Archive for the ‘seo news’ Category
Saturday, August 6th, 2022
Technically the new feature was released in 2021, but only to a small number of users. But now Google is slowly ramping up a tool they label “Organise keywords into ad groups.” This was first brought to our attention on Twitter by Tauqueer Aziz, and confirmed by a Google spokesperson today.
What Google says. Google confirmed the new feature in a statement today:
You could always manually choose to add keywords to ad groups (manually picking which ones to add where). This feature adds the ability to use an automated machine learning system where we suggest which ad groups are the best ones for the keywords, instead of you manually doing the placement.
This should hopefully save advertisers time and effort if they have thousands of keywords/ad groups to sift through. The ability to manually add keywords still exists.
Why we care. This new feature aims to save advertisers time by automatically allocating keywords into relevant ad groups. But just like with most automation, use with caution. Test, analyze, and adjust as necessary.
The post Google Keyword Planner gets a new feature appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Saturday, August 6th, 2022
Google has just announced an issue regarding Impression Share and Auction Insights reporting data.

What Google says. This has been a known issue since August 3 and Google is working on a resolution. An update will be provided by August 6. Google says the issue has no impact on ads serving or automated bidding strategies.
Why we care. Advertisers experiencing issues with either of these data reports should keep checking the ads status dashboard for updates.
The post Google addresses Impression Share and Auction Insights reporting issue appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Friday, August 5th, 2022

Search Engine Optimization is no longer a do-it-yourself project unless you have a solid decade or so handling digital marketing and the latest Google algorithm changes. Making websites and web pages more relevant, authoritative, and mobile-friendly is now an essential part of any overall business plan.
Search Engine Optimizing produces better rankings on all search engines. The focus is mainly on Google because 92% of all web queries happen on Google. Followed in much smaller percentages by Bing, Yahoo, Baidu, Yandex, and Duck Duck Go. Google is still the King.
Companies seeking to compete in today’s marketplace need to understand that making websites and web pages more relevant and authoritative is now an essential part of their overall business plan. Gone are the days of taking shortcuts and using misleading titles and junk links to improve search engine rankings.
Current algorithms rely heavily on activities and accumulative quality information from billions of internet users. Google changes its algorithms daily, which is another reason to bring digital marketing and SEO professionals onboard to track and adjust to regular changes.
You know it goes much deeper than picking five or six keywords and stuffing your content with those words. Keyword stuffing is an exercise in awkward quantity over true quality. It doesn’t fool today’s search engines, algorithms, or potential customers.
As you know, there is a lot to remember when considering SEO for your website. This is why bringing in the best SEO company with the latest trending SEO services for your website is crucial to your success.
What is an SEO company, and how can they help?
An SEO Company will improve your organic traffic from search engines. More than a trillion questions are put into search engines each year. If you want to capitalize on this, you’ll want the best agency to help you stand out above your competitors.
SEO can be very complicated, but you won’t have to guess what’s working and what isn’t because a quality SEO company will be able to measure and report to you about each optimization strategy and how it is performing. From there, the agency will be able to adjust and improve its plan to get you higher rankings, increased website traffic, and a growing number of users.
Agencies that provide SEO services for your website take on multiple tasks, including ensuring your site loads quickly and contains all clean code with quality content that is the most effective at landing web searches onto your site.
Many global SEO agencies are out there, and you have probably heard of some from this list. You will want to pick the best one for your company’s goals, your industry, the country or countries where you want to attract clients, as well as whether you need better marketing, backlinks, or you need help to understand exactly what steps you need to take to grow your company and make it more profitable.
Here’s who can claim the title of “the best,” according to customers and industry experts.
List of best SEO companies across the globe
❖ About the Company: Possibly the very best SEO company out there. RankZ goes on to provide a full array of services. It gets high scores from customers for positive client experiences and measurable positive results. The RankZ team has exceptional experience with winning strategies for e-commerce, small businesses, and start-ups. This company also offers outstanding tools for clients who like to stay hands-on in optimizing their site or content.
❖ Services: Search Engine Optimization, Content marketing, pay-per-click, web design, blogger outreach, infographics marketing
❖ Pricing – Pricing starts at $1000 and can go up to $10,000 mo based on the competition and the number of pages.
❖ About the Company: Ranked as one of the best link-building companies in the market. OutreachZ is an international agency with a client list of more than 1,000 start-ups, brands, and digital agencies. It also maintains a guest posting marketplace with robust 5,000+ connections with experts in their various fields. Also on offer for clients is the premium managed campaigns feature. The team delivers the right publishers for each client based on their requirements. An excellent tool for gaining powerful links.
❖ Services: Link building platform to take control of off-site SEO. There’s a guest posting marketplace connecting to authoritative publishers. The agency handles prospecting, blogger outreach, content production, and placement.
❖ Pricing: Average Link Building budget is usually $500 but can be lower or higher depending on your goals.
WebFX
❖ About the Company: A leading digital marketing agency. Customers get a full range of services with an individual strategy tailored just for them. Growth strategies are developed for each customer based on their particular goals and needs. Along with award-winning digital marketing services, WebFX has its own proprietary technology platform. This agency focuses on successful digital marketing campaigns to increase leads, customer calls, transactions, and qualified website traffic. Company offices are all located in the United States.
❖ Services: SEO, link building, PPC, media buying ad spend, website call tracing, SMM, and web design.
❖ Pricing: SEO prices per month are $1,000+, and the average hourly rate is $150-$199/hour
Webimax
❖ About the Company: WebiMax can back up its promise “Remove the negative, promote the positive!” This award-winning reputation management company delivers year after year. This agency is results-driven. Every month SEO results are shared with clients to be communicative and transparent.
WebiMax founders say they want clients to feel they’ve gained a strategic partner to help the business grow, not just hiring an outsourced vendor.
❖ Services: Reputation management, search engine optimization, pay-per-click marketing, social media marketing, lead generation, website design, and online public relations
❖ Pricing: Bespoke pricing.
OuterBox
❖ About the Company: OuterBox offers a suite of web services while focusing on helping companies expand and increase online sales. Its PPC management and pay-per-click services have a proven high rate of return on investment. It offers an array of digital marketing and SEO packages tailored to each client. OuterBox values the team approach and promises a cohesive approach to online marketing strategy to improve business.
❖ Services: SEO, paid search, digital marketing campaigns, web development, web design, eCommerce
❖ Pricing: SEO prices per month are $1,000+ and average hourly rates of $100 – $149/hour
SeoTuners
❖ About the Company: One of the best specialists in digital marketing. Also prized by clients for business development strategy. This company pledges never to use black hat SEO techniques. Instead, its experts promote web resources using ethical SEO. SEOTuners focus on building powerful websites to provide an increasingly successful market presence. The agency pledges an ethical approach to all work toward getting positive ranking results in search engines for client websites.
❖ Services: SEO, branding, E-commerce development, PPC, conversion optimization, SMM, and web development
❖ Pricing: SEO prices per month are $1,000+ and average hourly rates of $150 – $199/hour
Blue Fountain Media
❖ About the Company: Blue Fountain focuses on modern and emerging technology to develop successful business growth strategies. SEO changes fast, presenting new challenges almost daily, whether algorithm changes or the impact of voice search and Blue Fountain strives to stay at the head of the pack. In addition to optimizing content, this agency optimizes the technical side with reviews of wireframe mockups and redirects.
❖ Services: Website design, digital marketing, mobile app design, website development, strategy, branding, and experience design
❖ Pricing: Minimum project size: $50,000
Delante
❖ About the Company: Experienced in helping B2B and B2C businesses create and manage internal SEO strategies. They’re open to even the smallest start-up clients. Their client list includes businesses in the e-commerce industry as well as finance, automotive, SaaS, IT, cosmetics, healthcare, fashion, wellness, and more. Delante’s clients enjoy higher website visibility and rankings on the first pages of Google results. The team specializes in long-tail SEO to bring in more users ready to buy.
❖ Services: SEO, link building, SEO consulting
❖ Pricing: Minimum project size: $1,000
Mayple
❖ About the Company: One of the best SEOs for small businesses. It also offers SEO solutions to major brands. Marketing results and managing content are among Mayple’s forte. Each client receives a plan of action specific to their company and goals. The team is made up of experienced marketing experts with exceptional knowledge in specific fields to serve their clients. Mayple drills down to the client’s industry, target audience, and KPIs for measurable positive results.
❖ Services: Business consulting, digital strategy, SEO
❖ Pricing: Minimum project size: $1,000
iSynergy
❖ About the Company: Top-of-the-line programmatic advertising, inbound marketing, and SEO campaigns are all included as part of available marketing services. The focus is on data-driven design with marketing technologies. iSynergy team members take a creative approach to creating a data-driven strategy. They promise well-built websites that develop the client’s brand story by creating memorable digital experiences. The company’s strategy is quality over quantity to give website visitors the information they’re seeking without creating content overload.
❖ Services: SEO, web design, conversion optimization
❖ Pricing: Minimum project size: $5,000
What services do SEO companies provide?
Here’s what you need to know to find the best SEO agencies globally.
The best International SEO firms in the world will masterfully promote your site to ensure prospective clients and customers find it. In addition, an agency can provide a holistic approach to making your company visible and valuable by putting an experienced team to work for you. Therefore, hiring a highly rated agency ends up being cost-effective at the front end and ultimately profitable.
In addition to search engine optimization, a talented SEO Agency will create a content marketing strategy and position your company to benefit from pay-per-click marketing on multiple search engines and popular social platforms while ensuring a good return on investment (ROI).
You’ll want to ensure the SEO company you’re considering hiring is genuinely one of the best by finding out how they capitalize on the fertile ground of user intent. Of course, keywords and phrases remain important, but user intent is a recent SEO star on the scene.
User intent means your content reaches people using search phrases similar or related to your keywords even though they’re not an exact match. Think of it as creating excellent content that touches on your potential customer or client’s wants, even if they’re not using your specific keywords to find the information.
Qualities of the best SEO company
Having an exceptional SEO Company plan and carry out your web content optimization efforts isn’t an exercise in “set it and forget it.”
Markets change, and customer priorities change, as do Google algorithms. To be successful, your SEO must respond and change, too.
People on your SEO agency team should check how things are going every day by viewing keyword position analytics as well as website performance numbers. An SEO expert should also review where the heaviest website traffic originates to see what’s getting you the best results and getting your company the most attention.
Keyword research should be a regular activity. Algorithms may change, but keyword ideas won’t fluctuate as much. Your SEO expert should keep a close eye on search volume and relevance to the questions people are asking and ensure the right words and phrases are correctly placed.
Optimizing content goes beyond researching and using high-value keywords. Members of your SEO team need to ensure your site contains quality metadata with super-clean code structure and proper internal linking. This process of bringing different strategies together simultaneously gets you to a higher ranking.
Top tips for choosing the best SEO agency
The best SEO agency for your small, medium or large business will customize services to meet your goals. Ask to see specific numbers showing how they’ve performed for other clients. Ask for references and check with agency clients. Find out whether the agency feels like the right fit for you.
A quality SEO agency will be able to provide examples of their success for other clients in the form of page loading speed, number and quality of incoming links, keyword phrase usage, HTML and schema mark-up, mobile optimization, and domain authority.
The best SEO firms in the world explore the client’s goals, needs, and expectations. The best don’t take a cookie-cutter approach; each client gets their own customized plan.
The SEO agency you’re considering should be able to explain how they keep an eye out for any changes or updates to techniques and how they stay agile to tailor new information to optimize your website pages better. Identifying the most valuable long and short-tailed keywords, capturing user intent, and expert placement of excellent coverage are important pieces of the puzzle.
When an SEO agency is pitching to you, it shouldn’t feel like they promise magical results. Instead, it should be happy to share its strategies and examples of past successful campaigns for other clients.
You need to know who will be on your team within the SEO company. The very best SEO agencies encourage their employees to improve their skills constantly. Find out how often the SEO company employees conduct research specific to understanding changes in the algorithms Google and other search engines use. An expert-level company will also provide in-house training specific to new SEO tools and the ways digital media influences the overall market.
You should also be able to check out the SEO agency’s investment in tools and technology to harness best practices for its clients.
SEO for business growth
SEO gives you the power to answer the questions people ask, specifically those in your field. This increases your visibility, potentially on a global stage. As a result, the amount of traffic to your website and pages should grow. As the number of visits to your pages goes up, you become an authoritative voice in your part of the market. People will trust that voice more and more and therefore trust your brand and products or services.
Identifying relevant keywords and providing quality content (not clickbait) is essential. The meta-text is vital so search engines can hit on those as valuable content.
General SEO and local SEO
There’s general SEO and local SEO. SEO agencies best for small businesses will help hyper-focus local content to grab “in city” or “near me” searches. The beauty of great rankings from local SEO is that the majority of users who conduct city, region, or state searches are ready to do business and ready to pick a company. That’s a solid reason to anticipate higher conversion rates.
Providing specific, uniform information about your company is important in local SEO. Your business name and contact information is a simple place to get gains using Google My Business along with website information. Be sure the company name, address, phone number, and contact email address are exactly the same wherever they’re used.
Research shows that including photos on your site has been found to result in 30% more visits and higher. Active blog posts also improve rankings. Also, schema markup, which is a vocabulary of tags or microdata that can be added to the HTML to improve the way search engines read and express the page in the SERPs because schema helps algorithms recognize how pieces of content relate to each other.
You may find that the SEO agency you hire will submit your site to online directories to make your URL easier to find. For example, you may hear reference to GMB (Google My Business). This can be valuable because it gives you a peek into how users interact with your business profile and the most popular content there.
Invest in quality content creators. The content you put on your website is a service to current and potential customers. It sets the tone for your company’s professionalism and abilities. Consider blog content, videos with written text content to go with them, and photographs because the more people access your different types of content, the more heavily search engines will point to your page rather than competitors.
Hiring one of the best SEO agencies for your company means putting affordable web design and search engine optimization to work for the most profitable results.
Top 10 core elements of SEO
An SEO specialist must have significant knowledge about a wide variety of activities to push a client higher on Google search results pages.
When considering which SEO agency is the best for your business, consider these top ten activities, which are the most important to you, and which agencies have the best reputation for delivering quality:
1. Build an SEO strategy with on-page and off-page SEO
2. Research and identify relevant keywords
3. Competitor website research
4. Identify gaps in competitor strategy which can be used to boost your online presence.
5. Technical audits on load times, status codes, and crawl errors
6. High-quality link building
7. Create a cooperative plan to optimize both search engines and visiting users
8. Daily review of algorithm updates, change strategy as needed and use ethical techniques.
9. Regularly monitor results of SEO campaigns with an eye for how to improve
10. Manage necessary digital tools, including Google Search Console and Analytics, and SE ranking software
On-page SEO
The code and content of your website and web pages that you control are called on-page SEO. It includes text, headings, links, and photos or videos.
On-page SEO is the vital foundation for improving search rankings. It’s what a quality SEO company will craft for the best business results, including title tag, images, keyword research and placement, description meta-tag, optimized URLs, and sitemap.
On-page SEO comprises standard technical procedures that can be studied and implemented to boost rankings.
Off-page SEO
Off-page SEO is all the things that do not originate on your website but help your site get higher search rankings.
The primary focus of off-page SEO is getting valuable backlinks, which are links that point to your site from other high-quality websites. Off-page SEO is an open-ended process requiring creativity by the SEO specialist to make your content valuable enough that another site wants to refer its visitors to you.
Evolution of SEO
The internet became available to the public in the summer of 1991. Right around six years later, the notion of Search Engine Optimization came on the scene.
Search engines are behind almost every online destination, and they changed how we find information and answer our questions.
In modern times search engine optimization mainly orbits Google. The industry has seen other search engines come and go, but Google continues to reign supreme.
At the start, ranking high up on search engines was essentially directory-driven. Slap “AAA” at the front of your business name and see the gains.
The eternal goal of being number one soon moved beyond ranking based on domain names, on-page content, and alphabetical directories to complicated metrics and algorithms. For example, Google’s PageRank algorithm is notable for making history in the arena of information retrieval.
Social networks exploded onto the scene in the 2,000s. YouTube, Facebook, Twitter, and LinkedIn would spark many similar sites. Experts suspected social signals could impact search rankings, and it did by helping SEO and also driving additional traffic to websites boosting brand awareness and loyalty.
The next steps brought improvements in detecting user intent and a new algorithm that advanced conversational searches.
Mobile phones changed the SEO world again in 2015 when mobile searches topped the number of Google searches performed on a desktop for the first time.
SEO strategies
Start with the basics by knowing which industry you’re competing in and who your target audience is. Then it’s time for keyword research further evolve into content that satisfies user intent behind the search terms.
Accurate reporting is a necessary strategy to hit on successful SEO. Absent correct reporting results, you and your team are not able to make precise adjustments and improvements.
Google’s mobile-first index is aimed at making sure websites look professional and perform well on mobile devices. That functionality must be in addition to, not instead of, laptop and desktop search optimization.
Employ excellent contract creators either within your SEO agency or possibly bring one or more writers directly on board. These experienced professionals will easily skip over the pitfalls many lesser creators make. Mistakes that will hurt you include keyword stuffing and spammy or click-bait content. Your site loses credibility and may anger visitors and potential clients, so aim for blogs and articles that may go viral simply because the information and writing are just that good!
Linking to high-quality web pages is nearly as valuable as getting backlinks because your content is so good. Always double-check that links are working. Error 404 messages can derail your best efforts.
Beyond on-page and off-page SEO, there are good guys and not-so-good guys in the SEO world.
White hat SEO
White hat SEO follows a solid strategy that adheres to search engine rules and best use guidelines.
There’s no trickery in white hat SEO. Truly solid content and coding are used rather than attempting to manipulate or fool a search engine or the user. Think no spam, no clickbait, no loading links that point everywhere but leave the user with very little usable information.
You may also hear it called ethical SEO. It follows accepted rules and is intended to produce long-term positive results. Not just a quick hit that will fade back to or below previous sales levels.
There’s a reward for following the rules and not trying to get around regulations or trick the system. Namely, following proper policies and guidelines will push your site higher in search engine results. Combined with engaging authoritative content, you may even find yourself in the top rankings.
Black hat SEO
Then there is black hat SEO which is considered rather dirty dealings.
Black hat SEO employs techniques specifically intended to manipulate or deceive search engines and users. For example, it may try to trick a search engine’s algorithm to get good results and higher rankings without doing good content and code creation work.
Such unethical methods go against search engine guidelines and could completely remove your site from the engine’s database index. So the risk is certainly not worth any possible short-term reward.
A deeper dive will show that a black hat SEO strategy may produce a sudden rise in organic listings, but the search engines will soon sniff out the rule-breakers bringing penalties to your door.
If an SEO agency proposes any of the following strategies, know they’re talking about using black hat SEO:
● Doorway pages
Pages with no real value are built only for ranking specific keywords, but ultimately the homepage or other doorway pages are basically useless.
● Hidden links or hidden text
This sneaky technique camouflages certain text or links by making them the same color as the background color.
● Cloaking
Cloaking presents a web page to search engines that are different from what users see. Cloaking tricks search engines into displaying a page; it would not show up if proper keywords and user internet were used.
● Link farms
Link farms are intended to create a large number of sites whose sole purpose is to point back to your site through links. However, this artificially inflates the number of backlinks which can throw a search engine off in the short term by masquerading as an authority site.
● Keyword stuffing
One of the original ways to attempt to spam search engines into ranking sites higher. Increasingly it’s completely ineffective because it can’t stand up to ever-changing algorithms. Seeing the same word or phrases all over a page to the point it’s completely unnatural usage; the page has been stuffed.
It’s always a bad idea to attempt to manipulate search engines with the intention of misleading users. Sooner or later, your site will be found out for using unscrupulous methods, and search engines can ban your site altogether on the basis of it using any black hat tactics.
Link building for SEO
Backlinks are a coveted SEO ingredient. They’re links from other authoritative sites that point back to you and your content by linking their web page to yours. It’s pretty difficult to fake, so having another web content creator decide to pass their visitors along to you is incredibly valuable.
Backlinks are also called one-way hyperlinks. Link-building strategies include public relations, email outreach efforts, broken link building, and content marketing.
The goal is always to improve search engine visibility.
The future of SEO
Mobile optimization, ensuring your website works and displays well on mobile devices, is now the metric that helps push your site higher in search engine results. Optimization has to include both Apple and Android products.
It’s one more thing to monitor regularly and course-correct as needed. You must still ensure your website view for desktop and laptop computers remains optimized.
SEO rankings continue to get more competitive. This is because Internet users are becoming savvier at spotting quality content and sites over those trying to beat the system for ranking.
Now SEO tactics have to evolve and improve continually. In addition to mobile optimization, matching user intent is now required for success. The idea is not just to give users a bunch of links but to actually assist them in finding the information they want.
Machine learning is now built into all of Google’s products, including Ads and Gmail. The impact of machine learning can be seen with Google’s RankBrain, which now runs on every search. In addition, intelligent searches now have to cater to visual and voice searches, chatbots, and personal assistants such as Siri and Alexa.
SEO specialists will have to keep up with all the technological advances to keep their skills and services top-notch.
Final thoughts on choosing the best SEO agency
The best SEO companies’ reputations boil down to whether they deliver demonstrable results. Clients are right to expect realistic results and good communication about what is happening if they’re going to include hiring an SEO agency in the budget.
Among expected results from a well-run SEO campaign include increases in your website’s visibility and results that show improvements in brand awareness. The bottom line should improve with increases in sales. It should help you compete successfully against businesses very similar to yours. New customers should be getting in touch with you to buy your products or services. You should see a higher return on investment (ROI), including higher conversions and ultimately more sales. And an agency’s deliverables shouldn’t be a short bump in traffic and sales. Done right, you should be getting long-term results, including long-term increased revenue.
Having a solid and respected online presence is the lifeblood of a successful business these days. Brick and mortar locations simply are not enough for today’s consumers.
Warning signs of SEO companies that talk a good game but may not deliver valuable results are those with aggressive self-promotion methods and aggressive marketing strategies meant to land new customers. SEO success can be measured and reported, so it’s a big red flag if a company balks at showing you their record with other clients.
SEO specialists have to juggle many tasks, even at agencies where different colleagues focus on different portions of an SEO strategy. However, most of the skills complement each other, so you can expect dependable service from any team member when you need it.
We hope this guide has been helpful in finding the right SEO company, especially with so many SEO agencies in the picture; finding the best one that fits your needs could be overwhelming.
The post The 10 best SEO companies across the globe appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Friday, August 5th, 2022
Google has added structured data support to read and potentially use pros and cons for product review snippet in the Google Search results. Google said you can now “tell Google about your pros and cons by supplying pros and cons structured data on editorial review pages.”
Pros and cons look like. Here is a screenshot of pros and cons showing in the Google Search results snippets:
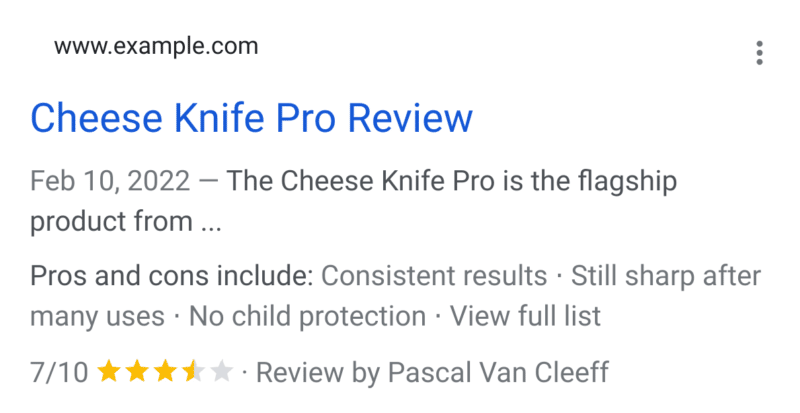
Documentation. Google added a new section to the documentation over here that reads “Pros and cons: Help people see a high-level summary of the pros and cons of an editorial product review. The pros and cons appearance is available in Dutch, English, French, German, Italian, Japanese, Polish, Portuguese, Spanish, and Turkish in all countries where Google Search is available. While Google tries to automatically understand the pros and cons of an editorial product review, you can explicitly provide this information by adding the positiveNotes and/or negativeNotes properties to your nested product review. Be sure to follow the pros and cons guidelines.”
You can see sample code over here.
Test tool. Google updated the Rich Results Test to check for pros and cons structured data in addition to all the other structured data types supported by Google Search, the company said. Google said you can use this tool to validate and confirm your structured data is proper and Google can read it.
Guidelines. Google added that if you add pros and cons structured data, you must follow these guidelines:
- Currently, only editorial product review pages are eligible for the pros and cons appearance in Search, not merchant product pages or customer product reviews.
- There must be at least two statements about the product. It can be any combination of positive and/or negative statements (for example, ItemList markup with two positive statements is valid).
- The pros and cons must be visible to users on the page.
Structured data not required. Google said even if you do not add structured data, Google may still show pros and cons. I actually spotted this about a month ago in the wild. Google wrote, “If you do not provide structured data, Google may try to automatically identify pros and cons listed on the web page.”
Google did say it “will prioritize supplied structured data provided by you over automatically extracted data.” So it is probably best you do add the structured data, if you have it.
Why we care. Anything you can do to improve your click-through rate from Google Search to your website is a good thing. Adding more elements and rich results to your search snippet may help you improve clicks. So give it a try and test it out.
The post Google adds structured data support for pros and cons on product markup appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Friday, August 5th, 2022
Google Discovery ad users may see a few new features starting today. Google says these features are aimed at helping keep audiences engaged throughout the upcoming holiday season. The new features are:
- Better ad experiences
- Improved creative support
- New insights
- Enhanced campaign management
Better ad experiences
Google says that they’re working on making ad experiences more browseable in the Gmail Social and Promotions tabs by including richer details, like product images and prices. They’ll also use machine learning to match the asset to the right audience at the right time.
Improved creative support
The onboarding flow for creating Discovery ads has been rebuilt. During the ad creation, advertisers will see prompts to add additional aspect ratios, unique headlines, and adding text overlays across images. Users will also receive live feedback on ad strength with ratings from “Poor” to “Excellent,” as well as an optimization score with actionable guidance.
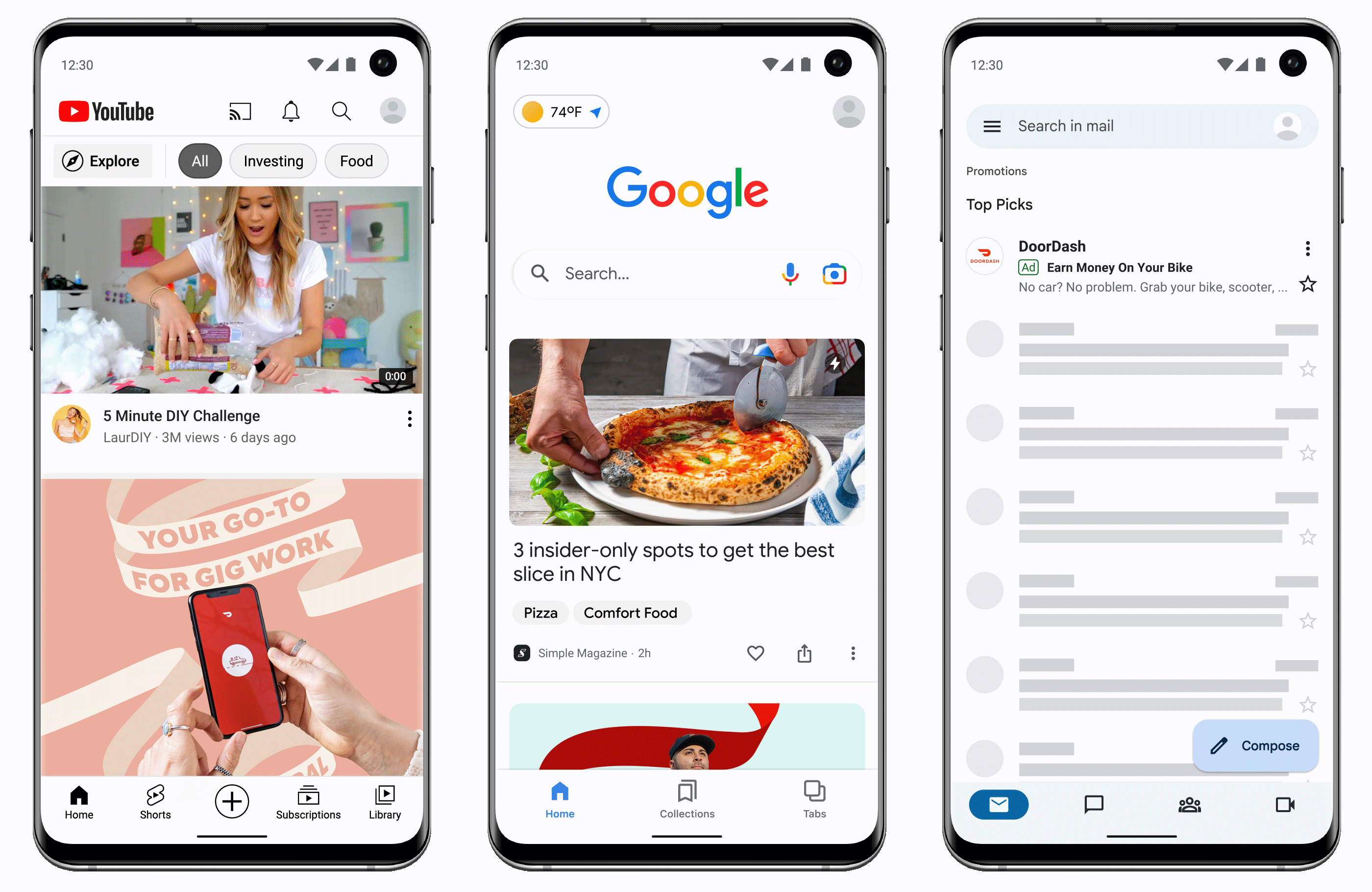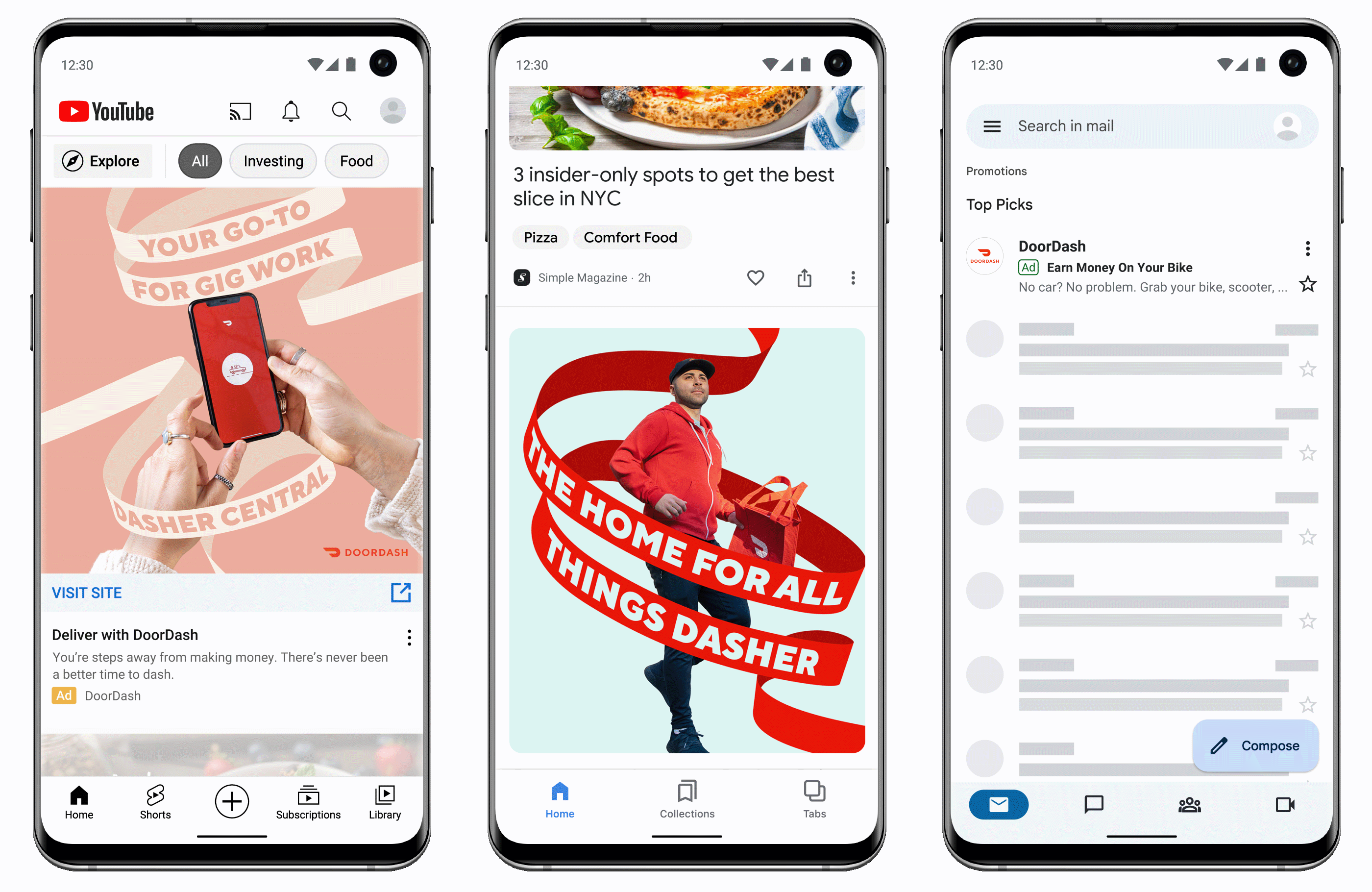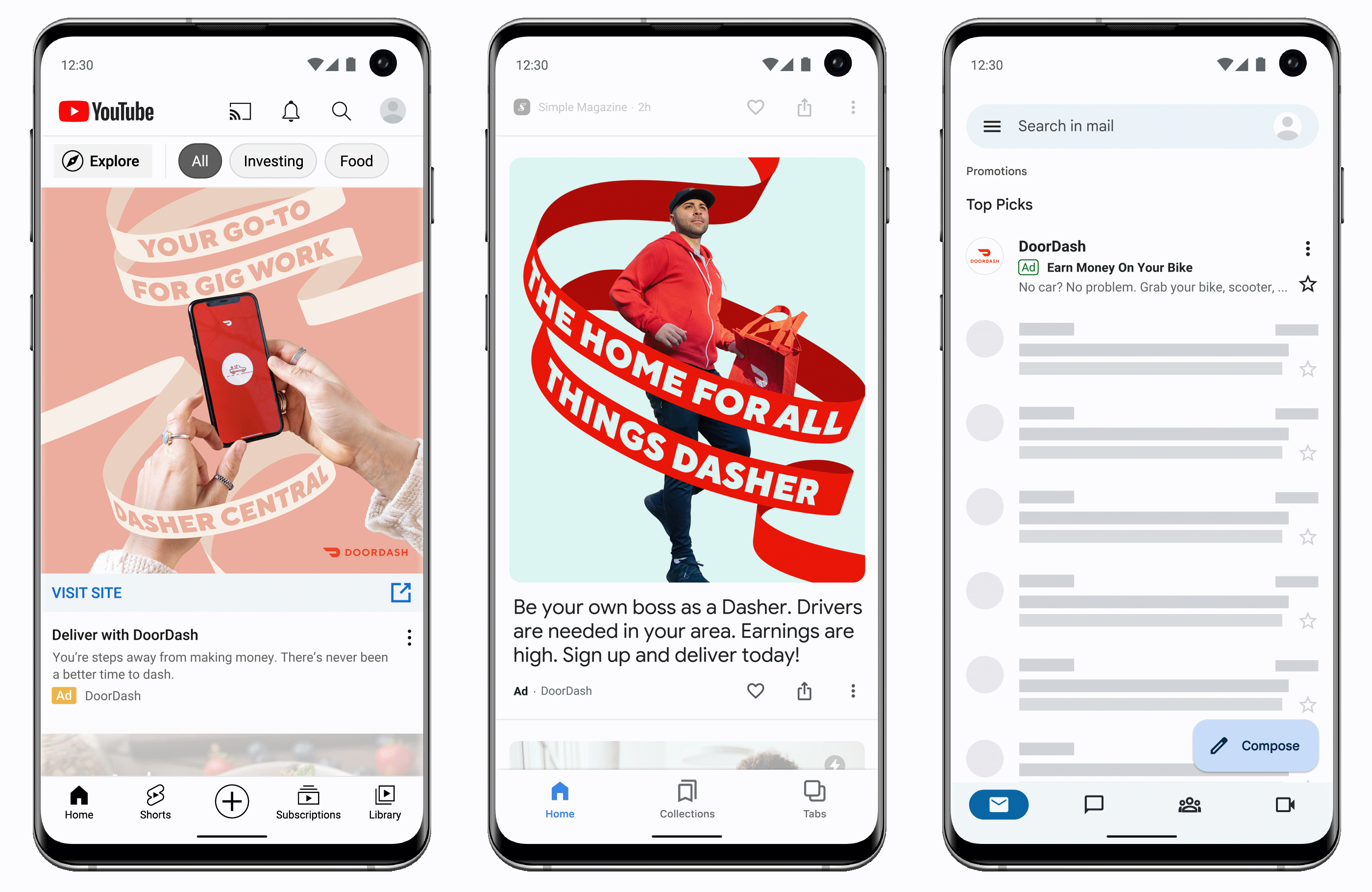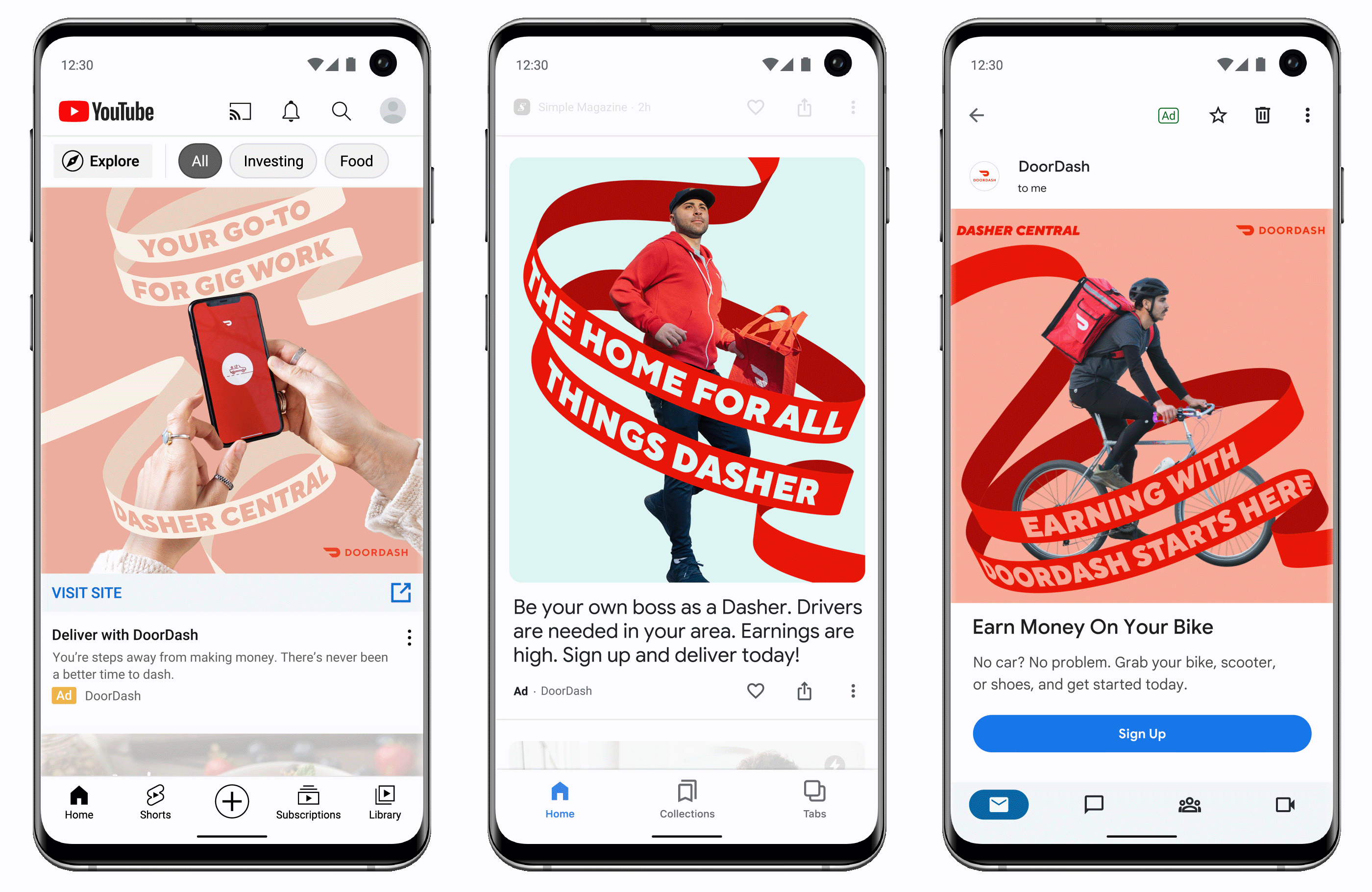
New audience insights
Discovery advertisers can now use the insights page to see which audience segments may deliver the biggest impact. Advertisers can also use asset reporting to view performance across the Discovery ads. Users can compare the performance between assets and decide which ones to turn off, switch, or edit. Advertisers can also use optimized targeting to assess information about keywords and landing pages to find audiences that can meet your campaign goals.
Enhanced campaign management
There is a new audience builder advertisers can use to create and reuse audiences across campaigns. Users can also use the Google Ads Editor as well as API to manage campaigns at scale.
What Google says. You can read the full announcement from Google in their help guide.
Why we care. New and old users of Discovery ads should test these features before going all in. Only you know your audiences and KPIs. Following Google Best Practices is a great place to start, but adjust as necessary and always review auto-generated assets.
The post Google announces 4 new features for Discovery ad users appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Friday, August 5th, 2022

Link building can be an overwhelming venture for those just starting. However, it is an essential part of SEO that all industry experts must learn.
In this webinar, Page One Power link-building experts are spilling their secrets on how to vet links, succeed at outreach, and which link-building strategies to keep and which to skip.
Register today for “SEO Recon: The What, Why, and How for Building Amazing Links,” presented by Page One Power.
The post Webinar: Secrets to link building from SEO experts appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Thursday, August 4th, 2022
As marketers, we got used to letting social media platforms (and Facebook in particular, a.k.a. Meta) do our work for us.
We let these platforms follow the customer journey from our ads all the way to conversion. We let them watch. We let them learn and we let the algorithm optimize and target the proper audience.
The algorithm did everything. It was comfortable and easy.
At the very beginning, Facebook used to share that information with us and we could learn at the same time as the algorithm learned. We used to be able to analyze our audience, our followers, what they liked, what age they were, what gender, marital status, what other websites they visited, and what other pages they followed. We knew as much as the algorithm did.
But then that information was no longer available. Yet we didn’t care because the algorithm was doing its thing and we were getting amazing results. So we got comfortable, too comfortable.
Fast forward to April 2021 and the iOS 14.5 release
The world for marketers using Meta imploded a bit.
For some, it imploded a lot.
Users had to be asked for permission to be tracked across apps and websites and 95% of them decided not to give such permission in the U.S. (84% worldwide).
Since then, social media platforms have had terrible visibility into what is happening to people that click on an ad. Once they leave Meta that is pretty much it!
Meta has done some work to provide estimates. But in my experience things like landing page arrivals or even conversion attributions are far from the real numbers (thanks to Google Analytics and UTMs for the backup tracking ability).
Interest-based targeting is one of the few tools we have left.
So the theory is to feed the funnel with cold leads at the brand awareness stage so that they flow through the funnel and convert without barriers.
There is one problem: because algorithms still have trouble determining positive interaction from negative interaction and, for that matter, they have trouble understanding context – engagement and interest with a particular brand may not mean that they want to be approached by that brand.
Interest-based marketing is a good starting point but misses the mark many times.
Researchers analyzed the accuracy of Facebook activity on their interest-based ads and found that almost 30% of interests Facebook listed were not real interests. That means that if your ad is based on the list of interests, you could miss the mark about 30% of the time.
This study is the first of its kind and has a relatively small dataset, but looking at comments and the engagement generated in interest-based ads I have run, I see the biggest percentage of confused and unhappy comments on this ad set, so NC State is onto something here.
If you got to this point of the article, you might be re-thinking your life choices as a paid social media marketer.
However, there is something still very useful in the platforms:
Lookalike audiences
Facebook may not have as much information about your converters as it did before, but you – or your clients – do!
Instead of feeding this theoretical funnel to cold audiences, let’s go to the end of the funnel and find people like the converters.
The process is similar in all platforms:
- Get your seed list of converters.
- Create a custom audience with this list by uploading it to your social media platform of choice.
- The platform will match the information to what they know about each person in the platform (most commonly email or phone number).
- There are minimum matches needed for this list to be valid and each platform has its own rules for this.
- Once the custom audience is created and valid we can generate a lookalike audience where we tell the platform “find people with similar profiles” to the people on this list.
By creating lookalike audiences we are taking the funnel and tipping it upside down. We start at the bottom and generate a list of cold audiences so similar to our current converters that they may be almost considered warm audiences.
We are now using the social media platforms to help us create personas based on data we know is accurate and then targeting them.
Platforms know a lot about our behavior within the platform. They are not perfect, but these platform-generated personas are way more accurate than inferred interests.
Why?
Because you are not targeting one interest, one element, that will be irrelevant 30% of the time. You are targeting a group of elements, interests or platform behaviors. That substantially reduces inaccuracy.
After doing A/B tests between interest-based audiences and lookalike audiences I can tell that I have had results improve up to 40% for some lookalike audiences. Sometimes the results are as small as 15% but I will take any improvements and efficiency I can get when optimizing my ads.
Wouldn’t this give too much control back to the algorithms?
Are we setting ourselves up for the same scenario we had pre-iOS 14.5 by letting algorithms run our paid media? Yes and no.
- There is a little bit of trust we are giving back to the algorithms, but now we know not to put all of our eggs in one basket. We know that interests identified by Facebook are still 60-70% accurate, so knowing your audience’s interest is very valid, even if we miss the mark a little bit.
- Audiences shift, their interests change, and we should be moving with them. Can you tell me your audience looks the same now as it did in 2019? My recommendation is to use lookalike audiences as often as possible but complement them with interest-based ads and continuously A/B test their efficiency.
Consider your campaign objective
Sometimes lookalike audiences are good at converting but may not be as good at engagement.
In one A/B split test I run, the interest based audience had 30% higher cost per click but the rate of positive engagement was double. This audience wasn’t converting, they were spreading the message.
We not only need audiences that follow the funnel path to conversion effectively, sometimes we also need audiences that cheer us on and help us spread awareness.
Please consider this before using lookalikes
A lookalike audience is based on a custom list (seed list), and this list should only be created with data you own and have permission to use.
Check each platform’s policies regarding custom lists to understand this better.
Keep your lists and privacy policy updated
If people unsubscribe from your communications, have a plan to update your lookalike audiences.
If people do not want to hear from you, then why would you want to advertise to somebody with the same profile?
Remember: Platforms change over time, so we must evolve with them to stay relevant and sometimes that means going back to basics. Good luck out there.
Watch: Using lookalike audiences to reverse the marketing funnel and generate quality leads
Below is the complete video of my SMX Advanced presentation.
The post Using lookalike audiences to reverse the marketing funnel and generate quality leads appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Thursday, August 4th, 2022
When the acorn that would become the SEO industry started to grow, indexing and ranking at search engines were both based purely on keywords.
The search engine would match keywords in a query to keywords in its index parallel to keywords that appeared on a webpage.
Pages with the highest relevancy score would be ranked in order using one of the three most popular retrieval techniques:
- Boolean Model
- Probabilistic Model
- Vector Space Model
The vector space model became the most relevant for search engines.
I’m going to revisit the basic and somewhat simple explanation of the classic model I used back in the day in this article (because it is still relevant in the search engine mix).
Along the way, we’ll dispel a myth or two – such as the notion of “keyword density” of a webpage. Let’s put that one to bed once and for all.
The keyword: One of the most commonly used words in information science; to marketers – a shrouded mystery
“What’s a keyword?”
You have no idea how many times I heard that question when the SEO industry was emerging. And after I’d given a nutshell of an explanation, the follow-up question would be: “So, what are my keywords, Mike?”
Honestly, it was quite difficult trying to explain to marketers that specific keywords used in a query were what triggered corresponding webpages in search engine results.
And yes, that would almost certainly raise another question: “What’s a query, Mike?”
Today, terms like keyword, query, index, ranking and all the rest are commonplace in the digital marketing lexicon.
However, as an SEO, I believe it’s eminently useful to understand where they’re drawn from and why and how those terms still apply as much now as they did back in the day.
The science of information retrieval (IR) is a subset under the umbrella term “artificial intelligence.” But IR itself is also comprised of several subsets, including that of library and information science.
And that’s our starting point for this second part of my wander down SEO memory lane. (My first, in case you missed it, was: We’ve crawled the web for 32 years: What’s changed?)
This ongoing series of articles is based on what I wrote in a book about SEO 20 years ago, making observations about the state-of-the-art over the years and comparing it to where we are today.
The little old lady in the library
So, having highlighted that there are elements of library science under the Information Retrieval banner, let me relate where they fit into web search.
Seemingly, librarians are mainly identified as little old ladies. It certainly appeared that way when I interviewed several leading scientists in the emerging new field of “web” Information Retrial (IR) all those years ago.
Brian Pinkerton, inventor of WebCrawler, along with Andrei Broder, Vice President Technology and Chief Scientist with Alta Vista, the number one search engine before Google and indeed Craig Silverstein, Director of Technology at Google (and notably, Google employee number one) all described their work in this new field as trying to get a search engine to emulate “the little old lady in the library.”
Libraries are based on the concept of the index card – the original purpose of which was to attempt to organize and classify every known animal, plant, and mineral in the world.
Index cards formed the backbone of the entire library system, indexing vast and varied amounts of information.
Apart from the name of the author, title of the book, subject matter and notable “index terms” (a.k.a., keywords), etc., the index card would also have the location of the book. And therefore, after a while “the little old lady librarian” when you asked her about a particular book, would intuitively be able to point not just to the section of the library, but probably even the shelf the book was on, providing a personalized rapid retrieval method.
However, when I explained the similarity of that type of indexing system at search engines as I did all those years back, I had to add a caveat that’s still important to grasp:
“The largest search engines are index based in a similar manner to that of a library. Having stored a large fraction of the web in massive indices, they then need to quickly return relevant documents against a given keyword or phrase. But the variation of web pages, in terms of composition, quality, and content, is even greater than the scale of the raw data itself. The web as a whole has no unifying structure, with an enormous variant in the style of authoring and content far wider and more complex than in traditional collections of text documents. This makes it almost impossible for a search engine to apply strictly conventional techniques used in libraries, database management systems, and information retrieval.”
Inevitably, what then occurred with keywords and the way we write for the web was the emergence of a new field of communication.
As I explained in the book, HTML could be viewed as a new linguistic genre and should be treated as such in future linguistic studies. There’s much more to a Hypertext document than there is to a “flat text” document. And that gives more of an indication to what a particular web page is about when it is being read by humans as well as the text being analyzed, classified, and categorized through text mining and information extraction by search engines.
Sometimes I still hear SEOs referring to search engines “machine reading” web pages, but that term belongs much more to the relatively recent introduction of “structured data” systems.
As I frequently still have to explain, a human reading a web page and search engines text mining and extracting information “about” a page is not the same thing as humans reading a web page and search engines being” fed” structured data.
The best tangible example I’ve found is to make a comparison between a modern HTML web page with inserted “machine readable” structured data and a modern passport. Take a look at the picture page on your passport and you’ll see one main section with your picture and text for humans to read and a separate section at the bottom of the page, which is created specifically for machine reading by swiping or scanning.
Quintessentially, a modern web page is structured kind of like a modern passport. Interestingly, 20 years ago I referenced the man/machine combination with this little factoid:
“In 1747 the French physician and philosopher Julien Offroy de la Mettrie published one of the most seminal works in the history of ideas. He entitled it L’HOMME MACHINE, which is best translated as “man, a machine.” Often, you will hear the phrase ‘of men and machines’ and this is the root idea of artificial intelligence.”
I emphasized the importance of structured data in my previous article and do hope to write something for you that I believe will be hugely helpful to understand the balance between humans reading and machine reading. I totally simplified it this way back in 2002 to provide a basic rationalization:
- Data: a representation of facts or ideas in a formalized manner, capable of being communicated or manipulated by some process.
- Information: the meaning that a human assigns to data by means of the known conventions used in its representation.
Therefore:
- Data is related to facts and machines.
- Information is related to meaning and humans.
Let’s talk about the characteristics of text for a minute and then I’ll cover how text can be represented as data in something “somewhat misunderstood” (shall we say) in the SEO industry called the vector space model.
The most important keywords in a search engine index vs. the most popular words
Ever heard of Zipf’s Law?
Named after Harvard Linguistic Professor George Kingsley Zipf, it predicts the phenomenon that, as we write, we use familiar words with high frequency.
Zipf said his law is based on the main predictor of human behavior: striving to minimize effort. Therefore, Zipf’s law applies to almost any field involving human production.
This means we also have a constrained relationship between rank and frequency in natural language.
Most large collections of text documents have similar statistical characteristics. Knowing about these statistics is helpful because they influence the effectiveness and efficiency of data structures used to index documents. Many retrieval models rely on them.
There are patterns of occurrences in the way we write – we generally look for the easiest, shortest, least involved, quickest method possible. So, the truth is, we just use the same simple words over and over.
As an example, all those years back, I came across some statistics from an experiment where scientists took a 131MB collection (that was big data back then) of 46,500 newspaper articles (19 million term occurrences).
Here is the data for the top 10 words and how many times they were used within this corpus. You’ll get the point pretty quickly, I think:
Word frequency
the: 1130021
of 547311
to 516635
a 464736
in 390819
and 387703
that 204351
for 199340
is 152483
said 148302
Remember, all the articles included in the corpus were written by professional journalists. But if you look at the top ten most frequently used words, you could hardly make a single sensible sentence out of them.
Because these common words occur so frequently in the English language, search engines will ignore them as “stop words.” If the most popular words we use don’t provide much value to an automated indexing system, which words do?
As already noted, there has been much work in the field of information retrieval (IR) systems. Statistical approaches have been widely applied because of the poor fit of text to data models based on formal logics (e.g., relational databases).
So rather than requiring that users will be able to anticipate the exact words and combinations of words that may appear in documents of interest, statistical IR lets users simply enter a string of words that are likely to appear in a document.
The system then takes into account the frequency of these words in a collection of text, and in individual documents, to determine which words are likely to be the best clues of relevance. A score is computed for each document based on the words it contains and the highest scoring documents are retrieved.
I was fortunate enough to Interview a leading researcher in the field of IR when researching myself for the book back in 2001. At that time, Andrei Broder was Chief Scientist with Alta Vista (currently Distinguished Engineer at Google), and we were discussing the topic of “term vectors” and I asked if he could give me a simple explanation of what they are.
He explained to me how, when “weighting” terms for importance in the index, he may note the occurrence of the word “of” millions of times in the corpus. This is a word which is going to get no “weight” at all, he said. But if he sees something like the word “hemoglobin”, which is a much rarer word in the corpus, then this one will get some weight.
I want to take a quick step back here before I explain how the index is created, and dispel another myth that has lingered over the years. And that’s the one where many people believe that Google (and other search engines) are actually downloading your web pages and storing them on a hard drive.
Nope, not at all. We already have a place to do that, it’s called the world wide web.
Yes, Google maintains a “cached” snapshot of the page for rapid retrieval. But when that page content changes, the next time the page is crawled the cached version changes as well.
That’s why you can never find copies of your old web pages at Google. For that, your only real resource is the Internet Archive (a.k.a., The Wayback Machine).
In fact, when your page is crawled it’s basically dismantled. The text is parsed (extracted) from the document.
Each document is given its own identifier along with details of the location (URL) and the “raw data” is forwarded to the indexer module. The words/terms are saved with the associated document ID in which it appeared.
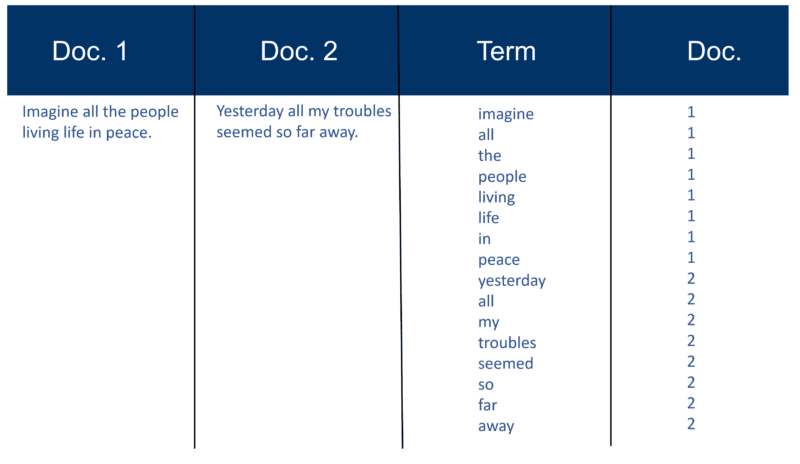
Here’s a very simple example using two Docs and the text they contain that I created 20 years ago.
Recall index construction
After all the documents have been parsed, the inverted file is sorted by terms:
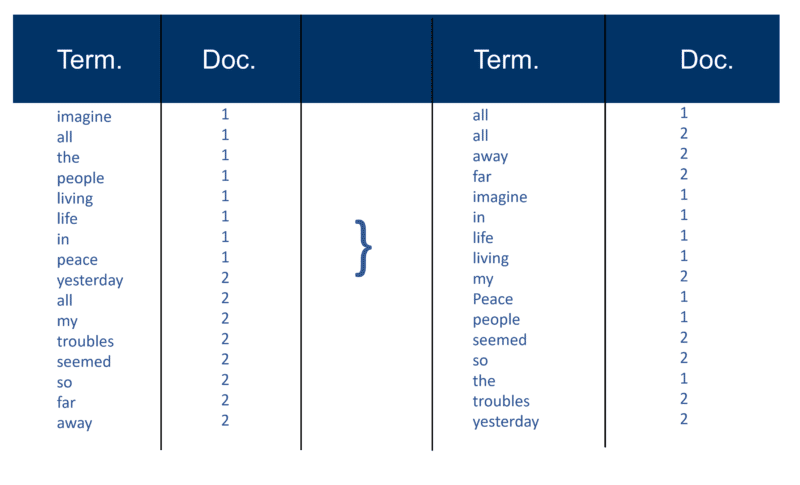
In my example this looks fairly simple at the start of the process, but the postings (as they are known in information retrieval terms) to the index go in one Doc at a time. Again, with millions of Docs, you can imagine the amount of processing power required to turn this into the massive ‘term wise view’ which is simplified above, first by term and then by Doc within each term.
You’ll note my reference to “millions of Docs” from all those years ago. Of course, we’re into billions (even trillions) these days. In my basic explanation of how the index is created, I continued with this:
Each search engine creates its own custom dictionary (or lexicon as it is – remember that many web pages are not written in English), which has to include every new ‘term’ discovered after a crawl (think about the way that, when using a word processor like Microsoft Word, you frequently get the option to add a word to your own custom dictionary, i.e. something which does not occur in the standard English dictionary). Once the search engine has its ‘big’ index, some terms will be more important than others. So, each term deserves its own weight (value). A lot of the weighting factor depends on the term itself. Of course, this is fairly straight forward when you think about it, so more weight is given to a word with more occurrences, but this weight is then increased by the ‘rarity’ of the term across the whole corpus. The indexer can also give more ‘weight’ to words which appear in certain places in the Doc. Words which appeared in the title tag <title> are very important. Words which are in <h1> headline tags or those which are in bold <b> on the page may be more relevant. The words which appear in the anchor text of links on HTML pages, or close to them are certainly viewed as very important. Words that appear in <alt> text tags with images are noted as well as words which appear in meta tags.
Apart from the original text “Modern Information Retrieval” written by the scientist Gerard Salton (regarded as the father of modern information retrieval) I had a number of other resources back in the day who verified the above. Both Brian Pinkerton and Michael Maudlin (inventors of the search engines WebCrawler and Lycos respectively) gave me details on how “the classic Salton approach” was used. And both made me aware of the limitations.
Not only that, Larry Page and Sergey Brin highlighted the very same in the original paper they wrote at the launch of the Google prototype. I’m coming back to this as it’s important in helping to dispel another myth.
But first, here’s how I explained the “classic Salton approach” back in 2002. Be sure to note the reference to “a term weight pair.”
Once the search engine has created its ‘big index’ the indexer module then measures the ‘term frequency’ (tf) of the word in a Doc to get the ‘term density’ and then measures the ‘inverse document frequency’ (idf) which is a calculation of the frequency of terms in a document; the total number of documents; the number of documents which contain the term. With this further calculation, each Doc can now be viewed as a vector of tf x idf values (binary or numeric values corresponding directly or indirectly to the words of the Doc). What you then have is a term weight pair. You could transpose this as: a document has a weighted list of words; a word has a weighted list of documents (a term weight pair).
The Vector Space Model
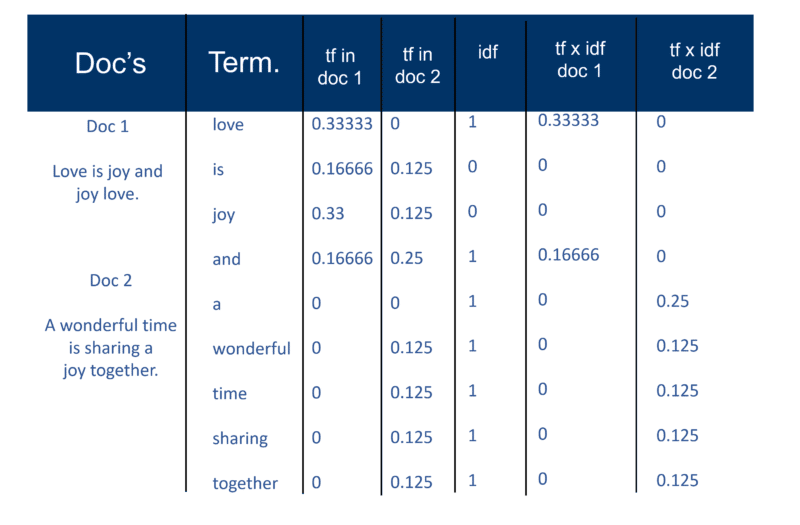
Now that the Docs are vectors with one component for each term, what has been created is a ‘vector space’ where all the Docs live. But what are the benefits of creating this universe of Docs which all now have this magnitude?
In this way, if Doc ‘d’ (as an example) is a vector then it’s easy to find others like it and also to find vectors near it.
Intuitively, you can then determine that documents, which are close together in vector space, talk about the same things. By doing this a search engine can then create clustering of words or Docs and add various other weighting methods.
However, the main benefit of using term vectors for search engines is that the query engine can regard a query itself as being a very short Doc. In this way, the query becomes a vector in the same vector space and the query engine can measure each Doc’s proximity to it.
The Vector Space Model allows the user to query the search engine for “concepts” rather than a pure “lexical” search. As you can see here, even 20 years ago the notion of concepts and topics as opposed to just keywords was very much in play.
OK, let’s tackle this “keyword density” thing. The word “density” does appear in the explanation of how the vector space model works, but only as it applies to the calculation across the entire corpus of documents – not to a single page. Perhaps it’s that reference that made so many SEOs start using keyword density analyzers on single pages.
I’ve also noticed over the years that many SEOs, who do discover the vector space model, tend to try and apply the classic tf x idf term weighting. But that’s much less likely to work, particularly at Google, as founders Larry Page and Sergey Brin stated in their original paper on how Google works – they emphasize the poor quality of results when applying the classic model alone:
“For example, the standard vector space model tries to return the document that most closely approximates the query, given that both query and document are vectors defined by their word occurrence. On the web, this strategy often returns very short documents that are only the query plus a few words.”
There have been many variants to attempt to get around the ‘rigidity’ of the Vector Space Model. And over the years with advances in artificial intelligence and machine learning, there are many variations to the approach which can calculate the weighting of specific words and documents in the index.
You could spend years trying to figure out what formulae any search engine is using, let alone Google (although you can be sure which one they’re not using as I’ve just pointed out). So, bearing this in mind, it should dispel the myth that trying to manipulate the keyword density of web pages when you create them is a somewhat wasted effort.
Solving the abundance problem
The first generation of search engines relied heavily on on-page factors for ranking.
But the problem you have using purely keyword-based ranking techniques (beyond what I just mentioned about Google from day one) is something known as “the abundance problem” which considers the web growing exponentially every day and the exponential growth in documents containing the same keywords.
And that poses the question on this slide which I’ve been using since 2002:
 If a music student has a web page about Beethoven’s Fifth Symphony and so does a world-famous orchestra conductor (such as Andre Previn), who would you expect to have the most authoritative page?
If a music student has a web page about Beethoven’s Fifth Symphony and so does a world-famous orchestra conductor (such as Andre Previn), who would you expect to have the most authoritative page?
You can assume that the orchestra conductor, who has been arranging and playing the piece for many years with many orchestras, would be the most authoritative. But working purely on keyword ranking techniques only, it’s just as likely that the music student could be the number one result.
How do you solve that problem?
Well, the answer is hyperlink analysis (a.k.a., backlinks).
In my next installment, I’ll explain how the word “authority” entered the IR and SEO lexicon. And I’ll also explain the original source of what is now referred to as E-A-T and what it’s actually based on.
Until then – be well, stay safe and remember what joy there is in discussing the inner workings of search engines!
The post Indexing and keyword ranking techniques revisited: 20 years later appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Thursday, August 4th, 2022

You’re invited!
Join Martin Salle, enterprise sales leader from Algolia and AWS, for a special conversation and hands-on solution demonstration.
In this session:
Leaders in every industry use Algolia Search and Discovery to create dynamic digital experiences that drive business results.
Algolia’s flexible search-as-a-service and full suite of APIs allow teams to easily develop tailored, fast search and discovery experiences that delight and convert. To date, Algolia has over 10,000 customers that perform over 10 billion search queries per month.
For marketers, Algolia offers secure, reliable, and scalable tools to easily manage every step of the omnichannel user experience without the need for IT.
You will learn:
- Learn about major challenges marketers are facing today
- Hear how Algolia can help your organization
- See an on-demand demo of the solution in practice
Join the session here.
Speaker bio:
Martin was among the first employees at Algolia when joining over five years ago, coming from Google. He has helped scale the customer success and sales teams ever since. Today, Martin looks after Algolia’s enterprise customers focusing on the Fortune 100.
About Algolia:
Algolia provides an API platform for dynamic experiences that enable organizations to predict intent and deliver results. Algolia achieves this with an API-first approach that allows developers and business teams to surface relevant content when wanted — satisfying the demand for instant gratification — and building and optimizing online experiences that enhance online engagement, increase conversion rates, and enrich lifetime value to generate profitable growth. More than 10,000 companies, including Under Armour, Lacoste, Birchbox, Stripe, Slack, Medium and Zendesk, rely on Algolia to manage over 1.5 trillion search queries a year. Algolia is headquartered in San Francisco with offices in New York, Atlanta, Paris, London and Bucharest. To learn more, visit www.algolia.com.
The post Personalize each digital customer experience appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Thursday, August 4th, 2022
Meta has announced that they’re going to shift their focus on Reels, and their live shopping feature will be sunset on October 1.
What it means. After October 1 users will still be able to use Facebook Live to broadcast events, but you’ll no longer be able to host new or scheduled live shopping events. The feature was created two years ago as a way for creators and brands to connect with shoppers, find new buyers, and connect with viewers.
Facebook says. “As consumers’ viewing behaviors are shifting to short-form video, we are shifting our focus to Reels on Facebook and Instagram, Meta’s short-form video product,” the company said in the blog post. “If you want to reach and engage people through video, try experimenting with Reels and Reels ads on Facebook and Instagram. You can also tag products in Reels on Instagram to enable deeper discovery and consideration. If you have a shop with checkout and want to host Live Shopping events on Instagram, you can set up Live Shopping on Instagram.”
Following in TikToks footsteps. Last month TikTok announced they were abandoning plans to bring a live QVC-style shopping video feature to the US. The announcement came after a disastrous UK launch, though popular in Asia.
Read the blog post. You can read more details about the announcement on Facebook’s blog post.
Why we care. Brands and creators that used Facebook live shopping to expand their reach and promote products will have to find another way. However it seemed like live shopping served a different purpose and demographic, so swapping it for Reels doesn’t make much sense at the moment.
Since you can tag products in Reels, we suggest that brands and advertisers who use videos to promote shift their focus and cross their fingers.
The post The Facebook live shopping feature is going away appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
@rustybrick pic.twitter.com/StnsAmSqBo