Archive for the ‘seo news’ Category
Wednesday, August 21st, 2024
The sources cited in Google AI Overviews now match webpages from the top 10 Google organic search results 99.5% of the time.
This new data was shared on LinkedIn by Mark Traphagen, VP of Product Marketing and training at seoClarity, an enterprise SEO platform. The finding is based on seoClarity’s analysis of 36,000 keywords.
Why we care. This appears to be a huge change. Since the early days of Google’s Search Generative Experience (SGE), which later became AI Overviews, Google often showed sources outside the top 10 organic results. This resulted in Google showing some less-than-authoritative and trustworthy sources and content in AI Overviews.
After getting called out for giving dangerous and wrong answers, Google massively reduced the visibility of AI Overviews and promised improvements. We’ve seen lots of volatility with AI Overviews over the past three months since they officially launched.
Context. So how huge is this change? In January, the sources appearing in SGE were different from the top 10 Google organic search results an incredible 93.8% of the time. That finding came from an Authoritas analysis. From that report:
- “93.8% of generative links (in this dataset at least) came from sources outside the top-ranking organic domains. With only 4.5% of generative URLs directly matching a page 1 organic URL and only 1.6% showing a different URL from the same organic ranking domain.”
What it means. Google may now be incorporating more traditional search ranking signals as part of its custom Gemini model. As Traphagen put it:
- “AI Overview optimization is now just….Google optimization!”
- “One of the best ways to get mentioned in an AIO now is to rank highly in Google.”
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Wednesday, August 21st, 2024

Ah, 2024. Just another quiet, uneventful year.
Not?!
Between endless algorithm updates and ad type rollouts, AI Overviews rewriting SERP anatomy, Google’s content quality guidelines evolving at breakneck pace… what’s a search marketer to do?
Keep calm, and carry on!
Or, in other words, attend the SMX Master Classes, online August 21-22 (today and tomorrow!), to sharpen your skills, expand professional horizons, and meet these challenges head-on.
These live, two-day training workshops dive deep into your search marketing specialty and deliver actionable tactics you can implement immediately to move forward with confidence. Check out the complete summer 2024 lineup:

- Powering advanced SEO success with Bruce Clay explores foundational SEO concepts and best practices you can build on to execute next-level strategies, driving organic traffic and growth.
- Mastering advanced Google Ads with Brad Geddes empowers you to take a fresh look at your campaign structure, identify new areas for improvement, and implement advanced strategies for success.
- Leveraging technical SEO and AI to drive growth with Eric Enge dives head-first into technical SEO topics and tactics, including AI, Schema, Core Web Vitals, and more, that can take your organic rank to a new level.
- Crafting SEO content for today’s Google with Heather Lloyd-Martin equips you with the skills needed to create compelling content that ranks well and attracts and engages your target audience.
- Dominating Google Analytics 4 and reporting with Colleen Harris explores actionable tactics for fully utilizing GA4, Big Query, Looker Studio, and GTM – from finding data to replacing views with custom reporting.
- Designing landing pages that convert with Brian Massey teaches how to leverage the psychology of buyers to boost conversions, drive ROAS up, slash acquisition costs, and outperform the competition.
- Mastering generative AI for SEO and PPC with the SMX all-stars – including Frederick Vallaeys, Kerri Amodio, Christopher Penn, and more guest experts – unpacks the most critical aspects of this unrivaled technology you need to know to become a more efficient and competitive search marketer.
At just $299 each, the SMX Master Classes pack a ton of value:
- Soak up actionable tactics you can implement immediately to drive measurable results.
- Unlock two days of live, expert-led training – maximum learning with minimal time investment.
- Participate in live Q&A to get expert answers to your specific questions.
- 100% digital means you can tune in from anywhere – no plane ticket, hotel reservation, or travel required.
- On-demand playback is included for free – watch and rewatch for deeper learning.
- Earn a personalized certificate of completion and digital badge to beef up your resume or get reimbursed.
- Hungry for more? Purchase multiple classes to save 15% off your total registration.
Since 2022, more than 2,000 search marketers have trusted the SMX Master Classes to take their SEO, PPC, and AI skills to the next level. Now, it’s your turn. Secure your spot today!
Psst… Attend with your crew for a unique team-building experience – and score up to 20% off* with group discounts, depending on your party size. Email reg@thirddoormedia.atlassian.net to learn more!
*Discounts cannot be combined.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Wednesday, August 21st, 2024
A lot has changed over the past year while I’ve been waiting for “the best AI video generators for creators and marketers” to emerge.
The list of leading contenders got scrambled six months ago when OpenAI announced Sora, “an AI model that can create realistic and imaginative scenes from text instructions,” on Feb. 15.
Ten days later, I tried to check out Sora for myself. But OpenAI’s website told me, “At this time, we don’t have a timeline or additional details to share on Sora’s broader public availability.”
I’ve been waiting for more updates. And waiting. But waiting for Sora is starting to resemble “Waiting for Godot.” (If you haven’t seen Samuel Beckett’s play, then spoiler alert: Godot sends word that he’ll be arriving tomorrow, but he never appears.)
The long wait: Sora’s elusive public availability
I watched “OpenAI Sora’s first short film – ‘Air Head,’ created by shy kids,” when it debuted on March 26. And I assumed that Sora would become publicly available in a few months.
But it’s already August and only a limited number of visual artists, designers and filmmakers have been granted access to “gain feedback on how to advance the model to be the most helpful for creative professionals.”
In other words, I still can’t evaluate Sora for myself.
In addition, shy kids is a Toronto-based production company. It’s unclear if KaraVideo.AI, a video generator powered by Sora, deserves most of the credit for this eye-catching video. If you don’t have a creative team of humans driving the text-to-video model, then would you see similar or different results?
Exploring 7 alternative AI video generators
While waiting for Sora, I taught two online classes on influencer marketing and AI at the New Media Academy in Dubai, UAE. I showed my students “Air Head” but emphasized that AI video generators still need human creativity to produce interesting results.
To help them apply what they learned, I assigned them the task of creating a video using a free AI generator available in the Middle East and North Africa (MENA) region within two or three days.
To find the best tools, I turned to AI search engines (Perplexity, ChatGPT-4, Claude 3, Microsoft CoPilot and Google’s Gemini). Each provided a list of recommendations, with options ranging from six to eight suggestions.
Overall, my students learned about seven free AI video generators – six that I selected and one that another instructor in the program recommended. Here’s the list in alphabetical order:
1. Canva’s Magic Studio: Quick and customizable video creation
Canva’s AI video generator is part of its Magic Studio, a suite of AI-powered tools designed to help teams quickly create video from text, and then refine the content using editing tools, applying filters or removing backgrounds with a single click.
2. InVideo AI: Simple and efficient video production
InVideo AI provides pre-made templates and an AI-driven text-to-video feature. It allows you to create professional-looking videos quickly. The free plan includes watermarked videos and limited export options.
3. Kapwing: Collaborative editing with AI tools
Kapwing is a collaborative video editor that offers AI tools for video creation, such as automatic subtitling and meme generators. The free plan has some limitations, like watermarked exports and limited cloud storage.
4. Lumen5: Turning text into engaging videos
Lumen5 converts text into engaging video content. You can input your blog post, article or any text content, and it will generate a video based on it. The free plan includes basic features, though it adds a watermark.
5. Pictory: Condensing long-form content into short videos
Pictory allows you to transform long-form content, such as blogs and articles, into short, shareable videos.
It uses AI to highlight key points and create a video summary. The free version comes with some limitations but is functional for basic needs.
6. Runway ML: Experimenting with creative AI
Runway ML is a unique tool that offers a free plan with credits for using their AI features, including video generation. It’s a good choice if you want to experiment with a creative and powerful tool, but keep in mind the free tier has limitations.
7. Synthesia: AI-driven multilingual video content
Synthesia is an AI video generator that transforms text into speech in a few minutes. It includes more than 160 AI avatars that can speak your text in over 130 languages. This enables marketers to create training, how-to, and product marketing videos for global audiences.
Insights from hands-on use of AI video generators
Following my overview of these seven AI video generators, I asked my students to pick just one to use for their capstone assignment. I also disclosed that I was writing this article and allowed my students to contribute their thoughts on the option that they had used.
Dana Al Khulaifi, a student at United Arab Emirates University (UAEU) and a Data and Technical Support Manager at Dawahi AlAin, a community project, said:
- “It was easy and enjoyable to create videos with InVideo.io! My thoughts were given to the AI, which created a masterpiece out of them. I was able to produce professional-looking videos quickly because the AI handled the majority of the work.”
- “I was really pleased with the range of layouts and how simple it was to customize it. It took hardly any effort to make my videos appear fantastic. InVideo.io is an amazing resource for anyone looking to create amazing videos fast and simply.”
Three other students, who wanted to remain anonymous, shared their comments about other AI video generators that they had used:
- One student explored Synthesia for creating AI-generated videos. She was impressed by the availability of different Arabic dialects but noted that the pronunciation in Arabic was not perfect. She suggested that AI still needs human guidance for quality control, such as improving pronunciation and adding emotional expressions.
- Another student used Runway for video creation, finding the process straightforward with tools for editing, transitions and effects. She noted that while AI could automate many aspects, it still lacked the originality and emotional depth that human creativity provides. She emphasized the importance of human oversight in bringing contextual awareness and cultural sensitivity to AI-generated videos.
- A third student used Canva to create videos quickly. She noted the efficiency and speed of AI tools but highlighted the lack of emotional expression and the computer-like tone of AI-generated content. She suggested that AI tools could be used for drafting videos, which could later be refined with better AI tools or human intervention for a more polished final product.
Here is a list of comments about using AI videos from more than a dozen other students:
- “I tried to use AI tools, but the video seemed very boring and didn’t really showcase anything social.”
- “Comparing the AI video with the one I created, the AI video was less engaging.”
- “AI is great but lacks human touch, especially in terms of storytelling and video quality.”
- “The AI didn’t really match the style I wanted, and the video felt robotic.”
- “The AI video was interesting but not as detailed or creative as the one created by the human team.”
- “AI-generated content still needs human input; the video didn’t capture the creativity I was looking for.”
- “I tried to challenge the AI, but it struggled to properly depict what I had in mind, especially with cultural representation.”
- “The AI couldn’t get the hands right – it looked weird, and the voice-over was robotic.”
- “AI tools provided options and brainstorming ideas but didn’t produce a final result that was up to par.”
- “AI video was very different from what I expected, especially when it came to hands and backgrounds. It wasn’t fully accurate.”
- “AI is good for generating basic content, but it lacks the precision and personalization needed for luxury brands.”
- “The AI had issues with details like hands, and the background didn’t match the context I intended.”
- “AI videos often don’t have the same emotional connection or creative flow as those made by humans.”
- “The backgrounds created by AI often don’t fit the context I want.”
- “AI videos can create something quickly but lack in creativity and detail.”
- “It didn’t feel authentic; AI cannot replace the human touch and emotional intelligence.”
- “The hands and background in the AI video were distorted and didn’t match my original idea.”
Advantages and challenges of AI in video creation
Overall, here are the general observations made by dozens of students in the two classes:
Advantages
- Efficiency and speed: AI tools can quickly generate videos, providing a starting point or draft for content creation.
- Ease of use: Many students found AI video tools straightforward, enabling them to create videos without extensive technical knowledge.
- Versatility: Tools like Synthesia offer diverse options, such as different languages and dialects, enhancing accessibility.
Limitations and challenges
- Need for human intervention: AI-generated content often requires human oversight to ensure cultural relevance, emotional depth, and accuracy.
- Pronunciation and expression: AI-generated voices, particularly in non-English languages, may lack proper pronunciation and emotional expressiveness.
- Content authenticity: AI tools can struggle with originality and creativity, emphasizing the need for human creativity to add unique elements.
Testing the top AI video generators while waiting for Sora
While waiting for Sora, evaluating other AI video generators can still teach us some important lessons.
The most important lesson is this: “AI won’t take your job, it’s somebody using AI that will take your job.”
The economist, Richard Baldwin, was the first person to say this at the 2023 World Economic Forum’s Growth Summit, and variations of this phrase have been repeated as people discuss the potential impacts of AI.
Don’t wait for the perfect AI video generator to finally appear.
Evaluate some of the best ones that are already available to learn what they can – and can’t – do already. Taking this test-and-learn approach will enable you to evaluate Sora when it appears.
And if Sora doesn’t arrive in the foreseeable future, then you will have learned another important lesson: “Perfect is the enemy of the good.”
Either way, you are less likely to lose your job because you don’t know when or how to use AI to “generate videos up to a minute long while maintaining visual quality and adherence to the user’s prompt,” which is what Sora keeps promising to do.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Tuesday, August 20th, 2024
Many SEO professionals have been asked by managers or clients, “How long does SEO take?”
Usually, the answer is “Somewhere between 4-12 months.” In some cases, it can take as long as 24 months to see a significant return on investment.
This article discusses ways to get SEO results faster through what the late and great Hamlet Batista called “agile SEO.”
The need for speed
Businesses want returns on their marketing investment sooner rather than later, especially given ongoing supply chain issues, a looming economic downturn and increased labor costs.
Getting results faster than others gives you a competitive edge whether you do SEO in-house or as an agency partner.
Stop doing checklist SEO
One common mistake SEOs make is practicing “checklist SEO.”
This method assumes that to have a well-optimized site, you must check all the boxes in an exhaustive list of best practices and site diagnostics. It also implies that all sites need the same work, which is often untrue.
Checklist SEO is generally not a great approach to SEO. You always need to consider the varying impact and difficulty of each box you’re seeking to check off so that you can prioritize effectively.
Instead of checklist SEO, use the SEO Eisenhower grid
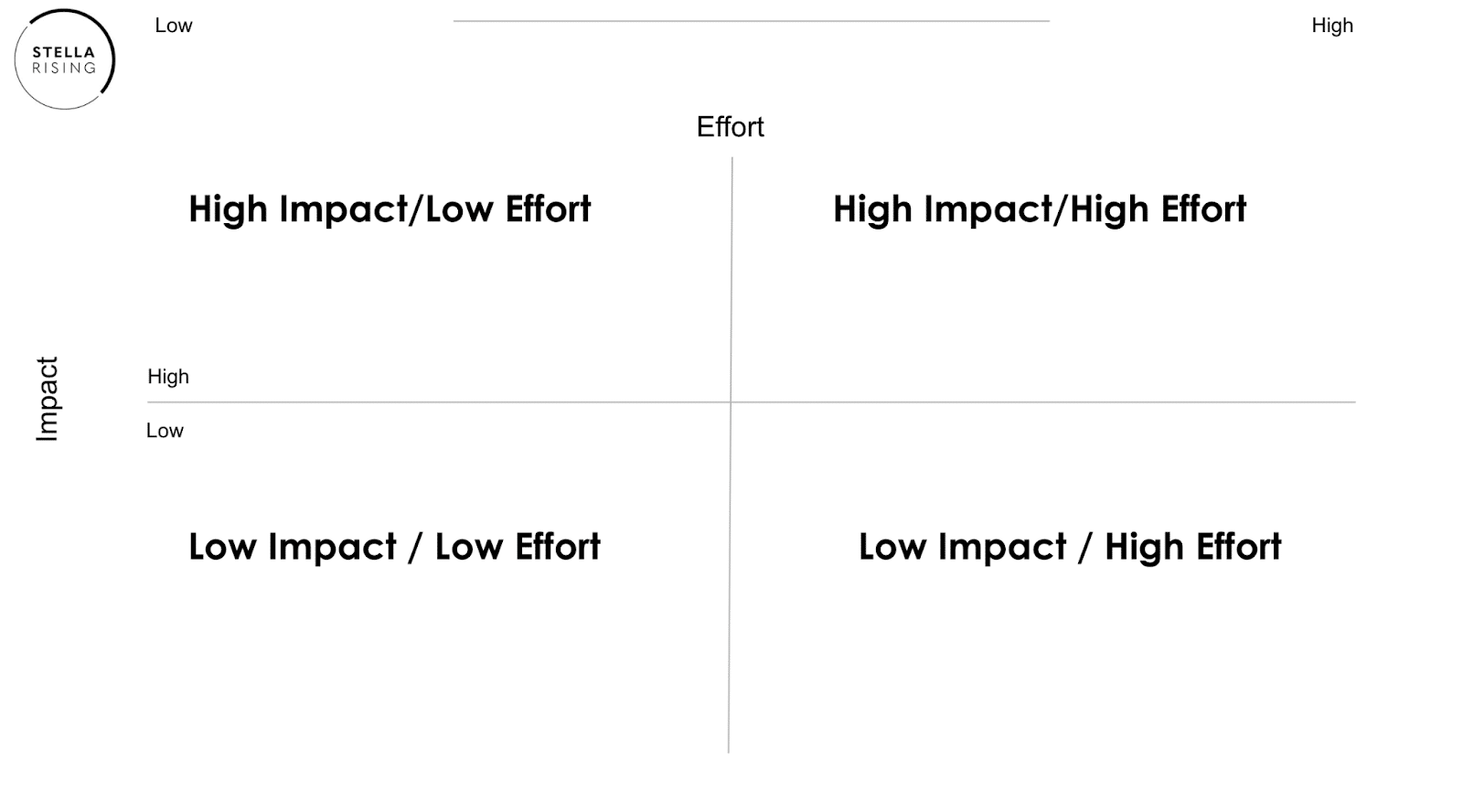
The SEO Impact Eisenhower grid is something our agency developed to prioritize client SEO tactics and efforts based on their expected difficulty and impact. Focusing on work that has proven to be impactful is critical for accelerating client growth.
Make your own SEO Impact Eisenhower grid to better understand what work you should focus on.
The grid consists of four quadrants:
- Top: Higher-impact items.
- Bottom: Lower-impact items.
- Left: Lower-effort items.
- Right: Higher-effort items.
What items would you place in the top left and right (high impact)?
What items would you place on the bottom (low impact)?
Look at the bottom and ask, do we even need to do all of these things in the first 3-6 months of this campaign?
You should plan to examine all opportunities over a year or so, but focusing on high-impact items first will help you achieve faster SEO results.
In this exercise, the aim is to identify those high-impact, lower-effort items and address those first.
Add any ideas you come up with that may be helpful, even if they are higher effort or lower impact, but consider saving them for later on in your SEO campaign.
Many SEOs start with an exhaustive technical and full site audit. While this sounds like a good plan, it may not be the best approach in most situations.
Many smaller sites built on Shopify, WordPress or other common CMS platforms have a limited number of technical issues. Their issues are often the same and can be identified and addressed without a full audit.
Sometimes the things we find in technical audits are “nice to haves” and align with best practices but are often difficult to implement and may not have a measurable impact on every website.
Technical SEO is critical for larger websites and some smaller sites. However, it’s rarely the first thing you should focus on. The exception is when there are indexing or crawl ability issues that would prevent on-page optimization or new content creation from being impactful.
Often, the more technical recommendations that require development time aren’t implemented or sit in a queue for months.
I’m not saying that technical audits are worthless. Quite the contrary.
You should absolutely do that type of work on any site you are trying to help grow. But always start with low-effort, high-impact initiatives.
For example, unless the site is not being crawled at all or is set to noindex, you’d probably get more lift out of doing keyword research, title and meta optimizations and creating new content than you would out of working on fixing a bunch of tech debt like old redirected internal links or optimizing page speed.
Why do so many SEOs start there?
The graphic below exemplifies what we have listed in our SEO Impact Grid based on the deliverables we execute at our agency. These are examples of tactics and their relative effort and impact. These are meant to serve as examples and may differ for every site or industry.
In this example, I was also thinking of what we know to be a direct ranking factor through our own experience or what Google stated is a confirmed ranking factor. Sometimes, that also means critically examining what Google has said about various factors.
For example, Core Web Vitals as a ranking signal. Google beat their drum about this like it would shake up the SERPs in a big way, but the impact has not been that large. Algo-watchers like Glenn Gabe have some interesting data on the true impact.
Now that the Page Experience Update for desktop is complete, here is some data that supports a very lightweight ranking signal. Let's start with a site that has terrible desktop CWV scores. No change in trending at all during the rollout. pic.twitter.com/5L0AhX4frc
— Glenn Gabe (@glenngabe) March 3, 2022
Implement SEO campaigns faster
One of the other places I see SEOs stumble is not creating the recommendations but implementing them on the website.
We recently published a guide to SEO implementation, which provides a framework for presenting and tracking implementations. If you have already collected your recommendations, check out that guide on implementing them.
Whether your SEO strategies are high or low effort on the impact grid, they will only be impactful if you can implement the recommendations – which requires team buy-in, developer support or a powerful SEO implementation tool.
Use agile SEO tools to implement optimizations on your own
Pioneers like Baptista and even Stephan Spencer have been using tools and tech to modify clients’ sites without needing dev support for a long time. Since those days, many tools have come to market that enable SEOs to implement SEO changes either on the edge of the cloud or in the DOM.
Tools you can use to implement SEO changes:
- SEO Scout: Uses a pixel to modify DOM. Is designed for SEO “tests” but you can leave them there and benefit from the changes.
- SearchPilot: Requires server-side setup to use service workers / CDN but delivers your changes to the server-side HTML as well as client-side.
- seoClarity: This SEO execution platform automates and accelerates SEO tasks, enabling enterprises to fix critical on-page issues, optimize content and increase agility without the need for developers, ultimately boosting organic traffic and revenue.
- RankSense: An SEO automation tool designed to implement fast and scalable SEO changes, enabling users to optimize thousands of pages effortlessly, track performance and achieve significant traffic growth in weeks without relying on developers.
Do agile technical auditing
In the world of web/app development, there are two models for how teams work: waterfall and agile. The Agile methodology is built around sprints. In SEO, we have traditionally worked more in a waterfall approach, where a bunch of recommendations are dumped on a client or dev team’s desk while we move on to other audits or optimizations.
The waterfall approach may be simpler than Agile, but it sacrifices the ability to prioritize high-impact changes. Try a more agile approach, where you constantly crawl and identify key priority fixes.
Screaming Frog’s Issues tab is a great place to source a list of prioritized recommendations. Try working through just one or two of these per sprint with your clients. Thinking back to the impact grid, technical SEO doesn’t have to be monumental if you take an Agile approach that tackles one step at a time.
At our agency, we have started working with many clients in this way: focusing on just one key task or implementation from our audits. We provide project management and implementation support for that one task, then move on to the next.
Initiative-based reporting
Once you have gotten your client or in-house team to implement something, your job is to turn into a cheerleader.
Create a mini case study of what you implemented and the impact that you saw. This helps rally teams to implement similar changes but also motivates them to implement your other recommendations.
When internal stakeholders or client teams can see the impact of your individual recommendations, something magical happens. They become excited to implement more of them. The time it takes to implement changes diminishes, and your impact grows over time.
If your compelling data-filled story doesn’t help with implementation, you can always use the implementation tools we mentioned above to get them done.
Do SEO testing
SEO testing was previously reserved for enterprise organizations like eBay, which could invest in their own custom solutions. However, with the growth of cloud-based hosting or content delivery network (CDN) solutions like CloudFlare, new solutions like RankSense and Search Pilot came to fruition. These platforms enable you to implement and test SEO changes.
SEO testing helps you get SEO results faster by showing you exactly what changes will have a positive impact vs. those that may not or may even have a damaging impact. Knowing what changes will yield positive results before using developer or team resources to implement them can help you avoid wasted time and get to results faster than stabbing in the dark.
Accelerating your SEO efforts
We all know that SEO takes time. However, that doesn’t mean you or your clients need to wait months for anything meaningful to happen.
SEO testing, tools for implementation and a strong understanding of the most impactful work are critical components of an agile SEO strategy that gets results. With the above framework for pushing on low-hanging fruit first and bigger wins later, you’ll be well-positioned to get SEO results faster than ever before.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Tuesday, August 20th, 2024
Google unleashed the much-anticipated August 2024 core update Thursday morning. Less than 24 hours later, Google Search confirmed a ranking bug, which is still ongoing.
This means Google Search is volatile right now. And many SEOs and publishers have been documenting some of what they’ve seen since the August core update rollout started.
Caveats. It’s important to note the following, which can impact your Google organic search traffic:
What we’re seeing. In short, most are seeing nothing. This is common.
But, for the first time, we are seeing some signs of life for sites that were negatively impacted by the September 2023 helpful content update.
To be clear: Those sites did not “recover” and are nowhere near where they were prior to the September 2023 helpful content update. However, some are showing surges in Google Search ranking and visibility.
- Some helpful content update victims are noticing some increases in visibility in Google Search
- No one would classify those increases as “recoveries” just yet
- Sites hit by previous core updates, like the March 2024 core update are also seeing changes, some positive and some negative
- Some sites that were never hit by a core update are also seeing changes, some positive and some negative
I documented a lot of the more detailed chatter within the SEO industry on Search Engine Roundtable.
Glenn Gabe, an SEO consultant, has been tracking a few hundred sites negatively impacted by the helpful content update. Gabe wrote that 47 of those sites are seeing some small signs of life – some surges in visibility:
- “I’m now seeing more HCU(X) sites surge. Out of the 380+ sites I’m tracking, 47 have surged since the August core update began rolling out. Note, some have low visibility, but they have spiked with the update. Others have greater visibility and are surging back nicely.”
House Fresh and Retro Dodo. These two sites received a lot of media attention following their Google ranking issues. Both reported some fluctuations – not full recoveries – in the last few days. Here are those posts:
Hey! Sorry, this update caught me while on vacation 
We are receiving visitors to some of our former top traffic pages. Here you can see yesterday VS 28 days ago: pic.twitter.com/38PBMTZYnR
— Gisele Navarro (@ichbinGisele) August 17, 2024
I can confirm that I am seeing lots of fluctuations. I'm not sure what this means yet, but my fingers are crossed. Reddit is still dominating absolutely everything.
— Brandon Saltalamacchia (@iambrandonsalt) August 16, 2024
Why we care. We’re only a few days into a month-long rollout of the August core update while a search ranking bug is ongoing, so it’s hard to know whether sites will continue to improve and what’s causing this movement. Their traffic could keep improving – but it could also get worse in the coming days.
We don’t know which way this update is headed. But we will continue to watch and report back what we find. We hope you all find success and improvements with this Google algorithm update.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Tuesday, August 20th, 2024
Google Ads officially eliminated the audience recommendations feature from the Insights tab, a move that removes automated suggestions for targeting specific audiences.
Why we care. The removal of audience recommendations from Google Ads’ Insights tab forces advertisers to take a more hands-on approach to audience targeting.
Impact on advertisers. Advertisers will need to manually identify and select audience segments, potentially increasing the time and effort required to optimize campaigns.
Reason for change. Google has not provided a specific reason for the removal, but the shift suggests a move towards more user-driven strategies and customization in audience targeting.
What it means:
- Increased Manual Effort: Advertisers will need to leverage other tools and data sources to identify and reach their target audiences effectively.
- Potential Learning Curve: Advertisers accustomed to automated recommendations may face a learning curve as they adjust to more manual processes.
What they are saying.
Search Engine Land contributor Melissa Mackey, director of paid search at Compound Growth Marketing, noted the significant disadvantage of this update on X:
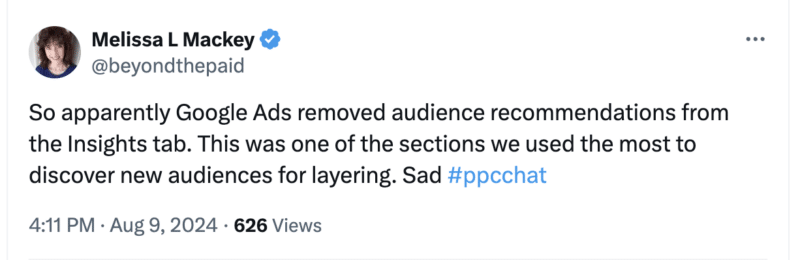
Google hasn’t yet commented on this update.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Tuesday, August 20th, 2024
Google Ads experienced a significant system glitch affecting its Shopping product serving late last month.
- This error resulted in advertisers’ products being displayed in other merchants’ ad accounts, potentially exposing sensitive business data to competitors.
- The incident has left many advertisers frustrated not only by the technical failure but also by Google’s inadequate communication in its aftermath.
Google comms. Google reached out to advertisers today about the issue and what they have done about the issue. Hana Kobzová shared the email she received:
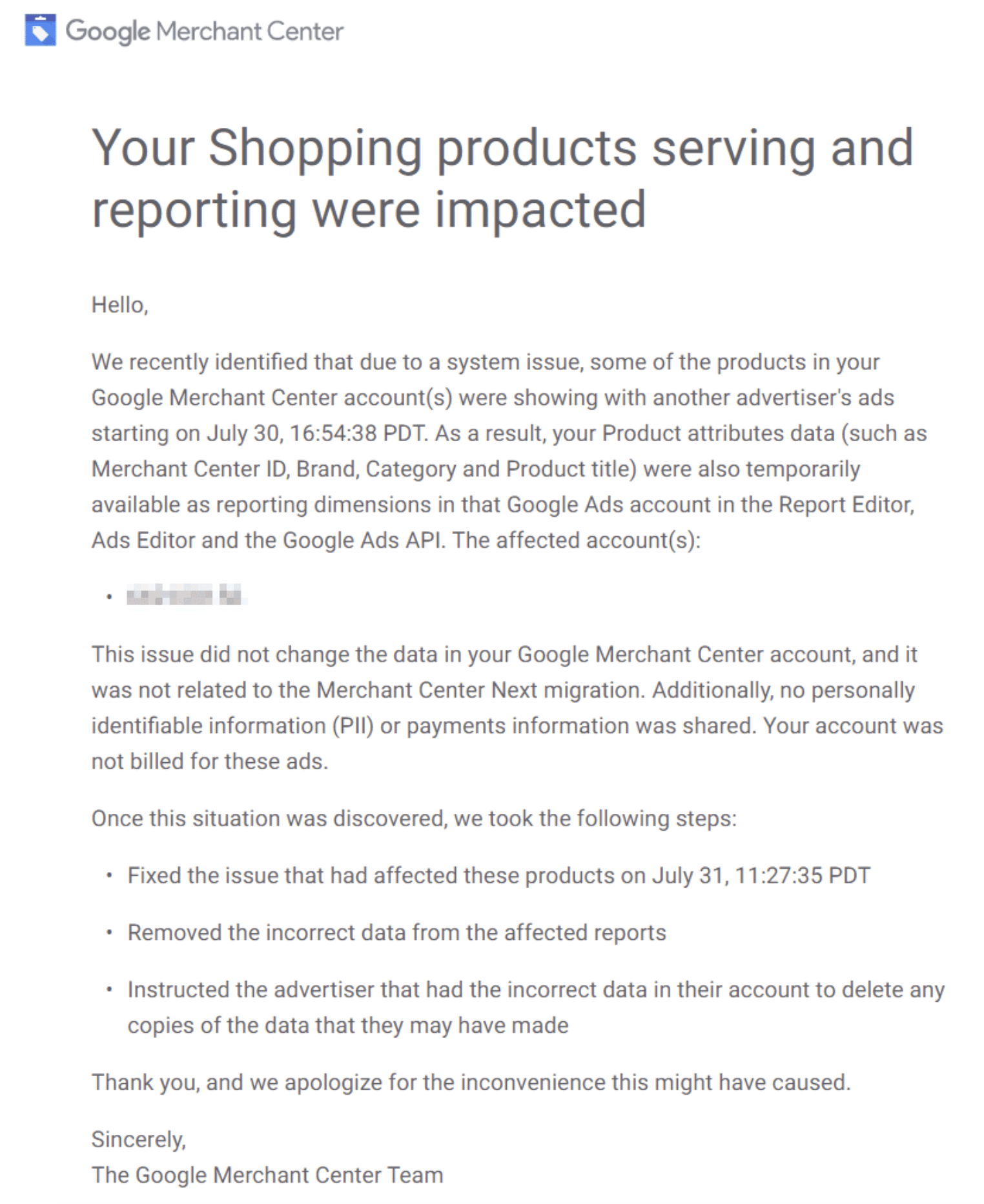
Several advertisers aren’t happy with Google’s response.
Lack of transparency and timeliness. Many industry professionals have criticized Google for its delayed and opaque response to the issue.
Mike Ryan, Head of Ecommerce and a prominent voice in the digital advertising space, pointed out the use of euphemistic language in Google’s communications, such as referring to the incident as a “system issue.”
- Ryan argues that this vague terminology lacks accountability and fails to provide advertisers with a clear explanation of what transpired.
He is also displeased with the language used:
- “I also find the phrase ‘we apologize for the inconvenience this might have caused”‘ trite and insincere.”
Melissa Mackey, Director of Paid Search, a veteran with 22 years of experience in paid search, described the glitch as “one of the craziest things” she’s ever encountered in her career, emphasizing the bizarreness of the situation and the insufficient explanation provided.
Brett Bodofsky highlighted the initial lack of formal communication when the issue first arose, noting that while Ginny Marvin (Google’s Ads Liaison) provided updates via social media, more immediate and official communications would have been beneficial.
- Bodofsky stressed that “clients want and deserve answers in an expedited fashion when issues like this arise.”
Inconsistent messaging on compensation. The handling of compensation for affected advertisers has also been a point of contention.
Chris Ridley, Head of Paid Media, pointed out the lack of a clear timeline for issuing credits, with Google repeatedly stating they would be provided in “coming weeks” for over two weeks.
Adding to the confusion, Hana Kobzová, PPC Specialist, noted inconsistencies in the emails sent to different advertisers. While some received notifications about forthcoming credits, others impacted by the issue did not receive any mention of compensation, leading to further uncertainty and frustration.
- Kobzová noted – I am confused because there was supposed to be credit issued to impacted accounts. The subject of the email I received is “Your Shopping products serving and reporting were impacted,” but it doesn’t mention anything about credit.
Dids Reeve
Calls for detailed impact reports. Several advertisers have expressed a desire for more comprehensive information about the incident’s impact on their accounts.
McKenzie Davis, Senior SEM specialist, emphasized the need for “timely and transparent communication,” suggesting that Google should provide detailed reports outlining the percentage of spend, clicks, and impressions that went toward products from other Google Merchant Center accounts. Davis also noted:
- “The vague messaging that referenced ‘a small amount of ads traffic in your Google Ads Account [that was] showing products form other Google Merchant Center accounts’ came nearly three weeks after the incident, and effectively told us nothing.”
- “In the context of recent headlines regarding shady practices by the platform, there is not enough trust in the advertiser/Google relationship for this incident to be managed as it was”
James Foster Senior Paid Media Manager, echoed this sentiment, calling for “more information about the impact this had to my ad account, the data that other advertisers were able to see, and how much ad spend went through my account that was for other businesses/my competitors.”
Security and trust concerns. Odi Caspi, Founder and Digital Marketing specialist, raised concerns about the potential breach of confidentiality, noting that the glitch exposed data that should have been protected behind passwords and two-factor authentication.
- Caspi suggested that some form of compensation should be considered, not just for financial reasons, but as an acknowledgment of Google’s responsibility in the matter.
Moving forward. As the dust settles on this unprecedented glitch, the advertising community is calling for Google to:
- Provide a clearer, more detailed explanation of what caused the issue.
- Offer transparent reports on the impact to individual advertiser accounts.
- Communicate a definitive timeline for issuing credits to affected accounts.
- Outline measures being implemented to prevent similar incidents in the future.
This incident has underscored the critical importance of clear, timely and transparent communication from ad platforms, especially in crisis situations. As Google continue to be in the limelight for all the wrong reasons, maintaining trust between platforms and advertisers will be crucial for the industry’s continued growth and success.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Friday, August 16th, 2024

Many businesses found early success with marketing automation platforms. But as marketing needs evolve, a question arises: Is it time for a change?
Join us for Stuck on Autopilot? Upgrade Your Marketing Automation where we’ll explore:
- The signs it’s time to make a change
- How to evaluate different platforms
- Strategies for a smooth migration
- A real-world example of a successful transition
Don’t let outdated technology hold you back! Sign up today to learn how to future-proof your marketing automation and unlock new opportunities.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Friday, August 16th, 2024
A new study reveals the promise and limitations of interactive TV advertising. The key findings:
- 36% stronger unaided brand recall vs. standard video ads
- 95% of viewers prefer adding products to cart over immediate purchase
- Higher CPMs: 10-15% above industry standards
Why it matters. As CTV ad spend is projected to reach $33 billion by 2025, interactive formats could become a major player in the space.
By the numbers:
- 79% aided recall for interactive ads vs. 72% for standard video ads.
- 58% stronger unaided recall when combining standard and interactive ads.
Why we care. While not yet driving direct sales, interactive CTV ads offer a wealth of benefits that can significantly impact brand awareness, consumer understanding and overall marketing effectiveness.
What they’re saying:
- “TV isn’t coming over an antenna anymore… interactive ads yield a more effective ad experience,” said Robert Aksman, BrightLine co-founder.
- “With these interactive elements, you have proof that not only is somebody watching—they’re engaging,” said Andrea Kwiateck, Goodway Group.
The big picture. Interactive CTV ads represent a shift from passive viewing to active engagement, offering new opportunities for brands to connect with audiences.
What to watch. Development of add-to-cart functionality and potential for direct purchasing through streaming accounts.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Thursday, August 15th, 2024
Google announced the upcoming sunset of Google Ads API version 15, urging developers to migrate to newer versions to maintain uninterrupted API access.
Why we care. Failure to upgrade could result in API requests failing, potentially disrupting advertising operations for businesses.
Key details:
- Sunset date: Sept. 25.
- All v15 API requests will fail after this date.
- Developers are advised to migrate to a newer version before the deadline.
How to prepare:
- Upgrade to the newest version using provided resources.
- Review release notes for changes.
- Use Google Cloud Console to identify which API versions your project is using.
Between the lines. Regular API version sunsets are part of Google’s strategy to maintain up-to-date and secure systems while encouraging developers to adopt newer features and improvements.
What’s next. Developers should prioritize migration efforts to ensure smooth transitions before the September deadline.
Bottom line. Proactive migration is crucial to avoid potential disruptions in Google Ads API functionality.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing