it fits into the rest of the code: Used in neural networks to make them more powerful and flexible.
# Explained like I'm five: Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones.
return max(0, x)
How generative AI works – in simple terms
Think of generative AI as rolling a weighted dice. The training data determine the weights (or probabilities).
If the dice represents the next word in a sentence, a word often following the current word in the training data will have a higher weight. So, “sky” might follow “blue” more often than “banana”. When the AI “rolls the dice” to generate content, it’s more likely to choose statistically more probable sequences based on its training.
So, how can LLMs generate content that “seems” original?
Let’s take a fake listicle – the “best Eid al-Fitr gifts for content marketers” – and walk through how an LLM can generate this list by combining textual cues from documents about gifts, Eid, and content marketers.
Before processing, the text is broken down into smaller pieces called “tokens.” These tokens can be as short as one character or as long as one word.
Example: “Eid al-Fitr is a celebration” becomes [“Eid”, “al-Fitr”, “is”, “a”, “celebration”].
This allows the model to work with manageable chunks of text and understand the structure of sentences.
Each token is then converted into a vector (a list of numbers) using embeddings. These vectors capture the meaning and context of each word.
Positional encoding adds information to each word vector about its position in the sentence, ensuring the model doesn’t lose this order information.
Then we use an attention mechanism: this allows the model to focus on different parts of the input text when generating an output. If you remember BERT, this is what was so exciting to Googlers about BERT.
If our model has seen texts about “gifts” and knows that people give gifts during celebrations, and it has also seen texts about “Eid al-Fitr” being a significant celebration, it will pay “attention” to these connections.
Similarly, if it has seen texts about “content marketers” needing specific tools or resources, it can connect the idea of “gifts” to “content marketers“.
Now we can combine contexts: As the model processes the input text through multiple Transformer layers, it combines the contexts it has learned.
So, even if the original texts never mentioned “Eid al-Fitr gifts for content marketers,” the model can bring together the concepts of “Eid al-Fitr,” “gifts,” and “content marketers” to generate this content.
This is because it has learned the broader contexts around each of these terms.
After processing the input through the attention mechanism and the feed-forward networks in each Transformer layer, the model produces a probability distribution over its vocabulary for the next word in the sequence.
It might think that after words like “best” and “Eid al-Fitr,” the word “gifts” has a high probability of coming next. Similarly, it might associate “gifts” with potential recipients like “content marketers.”
Get the daily newsletter search marketers rely on.
<input type=”hidden” name=”utmMedium” value=”“>
<input type=”hidden” name=”utmCampaign” value=”“>
<input type=”hidden” name=”utmSource” value=”“>
<input type=”hidden” name=”utmContent” value=”“>
<input type=”hidden” name=”pageLink” value=”“>
<input type=”hidden” name=”ipAddress” value=”“>
Processing…Please wait.
How large language models are built
The journey from a basic transformer model to a sophisticated large language model (LLM) like GPT-3 or BERT involves scaling up and refining various components.
Here’s a step-by-step breakdown:
LLMs are trained on vast amounts of text data. It’s hard to explain how vast this data is.
The C4 dataset, a starting point for many LLMs, is 750 GB of text data. That’s 805,306,368,000 bytes – a lot of information. This data can include books, articles, websites, forums, comment sections, and other sources.
The more varied and comprehensive the data, the better the model’s understanding and generalization capabilities.
While the basic transformer architecture remains the foundation, LLMs have a significantly larger number of parameters. GPT-3, for example, has 175 billion parameters. In this case, parameters refer to the weights and biases in the neural network that are learned during the training process.
In deep learning, a model is trained to make predictions by adjusting these parameters to reduce the difference between its predictions and the actual outcomes.
The process of adjusting these parameters is called optimization, which uses algorithms like gradient descent.
- Weights: These are values in the neural network that transform input data within the network’s layers. They are adjusted during training to optimize the model’s output. Each connection between neurons in adjacent layers has an associated weight.
- Biases: These are also values in the neural network that are added to the output of a layer’s transformation. They provide an additional degree of freedom to the model, allowing it to fit the training data better. Each neuron in a layer has an associated bias.
This scaling allows the model to store and process more intricate patterns and relationships in the data.
The large number of parameters also means that the model requires significant computational power and memory for training and inference. This is why training such models is resource-intensive and typically uses specialized hardware like GPUs or TPUs.
The model is trained to predict the next word in a sequence using powerful computational resources. It adjusts its internal parameters based on the errors it makes, continuously improving its predictions.
Attention mechanisms like the ones we’ve discussed are pivotal for LLMs. They allow the model to focus on different parts of the input when generating output.
By weighing the importance of different words in a context, attention mechanisms enable the model to generate coherent and contextually relevant text. Doing it at this massive scale enables the LLMs to work the way they do.
How does a transformer predict text?
Transformers predict text by processing input tokens through multiple layers, each equipped with attention mechanisms and feed-forward networks.
After processing, the model produces a probability distribution over its vocabulary for the next word in the sequence. The word with the highest probability is typically selected as the prediction.
How is a large language model built and trained?
Building an LLM involves gathering data, cleaning it, training the model, fine-tuning the model, and vigorous, continuous testing.
The model is initially trained on a vast corpus to predict the next word in a sequence. This phase allows the model to learn connections between words that pick up patterns in grammar, relationships that can represent facts about the world and connections that feel like logical reasoning. These connections also make it pick up biases present in the training data.
After pre-training, the model is refined on a narrower dataset, often with human reviewers following guidelines.
Fine-tuning is a crucial step in building LLMs. It involves training the pre-trained model on a more specific dataset or task. Let’s take ChatGPT as an example.
If you’ve played with GPT models, you know that prompting is less “write this thing” and more like
- Prompt: Once upon a time
- Continuation: There was an evil wizard at the top of a tower.
- Prompt: Why did the chicken join a band?
- Continuation: Because it had the drumsticks!
To get to ChatGPT from that point involves a lot of low-paid labor. Those people create immense corpora to put a finger on the weight of GPT responses and expected behaviors. These workers create tons of prompt/continuation texts that are like:
- Prompt: Finish this story: “Once upon a time..”
- Continuation: Sure! Once upon a time, in a land far, far away, there was a small village nestled between two majestic mountains.
- Prompt: Tell me a joke about a chicken.
- Continuation: Why did the chicken join a band? Because it had the drumsticks!
This fine-tuning process is essential for several reasons:
- Specificity: While pre-training gives the model a broad understanding of language, fine-tuning narrows its knowledge and behavior to align more with specific tasks or domains. For instance, a model fine-tuned on medical data will better answer medical questions.
- Control: Fine-tuning gives developers more control over the model’s outputs. Developers can use a curated dataset to guide the model to produce desired responses and avoid unwanted behaviors.
- Safety: It helps in reducing harmful or biased outputs. By using guidelines during the fine-tuning process, human reviewers can ensure the model doesn’t produce inappropriate content.
- Performance: Fine-tuning can significantly improve the model’s performance on specific tasks. For example, a model that’s been fine-tuned for customer support will be much better at it than a generic model.
You can tell ChatGPT has been fine-tuned in particular in some ways.
For example, “logical reasoning” is something LLMs tend to struggle with. ChatGPT’s best logical reasoning model – GPT-4 – has been trained intensely to recognize patterns in numbers explicitly.
Instead of something like this:
- Prompt: What’s 2+2?
- Process: Oftentimes in math textbooks for children 2+2 =4. Occasionally there are references to “2+2=5″ but there is usually more context to do with George Orwell or Star Trek when that is the case. If this was in that context the weight would be more in favor of 2+2=5. But that context doesn’t exist, so in this instance the next token is likely 4.
- Response: 2+2=4
The training does something like this:
- training: 2+2=4
- training: 4/2=2
- training: half of 4 is 2
- training: 2 of 2 is four
…and so on.
This means for those more “logical” models, the training process is more rigorous and focused on ensuring that the model understands and correctly applies logical and mathematical principles.
The model is exposed to various mathematical problems and their solutions, ensuring it can generalize and apply these principles to new, unseen problems.
The importance of this fine-tuning process, especially for logical reasoning, cannot be overstated. Without it, the model might provide incorrect or nonsensical answers to straightforward logical or mathematical questions.
Image models vs. language models
While both image and language models might use similar architectures like transformers, the data they process is fundamentally different:
Image models
These models deal with pixels and often work in a hierarchical manner, analyzing small patterns (like edges) first, then combining them to recognize larger structures (like shapes), and so on until they understand the entire image.
Language models
These models process sequences of words or characters. They need to understand the context, grammar, and semantics to generate coherent and contextually relevant text.
How prominent generative AI interfaces work
Dall-E + Midjourney
Dall-E is a variant of the GPT-3 model adapted for image generation. It’s trained on a vast dataset of text-image pairs. Midjourney is another image generation software that is based on a proprietary model.
- Input: You provide a textual description, like “a two-headed flamingo.”
- Processing: These models encode this text into a series of numbers and then decode these vectors, finding relationships to pixels, to produce an image. The model has learned the relationships between textual descriptions and visual representations from its training data.
- Output: An image that matches or relates to the given description.
Fingers, patterns, problems
Why can’t these tools consistently generate hands that look normal? These tools work by looking at pixels next to each other.
You can see how this works when comparing earlier or more primitive generated images with more recent ones: earlier models look very fuzzy. In contrast, more recent models are a lot crisper.
These models generate images by predicting the next pixel based on the pixels it has already generated. This process is repeated millions of times over to produce a complete image.
Hands, especially fingers, are intricate and have a lot of details that need to be captured accurately.
Each finger’s positioning, length, and orientation can vary greatly in different images.
When generating an image from a textual description, the model has to make many assumptions about the exact pose and structure of the hand, which can lead to anomalies.
ChatGPT
ChatGPT is based on the GPT-3.5 architecture, a transformer-based model designed for natural language processing tasks.
- Input: A prompt or a series of messages to simulate a conversation.
- Processing: ChatGPT uses its vast knowledge from diverse internet texts to generate responses. It considers the context provided in the conversation and tries to produce the most relevant and coherent reply.
- Output: A text response that continues or answers the conversation.
Specialty
ChatGPT’s strength lies in its ability to handle various topics and simulate human-like conversations, making it ideal for chatbots and virtual assistants.
Bard + Search Generative Experience (SGE)
While specific details might be proprietary, Bard is based on transformer AI techniques, similar to other state-of-the-art language models. SGE is based on similar models but weaves in other ML algorithms Google uses.
SGE likely generates content using a transformer-based generative model and then fuzzy extracts answers from ranking pages in search. (This may not be true. Just a guess based on how it seems to work from playing with it. Please don’t sue me!)
- Input: A prompt/command/search
- Processing: Bard processes the input and works the way other LLMs do. SGE uses a similar architecture but adds a layer where it searches its internal knowledge (gained from training data) to generate a suitable response. It considers the prompt’s structure, context, and intent to produce relevant content.
- Output: Generated content that can be a story, answer, or any other type of text.
Applications of generative AI (and their controversies)
Art and design
Generative AI can now create artwork, music, and even product designs. This has opened up new avenues for creativity and innovation.
Controversy
The rise of AI in art has sparked debates about job losses in creative fields.
Additionally, there are concerns about:
- Labor violations, especially when AI-generated content is used without proper attribution or compensation.
- Executives threatening writers with replacing them with AI is one of the issues that spurred the writers’ strike.
Natural language processing (NLP)
AI models are now widely used for chatbots, language translation, and other NLP tasks.
Outside the dream of artificial general intelligence (AGI), this is the best use for LLMs since they are close to a “generalist” NLP model.
Controversy
Many users find chatbots to be impersonal and sometimes annoying.
Moreover, while AI has made significant strides in language translation, it often lacks the nuance and cultural understanding that human translators bring, leading to impressive and flawed translations.
Medicine and drug discovery
AI can quickly analyze vast amounts of medical data and generate potential drug compounds, speeding up the drug discovery process. Many doctors already use LLMs to write notes and patient communications
Controversy
Relying on LLMs for medical purposes can be problematic. Medicine requires precision, and any errors or oversights by AI can have serious consequences.
Medicine also already has biases that only get more baked in using LLMs. There are also similar issues, as discussed below, with privacy, efficacy, and ethics.
Gaming
Many AI enthusiasts are excited about using AI in gaming: they say that AI can generate realistic gaming environments, characters, and even entire game plots, enhancing the gaming experience. NPC dialogue can be enhanced through using these tools.
Controversy
There’s a debate about the intentionality in game design.
While AI can generate vast amounts of content, some argue it lacks the deliberate design and narrative cohesion that human designers bring.
Watchdogs 2 had programmatic NPCs, which did little to add to the narrative cohesion of the game as a whole.
Marketing and advertising
AI can analyze consumer behavior and generate personalized advertisements and promotional content, making marketing campaigns more effective.
LLMs have context from other people’s writing, making them useful for generating user stories or more nuanced programmatic ideas. Instead of recommending TVs to someone who just bought a TV, LLMs can recommend accessories someone might want instead.
Controversy
The use of AI in marketing raises privacy concerns. There’s also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they’ve seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model’s last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a “common sense” understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they’ve seen. While they can combine these patterns in novel ways, they don’t “invent” like humans do. Their “creativity” is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration: Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn’t real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush,” people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there’s no guarantee they’ll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don’t know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they’re essentially regurgitating and recombining what they’ve seen before. They don’t “invent” in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it’s hard for LLMs to deal with it.
This didn’t happen, but it is published online and is currently the top result for Megan Crosby.For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don’t know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can’t verify facts or discern true and false information.
If they’ve been exposed to misinformation or biased data during training, or they don’t have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it’s a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there’s a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that’s challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
The post What is generative AI and how does it work? appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
How to create an SEO roadmap
Written on September 26, 2023 at 9:57 am, by admin
When implementing an SEO strategy, a document roadmap is crucial for several reasons:
- It serves as your daily guide.
- It represents what non-SEO professionals perceive as SEO – a practical checklist of tasks.
- It provides a structure to communicate expectations with stakeholders.
A solid, well-researched strategy is best complemented with an SEO roadmap in Google Sheets or a tool like Jira or Asana. Ideally, leverage the technologies your teams are already using.
This article discusses why an SEO roadmap is essential for your strategy. Plus, learn how to create a solid SEO roadmap to prioritize tasks and collaborate effectively with teams.
What you need for an SEO roadmap
 Here’s a link to copy my SEO roadmap template in Google Sheets.
Here’s a link to copy my SEO roadmap template in Google Sheets.An SEO roadmap is a lot like SEO as a whole, it cannot successfully exist in a silo. That’s both in terms of your own research and your team within the wider business.
Within SEO, you’d ideally have a completed SEO strategy, which includes your:
- Technical audit.
- Content inventory, content audit and content gap analysis.
- Topical research – entity (including your own brand), keywords and topics.
- Market and competitor research.
Once you have all of that, you should be able to layer it on top of your wider business context. This includes:
- Your business goals for the next one to five years.
- Tools, people and budget availability. This includes knowing when and how you can pitch for budget.
- Planned product launches or marketing campaigns.
- Your technology stack and any known limitations, considerations, or planned changes (including migrations).
Gathering this information for your SEO roadmap is crucial because, initially, you’ll aim to tackle high-impact, low-effort tasks. Keep in mind that these tasks vary depending on your organization.
Understanding your business goals will:
- Help align your SEO “quick wins” with work that will actually directly benefit the bottom line of the business.
- Give you the ability to speak to that benefit when getting the work done.
Knowing the people, tools and budget available to you may push you to reconsider where you start with your roadmap.
Let’s say you’re launching a new product in the next three months, and your development team is totally at capacity until a month after that launches. Maybe you start with your content team and create new hub-and-spoke content within your organization’s area of expertise first.
For example, when I worked at Optus, a major telco in Australia, folks would be hard-pressed to get any new development done on the website, large or small, from about June to September because we were preparing for the iPhone launch.
(In that instance, I was a part of that launch team, so I had a bit more wiggle room to get stuff done than I would’ve otherwise, but you get the gist).
You’ll also want to get a grasp on your tech stack. For some tech stack configurations, particularly on smaller websites or with SPAs, implementing a 404 server response or a 301 redirect might seem straightforward but is much more difficult and time-consuming than standard.
It isn’t easy to generalize in SEO. So, while you may want to say that a high-impact, low-effort task would be to resize the 10MB images on your product pages (yes, I’ve seen this happen, and you probably have too), there may be a reason why your images are that large, or why they haven’t been compressed yet.
Having all this context before putting together an SEO roadmap becomes your early indicator of those sticky situations.
Get the daily newsletter search marketers rely on.
<input type=”hidden” name=”utmMedium” value=”“>
<input type=”hidden” name=”utmCampaign” value=”“>
<input type=”hidden” name=”utmSource” value=”“>
<input type=”hidden” name=”utmContent” value=”“>
<input type=”hidden” name=”pageLink” value=”“>
<input type=”hidden” name=”ipAddress” value=”“>
Processing…Please wait.
Steps to create your SEO roadmap
1. Prioritize
This is the first round of prioritization, the one where I estimate the SEO impact in a silo.
If I look at nothing else, the one metric I look at to help prioritize is how much of the website that potential issue affects.
Once I understand the scale, I look to estimate the impact. Quantifying impact can be difficult, but there are a few ways to do it:
- Top-down using competitor analysis and historical or current website changes as a model.
- Bottom-up using keyword-level forecasting based on estimated position changes.
- Traffic estimates using historical modeling and tactically based case studies or historical competitor execution.
While we can be secure in our scale and impact estimates for SEO, the one element we’re less certain of is effort.
I’ll still take a stab at estimating effort, but to do it well, I bring in the experts.
2. Assign and estimate
SEO can sometimes be like herding cats because you rely on other people or teams to implement your tactics.
This is why I start my roadmap with what some may feel is that last step – figuring out who’ll be doing the work and speaking to them about how long they think it will take.
If relevant, I’ll ask when they think they can do it and any other dependencies they’d need to do the work, like budget.
I’m not an expert in design, UX, or front-end development for our website. They are.
So, while I can build a rough estimate of what I think a task will take based on my own experiences with other clients or what the web generally says, it’s only a T-shirt size – one that could be off-base for reasons I don’t know.
I don’t know the legacy code we have stringing through the website or the fact that it can take up to an hour sometimes to replace images on a product page because of a buggy CMS that’ll randomly not apply filename changes sometimes.
I don’t know if we’re amidst an unofficial code migration or running 20x CRO tests on that page.
I don’t know all that stuff, but my teams do.
So I take my SEO strategy, which I’ve probably worked on for months, agonized and perfected, and I pull out all the tasks I think a particular team will do.
Then I take that and do a rough grooming and sizing session for those tasks with someone who knows what they’re talking about – usually, with the product owner of that squad.
And if you don’t know who that is, it’s a good time to make friends. I swear, 90% of being an SEO is about being curious and kind.
Note: Depending on your organization, your team might estimate differently. Sometimes, it’s in days. Other times, it’s using an agile Fibonacci scale or something similar.
Whatever it is, you’ll want to be consistent. A Fibonacci scale can make translating to days in order to estimate the time frame a bit more difficult. Still, I’d lean on the team to give an average execution time so you can then put in at least an estimated delivery.
This estimation process is helpful for enterprise-level companies because, assuming the conversation goes well, you’re essentially getting a soft yes from that team.
That’ll make it easier for them to say yes for real when the work comes across their desk later.
And then once that’s done, for me, it’s mostly paperwork.
3. Do the paperwork
For me, there’s no better format than Gantt when it comes to timed work and keeping track of it.
You can build it like I typically do in Google Sheets or use software-based versions in tools like Jira or Monday.
Define your headings
Your headings should be your primary work areas and can be based on your strategy.
For example, you may have buckets of work related to infrastructure, content or engineering.
For my strategy and roadmap, I typically align my primary areas of work to the teams that will primarily be handling them because that’s how my brain keeps track of things best.
Sometimes, aligning them differently, for example, with your business goals or team KPIs may make sense.
This could be something like “site speed, accessibility, expertise” where site speed and accessibility would primarily be development teams, and expertise would be a mix of SEO, development and content tasks.
Define your tasks
Everyone has a different perspective on what tasks should and shouldn’t be included in an SEO roadmap. Two major considerations are:
- How much you’re able to execute yourself.
- The level of detail you want and at what point it becomes overwhelming.
I typically work with enterprise clients, so in terms of tasks, there’s not usually much I can actually do myself.
What this means is my SEO roadmap is often a duplication of tasks that are assigned elsewhere, like JIRA tickets for developers or Asana tasks for designers.
The SEO roadmap becomes a centralized way for me to keep track of progress on SEO initiatives all in one place rather than a to-do list for me and my team to follow.
Let’ say you can execute much of the work yourself, then fabulous.
If tasks you can do yourself account for more than half the tasks in your roadmap, I’d suggest culling the list to focus on SEO work only and tracking non-SEO work either in a different tab in the spreadsheet or elsewhere.
For the granularity of tasks, aim for the middle ground – not too big and overwhelming, but also not too small and insignificant.
You wouldn’t want to include, say, “change the title tag on the blue widget page. But “change all title tags on the website” might be too large if you’re an enterprise site.
A middle ground could be, “Rewrite title tag formula for product page template, ” or even “Rewrite all title tag formulas.”
Something like “Product page optimization” could and should be broken into its component tasks, like:
- Create and share example product schema output for implementation.
- Create FAQ for top 20 revenue-driving products.
- Resize images for top 20 revenue-driving products.
- Work with content team to re-write product descriptions so they’re different from the manufacturer-provided ones for top 20 revenue-driving products.
From a practical perspective, if this is a year-long SEO roadmap, you want a manageable number of rows rather than hundreds or even thousands.
You’d likely get overwhelmed and end up not feeling confident getting started. Analysis paralysis is real.
4. Re-prioritize, assign and schedule your tasks
To use the SEO roadmap well, you need to treat it with laser focus. Once you have everything bucketed and tasked and know how long they’ll take to execute, it’s time to review your priority.
I prioritize tasks through a few different lenses after taking clear notes from my teams about dependencies and requirements for getting the work done.

First, the Eisenhower matrix.
This simple scale of the intersection of urgency and importance can be super grounding: more will probably end up in the “delete” bucket than you think.
I generally put these in a list in my notebook or project management tool I call “If/When I Have Time.”

This is after the initial grooming with execution teams, which probably discussed a few tasks or elements of tasks I realized weren’t worth the effort for the impact they would have.
I then come back to my initial prioritization and factor in the effort estimation from my teams.
- Does their feedback change my estimate of the impact?
- Did their expertise change my understanding of the scale?
Finally, we come back to the start. With tasks re-prioritized from actual feedback from the folks that’d be doing the work, it’s time to get the ball rolling.
This is when I tap execution teams on the shoulder to let them know this work should be coming their way and confirm they’ll be the ones to execute.
I start those “let’s make this official” for the tasks scheduled for the next six weeks, which, if all has gone well, should be those low-effort, high-impact tasks.
Drive SEO results with a well-defined roadmap
In case you weren’t sure, yes, this is a cycle. There’s a reason I started and ended my suggested process with similar tasks around assigning and estimating.
A strong SEO roadmap often moves and adjusts to what’s happening in the business and on the Internet. It’s an agile, living document.
When creating an SEO roadmap, my advice is to:
- Have a clear picture of the business and market context.
- Prioritize tasks first based on your SEO expertise.
- Re-prioritize tasks based on estimations and feedback from the executing teams.
- Organize your roadmap based on business goals or execution teams.
- Be focused on which tasks are actually valuable.
- Remember this is different from your day-to-day task list. Detailed page-level tasks should probably be kept out of the task list.
- Revisit the roadmap regularly.
With all that in mind, you’re armed to build a strong and flexible SEO roadmap for your clients, your business or your employer.
The post How to create an SEO roadmap appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
How to create an SEO roadmap
Written on September 26, 2023 at 9:57 am, by admin
When implementing an SEO strategy, a document roadmap is crucial for several reasons:
- It serves as your daily guide.
- It represents what non-SEO professionals perceive as SEO – a practical checklist of tasks.
- It provides a structure to communicate expectations with stakeholders.
A solid, well-researched strategy is best complemented with an SEO roadmap in Google Sheets or a tool like Jira or Asana. Ideally, leverage the technologies your teams are already using.
This article discusses why an SEO roadmap is essential for your strategy. Plus, learn how to create a solid SEO roadmap to prioritize tasks and collaborate effectively with teams.
What you need for an SEO roadmap
Here’s a link to copy my SEO roadmap template in Google Sheets.An SEO roadmap is a lot like SEO as a whole, it cannot successfully exist in a silo. That’s both in terms of your own research and your team within the wider business.
Within SEO, you’d ideally have a completed SEO strategy, which includes your:
- Technical audit.
- Content inventory, content audit and content gap analysis.
- Topical research – entity (including your own brand), keywords and topics.
- Market and competitor research.
Once you have all of that, you should be able to layer it on top of your wider business context. This includes:
- Your business goals for the next one to five years.
- Tools, people and budget availability. This includes knowing when and how you can pitch for budget.
- Planned product launches or marketing campaigns.
- Your technology stack and any known limitations, considerations, or planned changes (including migrations).
Gathering this information for your SEO roadmap is crucial because, initially, you’ll aim to tackle high-impact, low-effort tasks. Keep in mind that these tasks vary depending on your organization.
Understanding your business goals will:
- Help align your SEO “quick wins” with work that will actually directly benefit the bottom line of the business.
- Give you the ability to speak to that benefit when getting the work done.
Knowing the people, tools and budget available to you may push you to reconsider where you start with your roadmap.
Let’s say you’re launching a new product in the next three months, and your development team is totally at capacity until a month after that launches. Maybe you start with your content team and create new hub-and-spoke content within your organization’s area of expertise first.
For example, when I worked at Optus, a major telco in Australia, folks would be hard-pressed to get any new development done on the website, large or small, from about June to September because we were preparing for the iPhone launch.
(In that instance, I was a part of that launch team, so I had a bit more wiggle room to get stuff done than I would’ve otherwise, but you get the gist).
You’ll also want to get a grasp on your tech stack. For some tech stack configurations, particularly on smaller websites or with SPAs, implementing a 404 server response or a 301 redirect might seem straightforward but is much more difficult and time-consuming than standard.
It isn’t easy to generalize in SEO. So, while you may want to say that a high-impact, low-effort task would be to resize the 10MB images on your product pages (yes, I’ve seen this happen, and you probably have too), there may be a reason why your images are that large, or why they haven’t been compressed yet.
Having all this context before putting together an SEO roadmap becomes your early indicator of those sticky situations.
Get the daily newsletter search marketers rely on.
<input type=”hidden” name=”utmMedium” value=”“>
<input type=”hidden” name=”utmCampaign” value=”“>
<input type=”hidden” name=”utmSource” value=”“>
<input type=”hidden” name=”utmContent” value=”“>
<input type=”hidden” name=”pageLink” value=”“>
<input type=”hidden” name=”ipAddress” value=”“>
Processing…Please wait.
Steps to create your SEO roadmap
1. Prioritize
This is the first round of prioritization, the one where I estimate the SEO impact in a silo.
If I look at nothing else, the one metric I look at to help prioritize is how much of the website that potential issue affects.
Once I understand the scale, I look to estimate the impact. Quantifying impact can be difficult, but there are a few ways to do it:
- Top-down using competitor analysis and historical or current website changes as a model.
- Bottom-up using keyword-level forecasting based on estimated position changes.
- Traffic estimates using historical modeling and tactically based case studies or historical competitor execution.
While we can be secure in our scale and impact estimates for SEO, the one element we’re less certain of is effort.
I’ll still take a stab at estimating effort, but to do it well, I bring in the experts.
2. Assign and estimate
SEO can sometimes be like herding cats because you rely on other people or teams to implement your tactics.
This is why I start my roadmap with what some may feel is that last step – figuring out who’ll be doing the work and speaking to them about how long they think it will take.
If relevant, I’ll ask when they think they can do it and any other dependencies they’d need to do the work, like budget.
I’m not an expert in design, UX, or front-end development for our website. They are.
So, while I can build a rough estimate of what I think a task will take based on my own experiences with other clients or what the web generally says, it’s only a T-shirt size – one that could be off-base for reasons I don’t know.
I don’t know the legacy code we have stringing through the website or the fact that it can take up to an hour sometimes to replace images on a product page because of a buggy CMS that’ll randomly not apply filename changes sometimes.
I don’t know if we’re amidst an unofficial code migration or running 20x CRO tests on that page.
I don’t know all that stuff, but my teams do.
So I take my SEO strategy, which I’ve probably worked on for months, agonized and perfected, and I pull out all the tasks I think a particular team will do.
Then I take that and do a rough grooming and sizing session for those tasks with someone who knows what they’re talking about – usually, with the product owner of that squad.
And if you don’t know who that is, it’s a good time to make friends. I swear, 90% of being an SEO is about being curious and kind.
Note: Depending on your organization, your team might estimate differently. Sometimes, it’s in days. Other times, it’s using an agile Fibonacci scale or something similar.
Whatever it is, you’ll want to be consistent. A Fibonacci scale can make translating to days in order to estimate the time frame a bit more difficult. Still, I’d lean on the team to give an average execution time so you can then put in at least an estimated delivery.
This estimation process is helpful for enterprise-level companies because, assuming the conversation goes well, you’re essentially getting a soft yes from that team.
That’ll make it easier for them to say yes for real when the work comes across their desk later.
And then once that’s done, for me, it’s mostly paperwork.
3. Do the paperwork
For me, there’s no better format than Gantt when it comes to timed work and keeping track of it.
You can build it like I typically do in Google Sheets or use software-based versions in tools like Jira or Monday.
Define your headings
Your headings should be your primary work areas and can be based on your strategy.
For example, you may have buckets of work related to infrastructure, content or engineering.
For my strategy and roadmap, I typically align my primary areas of work to the teams that will primarily be handling them because that’s how my brain keeps track of things best.
Sometimes, aligning them differently, for example, with your business goals or team KPIs may make sense.
This could be something like “site speed, accessibility, expertise” where site speed and accessibility would primarily be development teams, and expertise would be a mix of SEO, development and content tasks.
Define your tasks
Everyone has a different perspective on what tasks should and shouldn’t be included in an SEO roadmap. Two major considerations are:
- How much you’re able to execute yourself.
- The level of detail you want and at what point it becomes overwhelming.
I typically work with enterprise clients, so in terms of tasks, there’s not usually much I can actually do myself.
What this means is my SEO roadmap is often a duplication of tasks that are assigned elsewhere, like JIRA tickets for developers or Asana tasks for designers.
The SEO roadmap becomes a centralized way for me to keep track of progress on SEO initiatives all in one place rather than a to-do list for me and my team to follow.
Let’ say you can execute much of the work yourself, then fabulous.
If tasks you can do yourself account for more than half the tasks in your roadmap, I’d suggest culling the list to focus on SEO work only and tracking non-SEO work either in a different tab in the spreadsheet or elsewhere.
For the granularity of tasks, aim for the middle ground – not too big and overwhelming, but also not too small and insignificant.
You wouldn’t want to include, say, “change the title tag on the blue widget page. But “change all title tags on the website” might be too large if you’re an enterprise site.
A middle ground could be, “Rewrite title tag formula for product page template, ” or even “Rewrite all title tag formulas.”
Something like “Product page optimization” could and should be broken into its component tasks, like:
- Create and share example product schema output for implementation.
- Create FAQ for top 20 revenue-driving products.
- Resize images for top 20 revenue-driving products.
- Work with content team to re-write product descriptions so they’re different from the manufacturer-provided ones for top 20 revenue-driving products.
From a practical perspective, if this is a year-long SEO roadmap, you want a manageable number of rows rather than hundreds or even thousands.
You’d likely get overwhelmed and end up not feeling confident getting started. Analysis paralysis is real.
4. Re-prioritize, assign and schedule your tasks
To use the SEO roadmap well, you need to treat it with laser focus. Once you have everything bucketed and tasked and know how long they’ll take to execute, it’s time to review your priority.
I prioritize tasks through a few different lenses after taking clear notes from my teams about dependencies and requirements for getting the work done.
First, the Eisenhower matrix.
This simple scale of the intersection of urgency and importance can be super grounding: more will probably end up in the “delete” bucket than you think.
I generally put these in a list in my notebook or project management tool I call “If/When I Have Time.”
This is after the initial grooming with execution teams, which probably discussed a few tasks or elements of tasks I realized weren’t worth the effort for the impact they would have.
I then come back to my initial prioritization and factor in the effort estimation from my teams.
- Does their feedback change my estimate of the impact?
- Did their expertise change my understanding of the scale?
Finally, we come back to the start. With tasks re-prioritized from actual feedback from the folks that’d be doing the work, it’s time to get the ball rolling.
This is when I tap execution teams on the shoulder to let them know this work should be coming their way and confirm they’ll be the ones to execute.
I start those “let’s make this official” for the tasks scheduled for the next six weeks, which, if all has gone well, should be those low-effort, high-impact tasks.
Drive SEO results with a well-defined roadmap
In case you weren’t sure, yes, this is a cycle. There’s a reason I started and ended my suggested process with similar tasks around assigning and estimating.
A strong SEO roadmap often moves and adjusts to what’s happening in the business and on the Internet. It’s an agile, living document.
When creating an SEO roadmap, my advice is to:
- Have a clear picture of the business and market context.
- Prioritize tasks first based on your SEO expertise.
- Re-prioritize tasks based on estimations and feedback from the executing teams.
- Organize your roadmap based on business goals or execution teams.
- Be focused on which tasks are actually valuable.
- Remember this is different from your day-to-day task list. Detailed page-level tasks should probably be kept out of the task list.
- Revisit the roadmap regularly.
With all that in mind, you’re armed to build a strong and flexible SEO roadmap for your clients, your business or your employer.
The post How to create an SEO roadmap appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Mapping the customer journey for SEO and marketing success
Written on September 25, 2023 at 6:56 am, by admin
Before embarking on a shopping journey, customers often find themselves in a state of awareness where a specific need or desire has sprouted in their minds.
A growing recognition of a gap characterizes this initial phase – perhaps a missing item in their collection, an upgrade to enhance their lifestyle or a solution to a newly identified problem at their workplace.

During the purchasing decision process, a customer navigates a rich landscape of exploration and contemplation.
Initially, curiosity leads them to sift through various options, scrutinizing features, reviews, and personal recommendations while considering the product’s aesthetic appeal.
As the customer dives deeper, a complex interplay between desire and rationality occurs, with considerations of value, necessity and potential enjoyment balanced against budget constraints.
An emerging emotional connection to the product influences their choice, potentially aligning with their personal narrative or lifestyle.
Ultimately, a fusion of research and emotional resonance guides them to a decision where trust in the brand and perceived value peaks, culminating in a purchase that is both anticipated and satisfying yet open to subsequent evaluation based on the product’s ability to meet cultivated expectations.
In the vibrant canvas of digital marketing and SEO, weaving personal narratives through customer journey maps isn’t just vital – it’s a sophisticated art.
Join me on a journey to understanding the significance of the customer journey map and what role SEO plays, bridging SEO finesse with a nuanced grasp of your audience’s journey and painting not just a plan but a masterpiece of empathy and insight.
Understanding the significance of the customer journey in SEO
By aligning SEO strategies with the customer journey, marketers can craft content that is highly relevant and tailored to resonate with users as they research a product or service.
This approach enhances the user experience and positively impacts search engine rankings by aligning the two.
Google, in particular, tends to favor content that embodies the principles of experience, expertise, authoritativeness and trustworthiness (E-E-A-T). The process in which users begin to research their needs starts on Google and other search engines.
Data-driven insights from understanding and optimizing the customer journey through keyword analysis and proper tagging can inform SEO strategies. This leads to more impressions, traffic and increased brand loyalty.
Users who identify their needs and validate their decision will make a purchase decision quickly and are more likely to engage with the site and convert.
In the long run, SEO strategies focusing on the customer journey are more sustainable and benefit the user experience, contributing to a positive return on investment (ROI) and a competitive edge in the digital landscape.
The customer journey map: A compass for success
A customer journey map is a visual tool that meticulously charts the various touchpoints and interactions a customer has with a brand, extending from the initial spark of awareness to post-purchase engagements.
This illustrative map captures transactional phases and intricately explores the underlying emotions and motivations steering the customer’s choices.
It serves as a comprehensive blueprint, offering a deep dive into each step of the customer’s experience, thus painting a fuller picture of their path and nuanced relationship with your brand and offerings.
Why define your customer journey map?
In the ever-evolving business and marketing landscape, understanding your customer journey map is more of a necessity than a luxury.
I have entered new roles as an SEO of a company many times, only to find that the marketers I work with haven’t considered where the user is in their decision-making process while developing content.
As a part of this, it isn’t clear what role SEO should play during attribution. I will utilize a keyword analysis while considering what problems they want to solve.
I ask myself the right questions, tagging each keyword with where they are in their journey to understand their intent.
But don’t take my word for it. Here are some compelling reasons why defining your customer journey is crucial for the success and growth of your marketing efforts:
Better understanding your customer
Implementing a customer journey map provides deep insights into your target audience’s goals, pain points, and emotions. With this knowledge, you can tailor your marketing and SEO efforts for maximum impact.
Identification and resolution of service issues
No product or service is flawless, but by viewing the brand from your customer’s perspective, you can identify and address shortcomings to enhance customer satisfaction.
Creation of exceptional experiences
A clear understanding of the customer journey allows you to optimize touchpoints from your various marketing channels, creating exceptional experiences at every stage and fostering trust in your brand.
Discovery of untapped opportunities
By analyzing the journey, you may uncover gaps in your SEO strategy or what your competitors might have missed. These unique nuances can set your brand apart.
Cost reduction and improved results
Aligning your SEO strategy with the customer journey can enhance campaign effectiveness, driving up results while reducing costs.
Get the daily newsletter search marketers rely on.
<input type=”hidden” name=”utmMedium” value=”“>
<input type=”hidden” name=”utmCampaign” value=”“>
<input type=”hidden” name=”utmSource” value=”“>
<input type=”hidden” name=”utmContent” value=”“>
<input type=”hidden” name=”pageLink” value=”“>
<input type=”hidden” name=”ipAddress” value=”“>
Processing…Please wait.
SEO’s part in the customer experience journey
For optimal success, it’s vital to harmonize your marketing efforts with the nuanced pathways of the customer experience journey. This holistic approach involves:
Understanding the phases
- Recognizing that marketing communications alone are short-sighted.
- The entire customer experience should be considered, from awareness to post-purchase, with SEO playing a crucial role.
Data-driven decisions
- Use estimated volume numbers from your keyword analysis to guide marketing decisions at each journey stage.
Industry-specific tailoring
- To stay focused, adapt the customer journey map and where SEO fits within your business model, whether B2B, B2C, or retail.
Optimizing for search throughout the entire customer journey
The customer journey process intricately branches into six well-defined stages, each necessitating a tailored marketing strategy.
This approach effectively engages and shepherds users through a thoughtful progression culminating in a well-informed purchase decision.
It is a delicate dance of guidance and persuasion, ensuring potential customers feel supported and enlightened on their path to choosing the perfect product or service at each step.
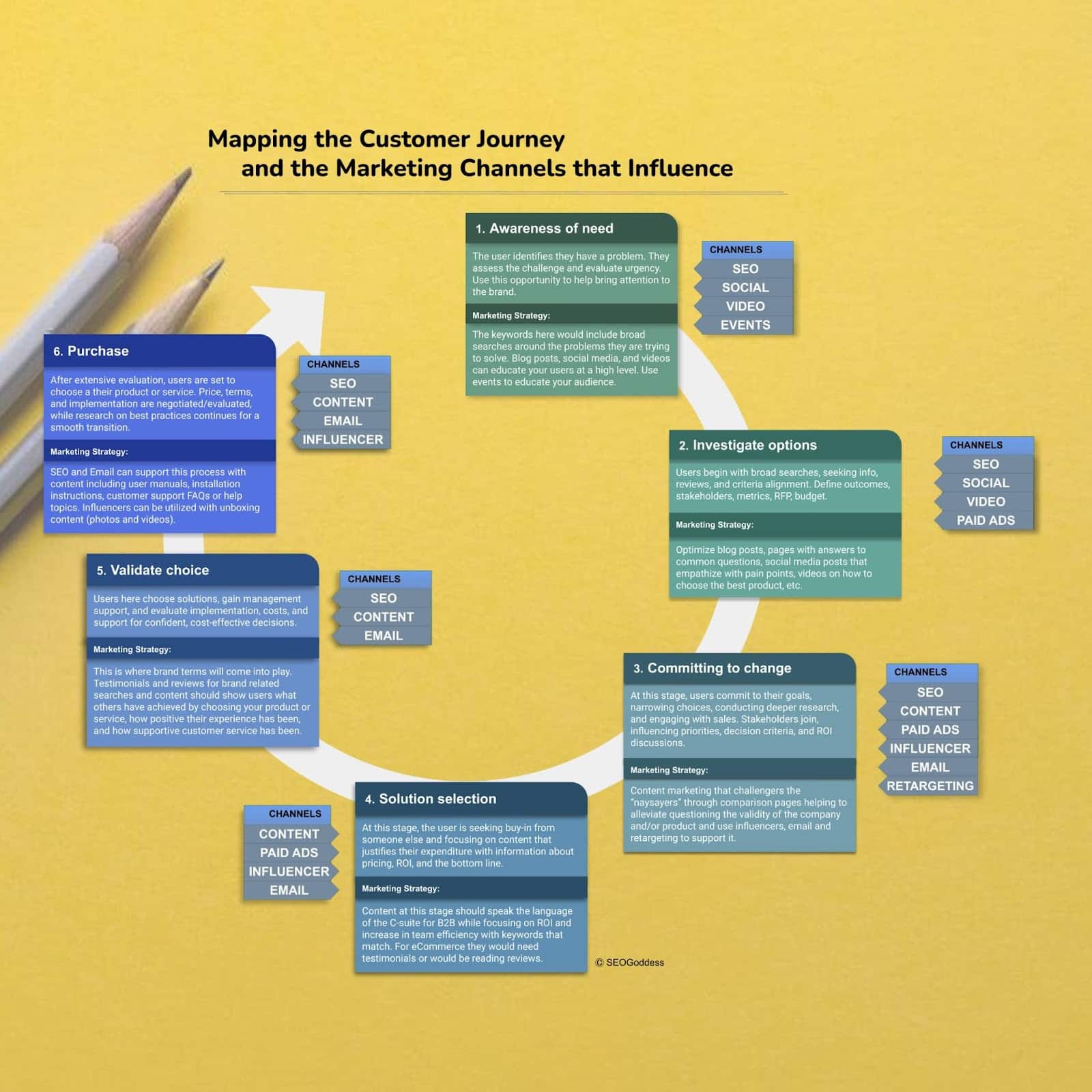
1. Awareness of need
Initially, customers recognize a pressing issue that necessitates resolution. They gauge the gravity of the dilemma, presenting an opportunity for brands to seize their interest.
Marketing strategies should encompass problem-related keywords, enlightening blog articles, captivating social media narratives, and instructional videos.
Additionally, events are a powerful tool to deepen the audience’s understanding of the matter, showcasing the brand’s viable solutions.
2. Investigate options
During this phase, users initiate broad searches to gather information, read reviews, and align criteria for potential solutions. They start defining outcomes, stakeholders, metrics, budgets and more.
To assist users in their research, marketers should:
- Optimize blog posts.
- Create informative website pages.
- Share empathetic social media posts addressing pain points.
- Produce videos guiding users in selecting the best product or service.
3. Committing to change
Users in this stage commit to their goals, narrow choices, and delve deeper into research.
Sales engagements become more prominent, and stakeholders join the decision-making process.
Marketing strategies should focus on content that challenges doubts or objections, such as comparison pages that validate the company’s credibility.
Influencers, email campaigns and retargeting efforts can reinforce the commitment made by users.
4. Solution selection
As users seek buy-in from decision-makers, they require content that justifies their expenditure, often emphasizing pricing, ROI and overall value.
B2B marketing should speak the language of the C-suite, highlighting ROI and efficiency improvements.
For ecommerce, testimonials and reviews play a crucial role in influencing selection.
5. Validate choice
Users validate their choice in this stage by seeking management support and evaluating implementation logistics, costs, and ongoing support.
Brands should optimize for brand-related searches, leverage testimonials and reviews to showcase successful experiences and highlight exceptional customer service.
6. Purchase
Following a thorough assessment, customers stand on the cusp of making their ultimate purchasing choice. Discussions surrounding pricing, terms and specifics of implementation might take place.
To facilitate this phase, brands can employ SEO and email marketing strategies, offering resources like:
- User guides.
- Setup manuals.
- Answers to frequently asked questions.
Moreover, leveraging influencers to craft engaging unboxing videos can vividly illustrate the product or service in use, enhancing the customer’s ability to visualize its value in their lives.
Successful campaigns are born from the seamless integration of customer journey mapping, adept SEO and strategic marketing.
Businesses can cultivate trust, enhance online visibility, and boost customer engagement by deeply understanding the customer’s journey and aligning SEO techniques with marketing efforts. Embrace this powerful synergy, ensuring you confidently navigate the vast SEO terrain.
In my next Search Engine Land article, I’ll guide you on aligning SEO with your customer journey, diving deep into keyword analysis and content strategy to enrich your company’s digital prowess.
The post Mapping the customer journey for SEO and marketing success appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
Former Googler: Google ‘using clicks in rankings’
Written on September 25, 2023 at 6:56 am, by admin
“Pretty much everyone knows we’re using clicks in rankings. That’s the debate: ‘Why are you trying to obscure this issue if everyone knows?’”
That quote comes from Eric Lehman, a former 17-year employee of Google who worked as a software engineer on search quality and ranking. He left Google in November.
Lehman testified last Wednesday as part of the ongoing U.S. vs. Google antitrust trial.
If you haven’t heard this quote yet, expect to hear it. A lot.
But. That’s not all Lehman had to say. Google’s machine learning systems BERT and MUM are becoming more important than user data, he said.
- “In one direction, it’s better to have more user data, but new technology and later systems can use less user data. It’s changing pretty fast,” Lehman said, as reported by Law360.
Lehman believes Google will rely more heavily on machine learning to evaluate text than user data, according to an email Lehman wrote in 2018, as reported by Fortune:
- “Huge amounts of user feedback can be largely replaced by unsupervised learning of raw text,” he wrote.
User vs. training data. There was also a confusion around “user data” vs. training data” when it came to BERT. Big Tech on Trial reported:
“DOJ’s attempt to impeach Lehman’s testimony also seemed to backfire. In response to a DOJ question about whether Google had an advantage in using BERT over competition because of its user data, Lehman testified that Google’s ‘biggest advantage in using BERT’ over its competitors was that Google invented BERT. DOJ then put up an exhibit titled ‘Bullet points for presentation to Sundar.’ One of the bullets on this exhibit said the following (according to my notes): ‘Any competitor can use BERT or similar technologies. Fortunately, our training data gives us a head-start. We have the opportunity to maintain and extend our lead by fully using the training data with BERT and serving it to our users…’
This likely would have been an effective impeachment of Lehman if “training data” meant some kind of user data. But after DOJ concluded its re-direct examination, Judge Mehta asked Lehman what “training data” referred to. Lehman explained it was different from user search data.”
Sensitive Topics. Lehman was also asked by DOJ attorney Erin Murdock-Park about a slide from one of his slide decks on “Sensitive Topics” that instructed employees to “not discuss the use of clicks in search…”
According to reporting from Big Tech on Trial (via X), Lehman said “we try to avoid confirming that we use user data in the ranking of search results.”
The reporter X post says “I didn’t get great notes on this, but I think the reason had something to do with not wanting people to think that SEO could be used to manipulate search results.”
that “we try to avoid confirming that we use user data in the ranking of search results.” I didn’t get great notes on this, but I think the reason had something to do with not wanting people to think that SEO could be used to manipulate search results.
— Big Tech on Trial (@BigTechOnTrial) September 20, 2023
Google = liars? Since discovering this testimony, SEOs have been quick to use Lehman’s quotes as definitive proof that Google has been lying about using clicks or click-through rate for all of its 25 years.
The question of whether Google uses clicks was the first question asked last week during an AMA with Google’s Gary Illyes at Pubcon Pro in Austin. Illyes answer was “technically, yes,” because Google uses historical search data for its machine-learning algorithm RankBrain.
Technically yes, translated from Googler speak, means yes. RankBrain was trained on user search data.
We know this because Illyes already told us this in 2018. He said RankBrain “uses historical search data to predict what would a user most likely click on for a previously unseen query.”
RankBrain was used for all searches, impacting “lots” of them, starting in 2016.
Google Search tracks everything. But the fact that Google tracks clicks in Search does not mean clicks are used as a direct ranking factor. In other words, if site A gets 100 clicks and site B gets 101 clicks, then site B automatically jumps up to Position 1.
Much like how Google uses its people to rate the quality of its search results, Google is likely using clicks to rate the results for queries and train its ranking systems.
Why we care. Does Google use clicks? Yes. But again, probably not as a ranking signal (thought admittedly I can’t say that with 100% certainty as I don’t work at Google or have access to the algorithm). I know clicks are noisy and easy to manipulate. And for many sites/queries, there simply wouldn’t be enough data to evaluate to make it a useful ranking signal for Google.
Dig deeper. The biggest mystery of Google’s algorithm: Everything ever said about clicks, CTR and bounce rate
The post Former Googler: Google ‘using clicks in rankings’ appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
5 outdated marketing KPIs to toss and what to reference instead
Written on September 25, 2023 at 6:56 am, by admin
Moving away from conventional KPIs and toward a more advanced understanding of your campaigns gives you real competitive advantages.
I could have written about this topic years ago, but it’s especially important as engagement costs on major advertising channels continue to increase, and an unpredictable economy puts a premium on efficiency.
Ready to change the way you measure your campaigns? In this article, I’ll look at five KPIs I still hear clients reference and explain:
- Why it’s past time to replace them.
- What they should analyze instead.
- Why it matters.
Bad KPI 1: Spend
What to use instead: Profit
I’m not saying the concept of a budget is moot, but spend should not be the starting point or goal for campaigns unless:
- You’re just beginning and have no CRM data to reference.
- You’re going for scale without regard to efficiency.
That said, we still get companies coming to us frequently and saying, “We’d like to spend this.”
Even more off-base, “We’d like to spend {x} on Google, {y} on Facebook, and {z} on LinkedIn.”
A better approach is to aim for efficiency goals, agnostic of channel.
If you start with an ROI goal of 3.0, good analytics folks will be able to crunch numbers and tell you how much you can spend and stay within that goal – no matter which channel you spend it on.
Referencing spend without tracking efficiency is how you hit growth walls (and get on the wrong side of your CFO).
Specifying spend across channels is a good way to doom yourself to the fate of spending too much on certain channels and not enough on other, more incremental sources of revenue.
If you are going for scale without regard to efficiency, metrics like conversions, spending, revenue, and visitors do become more important, while CPA and ROAS (efficiency metrics) will take a hit.
A core tenet of digital marketing is that the more conversions you get, the more expensive they are, so you’ll have to decide whether your first goal is improving efficiency or driving scale.
 Avg. ROAS vs. Gross Profit: There is an optimal efficiency target where gross profit is maximized.
Avg. ROAS vs. Gross Profit: There is an optimal efficiency target where gross profit is maximized.Bad KPI 2: Platform-provided CPA
What to use instead: CRM-based CPA
Relying solely on CPAs delivered by Google Ads, Facebook and LinkedIn without assessing the quality of those acquisitions (leads in B2B, purchases in ecommerce) makes it likely you’re spending too much on the wrong leads.
(Note: Google Search Partners and display campaigns produce particularly weak lead quality.)
Instead, integrate your CRM data to understand cost per down-funnel metrics (for B2B) or cost per CLTV (B2C and ecommerce).
This is especially important for B2B, given its long sales cycles and purchase stages.
Knowing what you’d like to pay for opportunities and understanding what you have to pay to acquire them on certain channels is more important than straight-up lead acquisition.
And it’ll make you more likely to swallow high CPCs (hello, LinkedIn) if the resulting leads carry enough value.
 Ad Platform vs. Back-end Efficiency: In this example, ad platform efficiency without further analysis suggests that you should dial up LinkedIn Remarketing. In contrast, analysis that incorporates back-end efficiency suggests you should dial up LinkedIn Prospecting instead.
Ad Platform vs. Back-end Efficiency: In this example, ad platform efficiency without further analysis suggests that you should dial up LinkedIn Remarketing. In contrast, analysis that incorporates back-end efficiency suggests you should dial up LinkedIn Prospecting instead.Dig deeper: 3 steps for effective PPC reporting and analysis
Get the daily newsletter search marketers rely on.
<input type=”hidden” name=”utmMedium” value=”“>
<input type=”hidden” name=”utmCampaign” value=”“>
<input type=”hidden” name=”utmSource” value=”“>
<input type=”hidden” name=”utmContent” value=”“>
<input type=”hidden” name=”pageLink” value=”“>
<input type=”hidden” name=”ipAddress” value=”“>
Processing…Please wait.
Bad KPI 3: Click-based CPA
What to use instead: Incrementality-based CPA
Click-based CPA (think first-click, last-click, or cookie or UTM-based MTA) ignores the contributions of impressions-based advertising campaigns, whether it’s a YouTube a, a programmatic ad or a billboard you sponsored on a highway near one of your target geos.
True CPA is based on incrementality, which implements things like the halo effect, brand lift testing, geo lift testing, etc.
It means being agnostic to clicks vs. impressions and understanding the true effect of any advertising interaction.
This can be relatively complex to set up. Still, there are native tools, like Facebook lift tests and Google’s CausalImpact R package using Bayesian structural time-series models, that can be a good starting point.
I recommend figuring out how much data you need to draw a statistically significant conclusion and only running these initiatives in test locations so you’re not curtailing entire campaigns while you assess their effects.
 Last Touch vs. True Influence: Advanced measurement methods such as geo lift testing or media mix modeling (MMM) can help estimate the true influence of your initiatives and enrich traditional last-touch reporting.
Last Touch vs. True Influence: Advanced measurement methods such as geo lift testing or media mix modeling (MMM) can help estimate the true influence of your initiatives and enrich traditional last-touch reporting.Bad KPI 4: Average CPA/Average ROAS
What to use instead: Marginal CPA/Marginal ROAS
When you’re using Marginal CPA, you’re really trying to figure out what you paid to acquire marginal returns – which means you’re calculating the return on each conversion, not just assuming you pay the same or get the same for all new customers.
Let’s illustrate this with a simple scenario: say you’re taking an average CPA from Facebook ads, which brought in a mix of expensive and cheaper customers, all worth roughly the same revenue amount.
If you take the average CPA, you might see that you spent $2 to acquire a new customer, whereas marginal CPA might show that you converted a bunch of new customers at $1.50 and a handful at $8.
Rather than turn up the dial across the board, it’d be smarter to keep finding more cost-effective customers like the first bunch. Don’t spend more to reach more expensive customers who provide no additional value.
Bad KPI 5: Impression share lost to bidding (search)
What to use instead: Impression share lost to budget (search)
If you are running search campaigns and want to lower spend, there are two main ways to do it.
- You drop bids or targets to decrease CPCs.
- You lower the campaign’s daily budget, which forces the campaign to turn off for portions of the day.
When you drop bids or targets and lose impression share, a lower CPC will help produce more clicks and conversion opportunities for the same budget.
I’ve seen brands use bidding strategies with goals of capturing something like 90% of available impression share (IS), which gives Google the green light to overcharge.
In these scenarios, switching to manual CPC targets and aiming lower (thereby losing some impression share) immediately tunes up performance and efficiency.
When you drop your budget, the campaign will hit the daily budget and turn off. This will lower overall spend and impression share but keep the same efficiency. So keep budgets up and control spend using bids and efficiency targets!
There are far-reaching implications when you embrace this “scale vs. efficiency” mindset.
Let’s say you are a B2B company that always sees poor performance on weekends. Instead of turning the weekends off, lower the bids/targets until the traffic is profitable.
Next steps
Some of these – especially the first and last – should be easy to implement right away. Others may need you to find a trusted analytics resource to help you sketch out some models and integrate the right data.
But by reading this far, you’ve already taken the first step: casting a critical eye on boilerplate KPIs that aren’t helping you truly optimize the effectiveness of your marketing campaigns.
One word to the wise: make sure you’re getting the right people on board before you pull the switch on any of these since people leaning on the old KPIs to gauge your work should be in alignment with what success looks like going forward.
Dig deeper: Tracking and measurement for PPC campaigns
The post 5 outdated marketing KPIs to toss and what to reference instead appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.
The Magical Black Box
Written on September 24, 2023 at 3:54 am, by admin
Google’s mission statement is “organize the world’s information and make it universally accessible and useful.”
That mission is so profound & so important the associated court documents in their antitrust cases must be withheld from public consumption.
Hey. The full exhibit list just posted in DC federal court for USA vs Google. J/k, they literally posted the numbers of all of the admitted exhibits which would be unsealed in a sane world where public interest is respected even more so because the defendant is insanely powerful. pic.twitter.com/FViD40xVmf— Jason Kint (@jason_kint) September 23, 2023
Before document sharing was disallowed, some of them were shared publicly.
Internal emails stated:
- Hal Varian was off in his public interviews where he suggested it was the algorithms rather than the amount of data which is prime driver of relevancy.
- Apple would not get any revshare if there was a user choice screen & must set Google as the default search engine to qualify for any revshare.
- Google has a policy of being vague about using clickstream data to influence ranking, though they have heavily relied upon clickstream data to influence ranking. Advances in machine learning have made it easier to score content to where the clickstream data had become less important.
- When Apple Maps launched & Google Maps lost the default position on iOS Google Maps lost 60% of their iOS distribution, and that was with how poorly the Apple Maps roll out went.
- Google sometimes subverted their typical auction dynamics and would flip the order of the top 2 ads to boost ad revenues.
- Google had a policy of “shaking the cushions” to hit the quarterly numbers by changing advertiser ad prices without informing advertisers that they’d be competing in a rigged auction with artificially manipulated shill bids from the auctioneer competing against them.
When Google talked about hitting the quarterly numbers with shaking the cusions the 5% number which was shared skewed a bit low:
For a brand campaign focused on a niche product, she said the average CPC at $11.74 surged to $25.85 over the last six months, amounting to a 108% increase. However, there wasn’t an incremental return on sales.
“The level to which [price manipulations] happens is what we don’t know,” said Yang. “It’s shady business practices because there’s no regulation. They regulate themselves.”
Early in the history of search ads Google blocked trademark keyword bidding. They later allowed it. When keyword bidding on trademarks was allowed it led to a conundrum for some advertisers. If you do not defend your trademark you could lose it, but if you agree with competitors not to bid on each other’s trademarks the FTC could come after you - like they did with 1-800 Contacts. This set up forces many brands to participate in auctions where they are arbitraging their own pre-existing brand equity. The ad auctioneer runs shady auctions where it looks across at your account behavior and bids then adjusts bid floors to suck more money out of you. This amounts to something akin to the bid jamming that was done in early Overture, except it is the house itself doing it to you! The last auction I remembered like that was SnapNames, where a criminal on the executive team used the handle halverez to leverage participant max bids and put in bids just under their bids.
Google is also pushing advertisers away from keyword-based bidding and toward a portfolio approach of automated bidding called Performance Max, where you give Google your credit card and budget then they bid as they wish. By blending everything into a single soup you may not know where the waste is & it may not be particularly easy to opt out of poorly performing areas. Remember enhanced AdWords campaigns?
Google continues to blur dataflow outside of their ad auctions to try to bring more of the ad spend into their auctions.
Wow. Google. Years behind other browsers (aka monopoly power), Google is attempting to deprecate tracking system A (aka third party cookies) and replace it with another tracking system B (aka Topics) that treats sites as G data mules.
This is deceptive as hell comparing B to A. pic.twitter.com/hCBJgYr7qn— Jason Kint (@jason_kint) September 22, 2023
The amount Google is paying Apple to be the default search provider is staggering.
What is $18 billion / year buying ? The DoJ has narrowed in an agreement not to compete between Apple and Google: “Sanford Bernstein estimates Google will pay Apple between $18 billion and $19 billion this year for default search status” https://t.co/HmoZxCZkqm— Tim Wu (@superwuster) September 22, 2023
Tens of billions of dollars is a huge payday. No way Google would hyper-optimize other aspects of their business (locating data centers near dams, prohibiting use of credit card payments for large advertisers, cutting away ad agency management fees, buying Android, launching Chrome, using broken HTML on YouTube to make it render slowly on Firefox & Microsoft Edge to push Chrome distribution, all the dirty stuff Google did to violate user privacy with overriding Safari cookies, buying DoubleClick, stealing the ad spend from banned publishers rather than rebating it to advertisers, creating a proprietary version of HTML & force ranking it above other results to stop header bidding, & then routing around their internal firewall on display ads to give their house ads the advantage in their ad auctions, etc etc etc) and then just throw over a billion dollars a month needlessly at a syndication partner.
For perspective on the scale of those payments consider that it wasn’t that long ago Yahoo! was considered a big player in search and Apollo bought Yahoo! plus AOL from Verizon for about $5 billion.
This is right — Google was once an extraordinary product, but over time became stagnant & too grabby of random revenue as it ate its ecosystem. Makes it the right time to force Google to try and compete without reaching for its bribery checkbook
https://t.co/gDhtDMjfo0— Tim Wu (@superwuster) September 22, 2023
If Google loses this lawsuit and the payments to Apple are declared illegal, that would be a huge revenue (and profit) hit for Apple. Apple would be forced to roll out their own search engine. This would cut away at least 30% of the search market from Google & it would give publishers another distribution channel. Most likely Apple Search would launch with a lower ad density than Google has for short term PR purposes & publishers would have a year or two of enhanced distribution before Apple’s ad load matched Google’s ad load.
It is hard to overstate how strong Apple’s brand is. For many people the cell phone is like a family member. I recently went to upgrade my phone and Apple’s local store closed early in the evening at 8pm. The next day when they opened at 10 there was a line to wait in to enter the store, like someone was trying to get concert tickets. Each privacy snafu from Google helps strengthen Apple’s relative brand position.
While Google’s marketshare is rock solid, the number of search engines available has increased significantly over the past few years. Not only is there Bing and DuckDuckGo but the tail is longer than it was a few years back. In addition to regional players like Baidu and Yandex there’s now Brave Search, Mojeek, Qwant, Yep, and You. GigaBlast and Neeva went away, but anything that prohibits selling defaults to a company with over 90% marketshare will likely lead to dozens more players joining the search game. Search traffic will remain lucrative for whoever can capture it, as no matter how much Google tries to obfuscate marketing data the search query reflects the intent of the end user.
Courtesy of SEO Book.com
Category seo news | Tags:
Social Networks : Technorati, Stumble it!, Digg, de.licio.us, Yahoo, reddit, Blogmarks, Google, Magnolia.