Archive for the ‘seo news’ Category
Friday, May 12th, 2023
“Ad blockers are not allowed on YouTube.” That’s the message YouTube may show to some users who use ad blockers. It’s part of what appears to be a small experiment the platform is running.
Why we care. In theory, this could mean more views for YouTube Ads. The question is whether those users will be at all receptive to YouTube Ads – they may simply choose to abandon watching a video or, more drastically, ditch the entire platform.
Ad blockers are not allowed on YouTube. Here’s what the message looks like, as shared via Reddit:
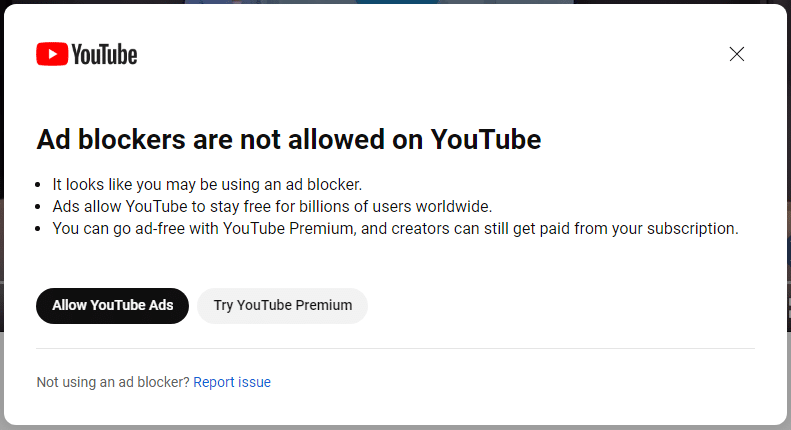
It says:
- It looks like you may be using an ad blocker.
- Ads allow YouTube to stay free for billions of users worldwide.
- You can go ad-free with YouTube Premium, and creators can still get paid from your subscription.
It then offers users two choices: Allow YouTube Ads or Try YouTube Premium.
How this message is triggered. This screen could appear whenever a user who has installed an ad blocker tries to view YouTube content.
Interesting timing? Google yesterday unveiled its new Search Generative Experience. It’s too early to know the impact SGE may have on your paid and organic search performance (not to mention Google’s ad business).
But video content and video ads may become more valuable for some brands that need visibility as a result of lost traffic or clicks in search. This would also mean YouTube wants to make sure its users are seeing as many ads as possible.
The post YouTube wants users to stop using ad blockers appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Friday, May 12th, 2023

The art of attracting and selling to customers is undergoing rapid and unprecedented transformation. To stay relevant and competitive, brands must keep up with technological advances and ever-evolving consumer behavior.
However, adapting to these changes is not straightforward, as each generation has unique needs, values and expectations that brands need to consider when developing marketing strategies.
Join marketing experts from Zeta Global as they reveal extensive research and insights into the newest consumer trends.
Register and attend “The Changing Face of Marketing: Connecting with Gen X, Millennials and Gen Z,” presented by Zeta Global.
Click here to view more Search Engine Land webinars.
The post Create tailored customer experiences for each generation appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Wednesday, May 10th, 2023
Google will roll out a new update for the helpful content system in the coming months. This update will allow Google Search to “more deeply understands content created from a personal or expert point of view,” the company wrote.
What is changing. Google said:
- “We’re also improving how we rank results in Search overall, with a greater focus on content with unique expertise and experience.”
- “We’ll roll out an update to this system that more deeply understands content created from a personal or expert point of view, allowing us to rank more of this useful information on Search.”
This update will help Google Search show more “hidden gems” within the Google search results, Google explained.
More on the helpful content update. Google’s helpful content update specifically targets “content that seems to have been primarily created for ranking well in search engines rather than to help or inform people.”
This algorithm update aims to help searchers find “high-quality content,” Google told us. Google wants to reward better and more useful content that was written for humans and to help users.
Searchers get frustrated when they land on unhelpful webpages that rank well in search because they were written for the purpose of ranking in search engines. This is the type of content you might call “search engine-first content” or “SEO content.”
Google’s helpful content algorithm aims to downgrade those types of websites while promoting more helpful websites, designed for humans, above search engines.
Google said this is an “ongoing effort to reduce low-quality content and make it easier to find content that feels authentic and useful in search.”
Why we care. This new update has not rolled out yet, but it will in the “coming months.” We will notify you when the update does launch and what to expect from this update for your sites, content and your clients. Until then, keep creating helpful content and you should (hopefully) be fine in the long run.
The post Google to update the helpful content system algorithm in the coming months appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Wednesday, May 10th, 2023
Google has removed the waitlist for Google Bard today at Google I/O, opening Bard to over 180 countries in US English, Japanese and Korean languages. Plus, Google Bard added support to show a more visual interface, Google Lens support, dark mode, and additional integrations and features, the search company announced.
This is on top of the new Google Search generative experience and Google perspectives, about this image and AI generated image labels Google announced today at I/O.
Waitlist gone. You no longer will be presented with a waitlist to sign up for Google Bard at bard.google.com. Instead, you will have access to Google Bard immediately, assuming your language and country is supported. Google Bard now supports over 180 countries in US English, Japanese and Korean.
Google said it will “gradually expand access to more languages, countries, and regions over time.”
Search and knowledge graph. Google has also showcased how Google Search and knowledge graph data can make Bard more visual and useful. Google said Bard can now provide a “helpful response along with rich visuals to give you a much better sense of what you’re exploring.”
Here is how that looks:

Google Maps. Google also has integrated Google Maps into Google Bard. It can show you a map directly inside the Google Bard answer box:

Google Lens. Google has also integrated Google Lens features directly into Bard. Google said you can upload a photo and prompt Bard to “write a funny caption about these two.” Using Google Lens, Bard will analyze the photo, and draft a few creative captions — all within seconds,” Google wrote.
Here is how that works :

Coding improvements. Google also demonstrated how Bard has improved its coding help with:
- Source citations: Starting next week, Google will make citations even more precise. If Bard brings in a block of code or cites other content, just click the annotation and Bard will underline those parts of the response and link to the source.
- “Export” Button: Google added the ability to export and run code with our partner Replit, starting with Python.
Dark mode. Google also added Dark theme on Bard, giving you the ability to easily switch Bard’s appearance between a light background with dark text to a dark background with light text. You can switch manually or it can detect your operating system’s default setting.
Google Docs & Gmail. Also with Google Docs & Gmail, Google added one-click options to export content generated by Bard, including formatting, directly into Google Docs and Gmail.
Adobe Firefly. Bard with Adobe Firefly can now help you make images. Google said Adobe Firefly, Adobe’s family of creative generative AI models, now is integrated into Google Bard to allow you to “easily and quickly turn your own creative ideas into high-quality images, which you can then edit further or add to your designs.”
Here is how that looks:

Why we care. It is amazing to see how fast these AI models and tools from both Google, Microsoft, Open AI and others are progressing.
There are practical use cases for these tools that you can use in your daily life right now and now it is open to more people to use.
The post Google Bard now can show Search and knowledge panels, maps and more while removing the waitlist appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Wednesday, May 10th, 2023
Interaction to Next Paint (INP) will replace First Input Delay (FID) as a Core Web Vitals metric starting in March 2024, Google announced at Google I/O today.
Google hinted at this change for about a year now. But now it’s official.
What is Interaction to Next Paint? INP is a metric that uses data from the Event Timing API. It assesses the responsiveness of a webpage.
An interaction that causes a page to become unresponsive results in a poor user experience, Google said. INP observes the latency of all interactions a user has made with the page and reports a single value which all (or nearly all) interactions were below.
Google provided the following example of what poor versus good responsiveness looks like:

On the left, long tasks block the accordion from opening. This causes the user to click multiple times, thinking the experience is broken. When the main thread catches up, it processes the delayed inputs, resulting in the accordion opening and closing unexpectedly.
Rankings impact. Google reiterated that Core Web Vitals do not guarantee good rankings in Google Search, wrote Martin Splitt, Developer Relations Engineer at Google.
- “Great page experience involves more than Core Web Vitals. Good stats within the Core Web Vitals report in Search Console or third-party Core Web Vitals reports don’t guarantee good rankings,” according to Splitt.
A good page experience is part of Google’s overall core ranking system. Core Web Vitals – while maybe not a direct ranking signal – is one way you can try to understand whether you’re achieving a good page experience.
However, Google uses other signals as part of its core ranking system to determine what makes a good page experience, outside of Core Web Vitals.
“There are many aspects to page experience, including some listed on this page,” Danny Sullivan, Google’s Search Liaison, told Search Engine Land. “While not all aspects may be directly used to inform ranking, they do generally align with success in search ranking and are worth attention.”
What is changing. Google will replace the FID metric with the INP metric as part of the Core Web Vitals in March 2024. Google Search Console will include INP in the Core Web Vitals report later this year so you can start measuring your new INP scores.
When INP replaces FID in March 2024, the Google Search Console report will stop showing FID metrics and use INP going forward.
 Timeline for INP change
Timeline for INP change
Why we care. A lot of SEOs have focused a lot of time on Core Web Vitals and the FID score, for better or worse. Now those same SEOs will likely shift their focus from FID to INP. Here is a guide from Google on how to optimize for INP.
Overall, I still recommend you don’t get bogged down in these metrics. Even Google says they’re only one aspect to consider when looking to improve your site’s page experience.
You know, when browsing your website, whether it is responsive and fast. You don’t always need a third-party tool to tell you that. So make excellent sites for your users but don’t obsess about these scores.
The post Google will replace FID with INP as Core Web Vitals metric appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Wednesday, May 10th, 2023

Virtual events are great for education, global outreach and strengthening your brand awareness. But what they’re especially fantastic at is lead generation.
In this webinar, you’ll get the perfect cut-and-paste formula for turning your events into lead-generating machines.
Register and attend “Maximize ROI and Lead Gen With This Virtual Events Marketing Formula,” presented by Kaltura.
Click here to view more Search Engine Land webinars.
The post Uncover the ultimate strategy to increase ROI and lead gen appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Tuesday, May 9th, 2023

In today’s uncertain economic times, it’s important to be strategic about where you spend your marketing dollars to generate the highest returns and position your business for a strong rebound.
This guide from Conductor explains why SEO is the best marketing strategy during a recession, how to play the long game with SEO, and how SEO fuels all marketing efforts. Additionally, you will learn you how to meet your customers where they already are and identify new opportunities through your search data.
By being strategic about your marketing budget and focusing on your highest-performing channels, you can thrive during both booms and busts.
Visit Digital Marketing Depot to download Marketing During a Recession: 6 Strategies to Maximize Your Marketing Budget for practical advice and real-world examples to help you get the most out of your marketing budget.
The post 6 strategies to maximize your marketing budget appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Tuesday, May 9th, 2023
Meta is threatening to remove news content from Facebook and Instagram in Canada if proposed legislation meant to establish a “fair revenue sharing” system becomes law.
Why we care. Any publishers that rely on traffic, engagement or brand awareness from Meta properties could see a significant loss if news content is blocked from being shared.
What Meta said. “We will have to end the availability of news content on Facebook and Instagram in Canada,” according to Nick Clegg, president of global affairs at Meta. Calling it “flawed legislation,” he added that this would make Canada the “first democracy to put a price on free links to web pages, which flies in the face of global norms,” Bloomberg reported.
Meta threatened to remove news from its platform last year due to U.S. legislation that would have let news companies collectively negotiate with social platforms over the terms on which their material appears on their sites. Facebook also had a separate standoff with Australia in 2021.
Online News Act. Known as Bill C-18, it “proposes a regime to regulate digital platforms that act as intermediaries in Canada’s news media ecosystem in order to enhance fairness in the Canadian digital news market,” according to the Government of Canada site.
Google already limited access to news in Canada. Earlier this year, Google tested blocking news across all Canadian publisher websites, in Google Search, Google Discover and other Google surfaces. This test was limited to less than 4% of Canadians. A Google spokesperson told Search Engine Land in Februrary that this was a “potential product response to Bill C-18.”
The post News content could vanish from Meta in Canada appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Tuesday, May 9th, 2023
Amazon advertisers may soon gain the ability to create AI-generated image and video assets to use in ad campaigns.
The company has confirmed it is now building a team to provide those tools, The Information reported. There is no estimated timeline for when this will become available.
Why we care. The ability to natively create image and video assets could help Amazon advertisers improve their listings, leading to more sales and greater ROI on the platform.
Amazon is diversifying its growing ad business. Amazon advertising accounted for $38 billion in revenue in 2022. Its biggest offering is letting merchants get greater visibility in search results. Amazon’s other advertising efforts include:
- Videos ads on Freevee, its video-streaming service, and Thursday Night Football on Prime Video.
- Audio ads on Amazon Music.
- Digital ads inside Amazon Fresh grocery stores.
Joining the AI arms race. Elsewhere, Google plans to bring generative AI to Google Ads and has already been testing a way to create RSAs using AI. And Microsoft continues testing ads in the New Bing.
The post Amazon working on AI tools to generate videos, images for advertisers appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing
Tuesday, May 9th, 2023

Customer Data Platforms (CDPs) are here to stay and have become a must-have element of the martech stack.
The latest MarTech Intelligence Report, Customer Data Platforms: A Marketer’s Guide, found that interest in CDPs increased 32% last year. Many respondents listed CDPs as a high-priority technology investment. However, according to Forrester, nearly 90% of marketers say their CDP doesn’t meet their needs.
So where do we go from here?
Register and attend “Data Down the Drain? CDPs Bring Value to an Underutilized Asset,” presented by BlueConic.
Click here to view more Search Engine Land webinars.
The post CDPs prevent your data from going down the drain appeared first on Search Engine Land.
Courtesy of Search Engine Land: News & Info About SEO, PPC, SEM, Search Engines & Search Marketing